
MOOZY is a foundation model for computational pathology that treats the patient case, not the individual slide, as the fundamental unit of representation. It encodes one or more whole-slide images (WSIs) into a single 768-dimensional case-level embedding that captures dependencies across all slides from the same patient. Trained entirely on public data with 85.77M parameters, MOOZY achieves the strongest macro weighted F1 and balanced accuracy across sixteen held-out tasks, while remaining 14x smaller than GigaPath.
- News
- Quick Start
- Method Overview
- Evaluation
- Training
- Notes from the Authors
- Acknowledgment
- Citation
- Contact
- License
- [2026/06] MOOZY was accepted to ECCV 2026!
- [2026/04] Added 164 new TCGA staging and molecular subtype tasks to the Hugging Face repo, bringing the total to 497 tasks (MOOZY was not trained on any of these newly added tasks).
- [2026/04] MOOZY is now public!
pip install moozyModel weights download automatically on first use. No access gates, no manual downloads, no HuggingFace approval.
# Encode a patient case from pre-extracted H5 feature files
moozy encode slide_1.h5 slide_2.h5 --output case_embedding.h5
# Encode directly from raw whole-slide images (requires AtlasPatch, SAM2, and OpenSlide)
moozy encode slide_1.svs slide_2.svs --output case_embedding.h5Or use the Python API:
from moozy.encoding import run_encoding
run_encoding(
slide_paths=["slide_1.h5", "slide_2.h5"],
output_path="case_embedding.h5",
)The output H5 file contains a 768-d case-level embedding ready for downstream tasks: classification, survival prediction, or retrieval.
All encoding arguments (data, runtime, raw WSI options, mixed precision) are documented in docs/encode.md.
conda create -n moozy python=3.12 -y
conda activate moozy
pip install moozyvenv
python -m venv moozy-env
source moozy-env/bin/activate
pip install moozyuv
uv venv moozy-env
source moozy-env/bin/activate
uv pip install moozyThe output is a standard H5 file. Load it with h5py:
import h5py
with h5py.File("case_embedding.h5", "r") as f:
embedding = f["features"][:] # (768,) float32 case-level embedding
# Use the embedding for downstream tasks
# e.g., as input to a linear probe, k-NN, MLP probe, or clusteringMOOZY is a two-stage pipeline that first learns slide-level representations through self-supervised learning, then aligns them with clinical meaning through multi-task supervision.
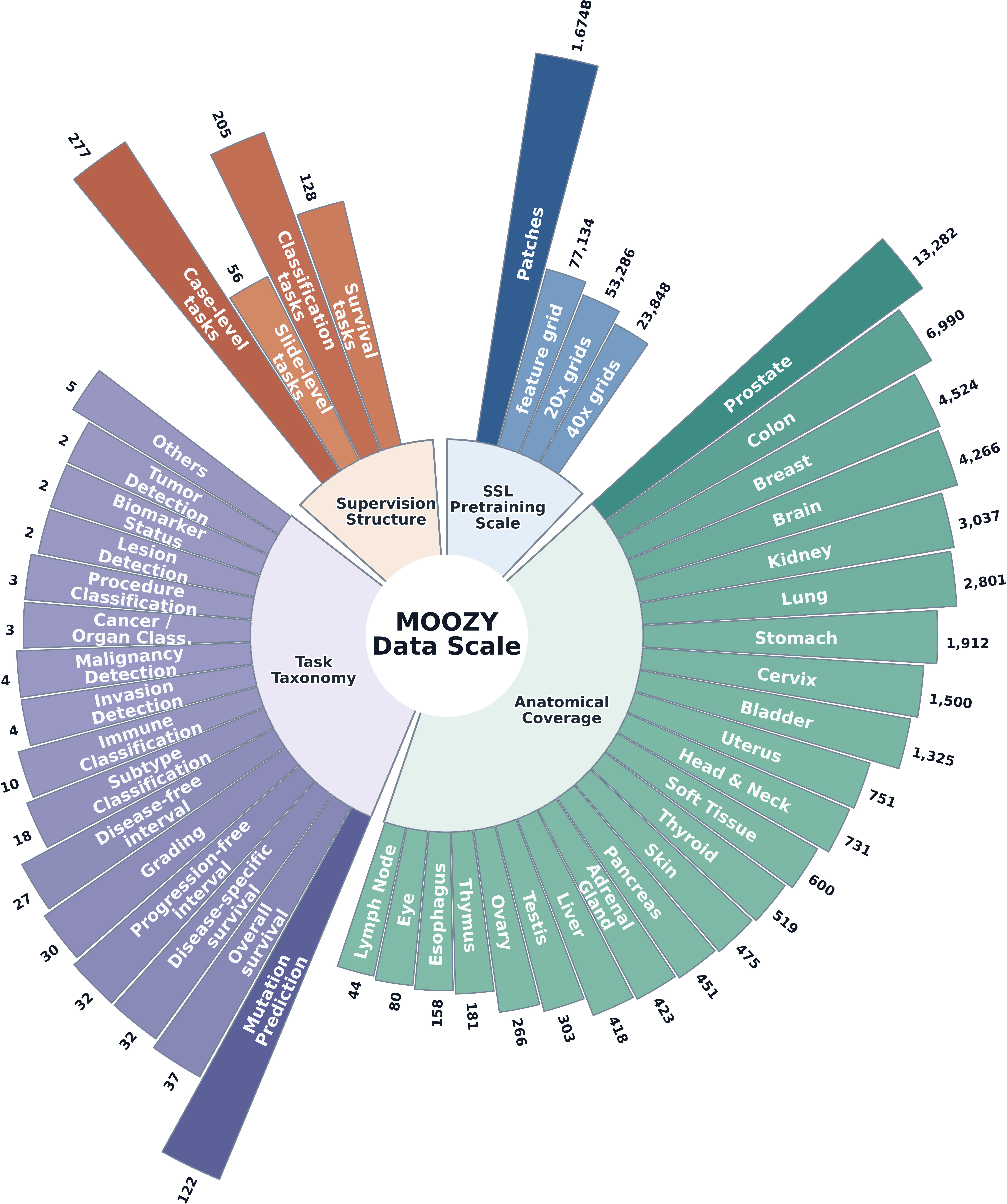
Stage 1: Self-supervised slide encoder. A vision transformer learns context-aware spatial representations from 77,134 unlabeled public histopathology slide feature grids (~1.67 billion patches across 23 anatomical sites) using masked self-distillation. No labels are used. The slide encoder captures tissue morphology, spatial context, and inter-region relationships across the whole slide.
Stage 2: Patient-aware multi-task alignment. The pretrained slide encoder is fine-tuned end-to-end with a case transformer that models dependencies across all slides from the same patient. A learnable [CASE] token aggregates per-slide embeddings into a single case-level representation. Multi-task supervision across 333 tasks (205 classification, 128 survival) from 56 public datasets provides broad clinical grounding. All task heads are discarded after training, leaving a general-purpose patient encoder.
For detailed model specifications, see the model card.
All values below are macro averages over sixteen held-out tasks using the paper's five-fold MLP-probe protocol.
| Slide encoder | Weighted F1 | Weighted ROC-AUC | Balanced Accuracy |
|---|---|---|---|
| CHIEF | 0.740 | 0.734 | 0.668 |
| GigaPath | 0.735 | 0.706 | 0.649 |
| PRISM | 0.738 | 0.707 | 0.656 |
| Madeleine | 0.751 | 0.719 | 0.671 |
| TITAN | 0.758 | 0.768 | 0.683 |
| MOOZY | 0.769 | 0.763 | 0.702 |
Against patch encoders paired with MILs (MeanMIL, ABMIL, CLAM, DSMIL, and TransMIL), MOOZY exceeds the strongest macro MIL baseline, CONCH v1.5, by 0.029 weighted F1, 0.043 weighted ROC-AUC, and 0.041 balanced accuracy.
Both training stages are fully open-source and use public data. All training arguments (data, model, optimization, checkpointing, logging, runtime) are documented in the Stage 1 and Stage 2 training docs.
For local multi-GPU training, use the launch scripts in scripts/:
# Stage 1: Self-supervised pretraining
GPU_IDS=0,1,2,3,4,5,6,7 bash scripts/train_stage1.sh
# Stage 2: Multi-task alignment
GPU_IDS=0,1,2,3,4,5,6,7 bash scripts/train_stage2.shSLURM job templates are provided in slurm/ for cluster environments:
| Script | Description |
|---|---|
slurm/single_gpu.sh |
Single-GPU training |
slurm/multi_gpu.sh |
Multi-GPU training on one node |
slurm/multi_node.sh |
Multi-node distributed training |
slurm/inference.sh |
Patient encoding |
A few readers have asked us why the main tables in the paper use a non-linear (MLP) probe rather than the more conventional linear probe. We wanted to share the reasoning here.
Slide-encoder embeddings are not guaranteed to be linearly separable. Some encoders (e.g. contrastive or aligned multimodal models) are explicitly trained to structure features along linear axes, while others organize information through higher-order interactions that a linear classifier cannot access. A linear probe rewards the former and can underrepresent the latter even when both carry the same useful information. We chose the MLP probe as the primary benchmark because it treats every encoder symmetrically. The classifier is free to use whichever structure is present in the features, without requiring it to be linearly separable. In pathology, clinically relevant phenotypes depend on nonlinear mixtures of cellular morphology and its spatial context, so a linear head on top of frozen slide features is expected to leave real signal unread. Linear-probe results still matter, since they are a more conservative measure of how features transfer to downstream pipelines that use a simple logistic-regression head, so we report both.
The full linear-probe version of the slide-encoder comparison (L2-regularized multinomial logistic regression on the same frozen features) is reported in the appendix of our paper, alongside the per-task breakdowns. MOOZY's numbers drop when the classifier is swapped from an MLP head to a linear head, but that is true of every slide encoder we evaluated, not just MOOZY. Averaged across all six encoders (CHIEF, GigaPath, PRISM, Madeleine, TITAN, and MOOZY), the macro-average decrease from MLP to linear is approximately 0.087 weighted F1, 0.016 weighted ROC-AUC, and 0.076 balanced accuracy, based on the reported values. The smaller ROC-AUC decrease indicates that linear probes preserve ranking more than class decision boundaries.
The same linear-vs-MLP question can also be asked against the patch-encoder plus trained-MIL baselines. In the table below, each non-MOOZY row pairs a frozen patch encoder with a task-specific MIL aggregator trained from scratch (MeanMIL, ABMIL, CLAM, DSMIL, TransMIL) and averages across the five architectures. The Backbone row uses the same ViT-S/8 Lunit DINOv2 patch encoder that MOOZY itself uses internally (Kang et al. 2023), so this row isolates what MOOZY's slide and case encoder add on top of the shared patch features.
Linear classifier on MOOZY vs. trained MIL aggregators (macro average over 5 MIL architectures).
| Patch encoder | Weighted F1 | Weighted ROC-AUC | Balanced Accuracy |
|---|---|---|---|
| Backbone (MOOZY's patch encoder) | 0.723 | 0.707 | 0.643 |
| UNI v2 | 0.722 | 0.707 | 0.637 |
| Phikon v2 | 0.714 | 0.697 | 0.626 |
| CONCH v1.5 | 0.740 | 0.720 | 0.661 |
| MUSK | 0.720 | 0.695 | 0.637 |
| MOOZY (linear probe) | ≈0.671 | ≈0.743 | ≈0.623 |
Macro averages across sixteen held-out tasks, computed from the task-level values reported in the appendix. Non-MOOZY rows use frozen patch features with a trained MIL aggregator, averaged over five architectures. MOOZY uses a linear classifier on its frozen case embedding.
Under the linear probe, MOOZY retains the strongest ROC-AUC (approximately +0.023 over CONCH v1.5) but trails it by approximately 0.069 weighted F1 and 0.038 balanced accuracy. Relative to the shared Backbone features, full MOOZY gains 0.046 F1, 0.056 ROC-AUC, and 0.059 balanced accuracy under the primary MLP protocol. Comparing MOOZY's linear probe with the Backbone MIL macro gives approximately -0.052, +0.036, and -0.020, showing that part of the learned case-level signal is non-linearly decodable.
A related question we have heard is how much of MOOZY's gain comes from Stage 1 (the self-supervised slide encoder) versus Stage 2 (the patient-aware multi-task alignment). We find that Stage 1 on its own is already competitive with fully-trained slide encoder baselines, while being one of the smallest models in the comparison and using no paired text, no cross-stain supervision, and no slide-level labels.
Stage 1 only (MOOZY SSL) vs. other slide encoders (macro average over sixteen held-out tasks, MLP probe).
| Slide encoder | Training signal | Params (total) | Weighted F1 | Weighted ROC-AUC | Balanced Accuracy |
|---|---|---|---|---|---|
| CHIEF | Vision SSL + weakly-supervised slide labels | 28.71M | 0.740 | 0.734 | 0.668 |
| GigaPath | Vision SSL (masked autoencoder) | 1.22B | 0.735 | 0.706 | 0.649 |
| PRISM | Vision-language (paired clinical text) | 742.06M | 0.738 | 0.707 | 0.656 |
| Madeleine | Multimodal (cross-stain supervision) | 400.23M | 0.751 | 0.719 | 0.671 |
| TITAN | Vision-language (paired clinical captions) | 354.65M | 0.758 | 0.768 | 0.683 |
| MOOZY SSL (Stage 1) | Vision SSL (masked self-distillation) | 64.50M | 0.743 | 0.715 | 0.662 |
Macro averages across sixteen held-out tasks. MOOZY SSL refers to the slide encoder after Stage 1 only, with no Stage 2 multi-task alignment and no case aggregator. Total params include the 42.83M slide encoder and frozen 21.67M ViT-S/8 Lunit DINO patch encoder.
Stage 1 alone is competitive but is not the strongest encoder. It exceeds GigaPath by 0.008 weighted F1, 0.009 weighted ROC-AUC, and 0.013 balanced accuracy using about 5% of its parameters. It also slightly exceeds PRISM across the three macro metrics, while Madeleine and TITAN remain stronger. GigaPath puts almost all of its parameters into a 1.1B-parameter tile encoder, whereas MOOZY keeps a compact 21.67M ViT-S/8 patch encoder frozen and routes the remaining budget into slide-level modeling. This is the most direct evidence we have for a hypothesis we raise in the paper, that slide- and context-level modeling, not patch-level capacity, is the real bottleneck in computational pathology. Full MOOZY improves over Stage 1 by 3.50% weighted F1, 6.64% ROC-AUC, and 5.98% balanced accuracy.
One thing we kept bumping into during Stage 2 is just how hard it is to make different heterogeneous tasks converge at the same time. Our current recipe averages losses equally across the active tasks in each batch, which is the simplest thing that works but treats a tiny lymph-node survival task with a handful of cases and a pan-cancer classification task orders of magnitude larger as if they carried the same weight, and in practice they do not. Tasks differ wildly in sample count, in difficulty, in whether the output is categorical or a discrete-hazard distribution over censored event times, and hence in the natural scale of their loss. Our sense is that different tasks pull the shared backbone in different directions, so their gradient updates partially cancel each other out under equal averaging, and no single training checkpoint ends up being the best one for every task at the same time. We see this as one of the clearest open problems in MOOZY, and investigating task sampling and loss weighting strategies feels like a promising future research direction.
A question we keep getting about MOOZY is whether the recipe would benefit from further scaling of data, parameters, or supervision. Our honest answer is that scaling laws in computational pathology are unclear at multiple levels of the stack, and MOOZY does not answer that question.
At the tile encoder level, OpenMidnight's analysis notes that average performance is not cleanly correlated with compute or dataset size, and they flag two contributing factors. One is that training recipe and data quality dominate raw scale past a fairly modest data threshold. The other, which we think is worth highlighting, is that the benchmarks themselves may be part of the problem. If the benchmarks themselves cannot reliably separate strong models from weak ones, "scaling does not help" becomes hard to distinguish from "scaling helps but the benchmark cannot show it." Our reading, which we also raise in the paper, is that tile-level representations likely hit a performance ceiling well before the thresholds observed in general vision, because H&E tissue occupies a much narrower visual space than natural images. A bounded set of morphological primitives (cell types, glandular architectures, stromal patterns) rendered in a fairly narrow color palette seems to be enough for a compact public-only tile encoder to capture most of the structure that matters for downstream tasks. The benchmark caveat and the saturation hypothesis are not mutually exclusive, and both are probably part of why scaling laws look unresolved here.
The same open question applies to slide encoders, and here we have even less evidence. To our knowledge there is no public study that systematically varies slide-encoder depth, width, or pretraining corpus size on a "proper" benchmark. Most comparisons in the literature conflate encoder capacity with differences in training signal (vision-only SSL, paired clinical text, cross-stain supervision, weak slide labels, and so on), so we cannot cleanly say whether a bigger slide encoder trained on more slides would beat a smaller one with a better training recipe. Our own Stage 1 result, where a 64.50M-parameter pipeline (slide encoder plus frozen patch encoder) exceeds GigaPath across the three macro metrics, is consistent with saturation at this level too, but it is one data point, not a scaling curve. Whether adding an order of magnitude more public slides or doubling the encoder depth would meaningfully move performance is simply not known to us. The same is true at the patient level where no scaling curves exist at all.
A specific scaling dimension that we did not study in this work is the number of tasks in Stage 2. MOOZY trains jointly on 333 tasks from 56 public datasets, but we never ran a controlled sweep over what happens when Stage 2 uses 30 tasks, 100 tasks, or 500. Our intuition is that the curve is non-trivial. A few dozen well-chosen tasks probably capture most of the downstream transfer benefit, and past some point additional tasks likely contribute mostly noise if not results in worse performance, but we have not verified this, and the answer almost certainly interacts with the loss weighting discussion in the previous subsection. We flag this as one of other open questions about MOOZY, and one we would like to study if we revisit MOOZY.
Most modern slide encoders (PRISM, TITAN, COBRA, CHIEF, Madeleine, GigaPath, and MOOZY itself) compress an entire whole-slide image, or in MOOZY's case a whole patient case, into a single fixed-length vector. The idea is elegant, and for a lot of tasks it works. A few hundred dimensions are enough to carry linearly or non-linearly decodable signal for tumor subtyping, grading, mutation status, and prognosis. Our point is simply that this abstraction works for a narrower range of downstream tasks than the field has been acting like it does, and the clearest hint already comes from PRISM and TITAN themselves. Both models build a multi-latent internal representation specifically for their text decoders, which is effectively an admission that one vector is not enough when the downstream task actually needs compositional reasoning.
The issue is that a single vector is, by construction, an information bottleneck. It has to summarize every diagnostically relevant finding in the specimen into one point in embedding space. That is well matched to tasks whose output is categorical or scalar (classification, survival, retrieval, mutation prediction), and it is exactly where slide encoders shine. It is, in our view, fundamentally misaligned with dense, compositional tasks whose output is itself multi-part. Pathology report generation is the clearest example. A real report reads something like "a 14 mm invasive ductal carcinoma, Nottingham grade 2, with associated ductal carcinoma in situ, surgical margins clear, one of three sentinel lymph nodes positive for metastatic carcinoma." Each clause references a distinct region, each region lives at a different spatial scale, and the regions can be on different slides entirely. A single CLS vector has to either superimpose these findings, which erases specificity, or pick a winner, which erases completeness. Neither mode supports faithful, grounded reporting. What we would like to see instead is a slide or patient encoder that emits representations at multiple levels of granularity at the same time. Instead of one vector per patient, the model would expose a small stack of vectors, some capturing local regions of tissue, some capturing an entire slide, and one or more capturing the full case. Downstream tasks then read whichever levels they need, so a classification head can pool all of them into a single prediction while a report generation head can read them as a set and describe each level separately.
MOOZY itself is a single-vector model, and the results in this repository should be read accordingly. They are evidence of transferability on scalar endpoints like classification, survival, and retrieval, not a claim that whole-patient understanding has been solved. Our contribution is orthogonal to the multi-vector question. We argue for patient-level rather than slide-level aggregation, and the compression bottleneck is still there. The natural next step is to relax the single [CASE] token into a small bank of learned patient latents, and to find a training signal that pushes each latent to represent the slide or patient at a different scale.
We want to flag a methodological caveat in how we evaluate. Across the sixteen-task benchmark, some evaluations use additional cohorts while others test held-out clinical readouts in datasets represented elsewhere during training. The benchmark therefore mixes cohort-level and task-family transfer and should not be interpreted as a pure out-of-distribution generalization. Future evaluation should report these axes separately: (i) cohorts absent from both stages, and (ii) task families absent from Stage 2 within otherwise familiar cohorts.
The two axes test different things and both matter. Cohort generalization is the more clinically meaningful direction. Task-family generalization is a cleaner probe of representation quality, where with cohort shift held roughly fixed, it isolates whether the learned features carry signal beyond the specific clinical readouts that Stage 2 supervised against. Without reporting along both axes, headline numbers can look like generalization but be partly a function of evaluation-cohort overlap with pretraining.
Our compute budget did not allow a broad sweep over the second-stage configuration space, including but not limited to learning-rate schedules, warmup, weight decay, task weighting, and slide-encoder freezing. The reported configuration reflects a constrained search and should not be interpreted as globally optimal. What we ended up reporting is the configuration that performed best on eight held-out tasks out of sixteen, which is a perfectly normal thing to do, but it inherits the issue we raise in On Benchmarking. If the held-out tasks themselves draw from cohorts that were partially visible during pretraining, then selecting hyperparameters against those tasks can quietly tune the model to that same overlapping evaluation universe rather than to a genuinely held-out signal. We strongly encourage the community to run controlled Stage 2 hyperparameter ablations themselves, ideally with model selection done on the two evaluation axes from the previous subsection rather than on a task suite that may share cohort distribution with pretraining.
We call the second-stage module that turns slide tokens into a [CASE] embedding the "case aggregator", and that name is convenient but, we think, slightly misleading. The clearest piece of evidence comes from Residual Cancer Burden task, every patient in RCB contributes exactly one slide, so the slides-per-patient ratio is 1.0. There is nothing to aggregate, and yet, in our case-aggregator ablation, adding the case aggregator helped in that task. Our reading is that the case transformer is best thought of as a task-distribution projection head, not just a pooling operation. During Stage 2 it is trained jointly with the slide encoder over supervised tasks, and the [CASE] query learns to attend over slide tokens and re-project them into a subspace that is shaped by the distribution of those tasks. When the case has multiple slides, the projection happens to also pool across them, which is the role the name "aggregator" captures. When the case has a single slide, the same module still runs, and it still applies that learned re-projection. Mechanically, it is transforming a slide representation that was optimized largely by Stage 1 SSL, into a representation that lives in the joint geometry of all the case-level pathology tasks the model was aligned to. The downstream probe then sees a more linearly (or shallow-MLP) decodable signal. The implication which we want to flag explicitly, is that "case aggregator" undersells what this module does and over-constrains how the community might think about it. It is a learned, case-level, task-aware projection that also aggregates when there is more than one slide. We think the more accurate framing is closer to a case-level adapter that closes the gap between a generic slide representation and the distribution of clinical readouts the model was supervised against.
It is worth mentioning that the case aggregator raises macro weighted F1 from 0.749 to 0.769, ROC-AUC from 0.737 to 0.763, and balanced accuracy from 0.682 to 0.702. It improves F1 on 14 of 16 tasks, ROC-AUC on 12, and balanced accuracy on 13. 11 tasks improve across all three metrics.
This work was supported by NSERC-DG RGPIN-2022-05378 [M.S.H], Amazon Research Award [M.S.H], and Gina Cody RIF [M.S.H], FRQNT scholarship [Y.K]. Computational resources were provided in part by Calcul Québec and the Digital Research Alliance of Canada.
If you find MOOZY useful, please cite:
@inproceedings{kotp2026moozypatientfirstfoundationmodel,
title={MOOZY: A Patient-First Foundation Model for Computational Pathology},
author={Kotp, Yousef and Trinh, Vincent Quoc-Huy and Pal, Christopher and Hosseini, Mahdi S.},
booktitle={European Conference on Computer Vision (ECCV)},
year={2026},
url={https://arxiv.org/abs/2603.27048},
}For questions, bug reports, or just to say hi, my inbox is open at yousefkotp@outlook.com. I am a human who reads every email, even the ones that start with "I know you're probably busy, but...". Feel free to reach out about anything related to MOOZY, computational pathology, or just to chat about deep learning and its applications in medicine. I also welcome feedback on the codebase and any suggestions for improvement.
This project is licensed under CC BY-NC-SA 4.0.