diff --git a/docs-mintlify/admin/account-billing/pricing.mdx b/docs-mintlify/admin/account-billing/pricing.mdx
index ea7ce05ed266c..8cb0a9ef7cf62 100644
--- a/docs-mintlify/admin/account-billing/pricing.mdx
+++ b/docs-mintlify/admin/account-billing/pricing.mdx
@@ -40,7 +40,7 @@ commit payment plan. [Contact us][link-contact-us] to learn more.
**Free product tier is designed for development and testing purposes.** It is not
intended for production use.
-It offers up to two [Development Instances][ref-cloud-deployment-dev-instance].
+It offers up to two [Shared deployments][ref-cloud-deployment-dev-instance].
You can review its [support terms][ref-free-tier-support] and [limits][ref-cloud-limits].
@@ -48,7 +48,7 @@ You can review its [support terms][ref-free-tier-support] and [limits][ref-cloud
**Starter product tier targets low-scale production that is not business-critical.**
-It offers a [Production Cluster][ref-cloud-deployment-prod-cluster], the ability
+It offers a [Dedicated deployment][ref-cloud-deployment-prod-cluster], the ability
to use third-party packages from the npm registry, AWS and GCP support in select
regions, pre-aggregations of up to 150GB in size, auto-suspend controls, and
[Semantic Layer Sync][ref-sls] with a single BI tool (such as Preset or Metabase).
@@ -61,7 +61,7 @@ terms][ref-starter-tier-support], and [limits][ref-cloud-limits].
**Premium product tier is designed for basic small-scale production deployments.**
It offers everything in the [Starter product tier](#starter) as well as enabling
-the use of [Production Multi-Clusters][ref-cloud-deployment-prod-multicluster],
+the use of [Multi-cluster deployments][ref-cloud-deployment-prod-multicluster],
support for [custom domains][ref-cloud-custom-domains], AWS and GCP support
in all regions. Cube Cloud provides a 99.95% uptime SLA for this product tier.
@@ -90,8 +90,8 @@ of deployments within a Cube Cloud account. The consumption is measured in 5-min
| Resource type | CCUs per hour | Notes |
| --- | :---: | --- |
-| [Production Cluster][ref-production-cluster] | 4..8 | Depends on a [chosen tier](#deployment-tiers) |
-| [Development Instance][ref-development-instance] | 1..2 | Depends on a [chosen tier](#deployment-tiers) |
+| [Dedicated deployment][ref-production-cluster] | 4..8 | Depends on a [chosen tier](#deployment-tiers) |
+| [Shared deployment][ref-development-instance] | 1..2 | Depends on a [chosen tier](#deployment-tiers) |
| Cube API Instance | 1..2 | Depends on a [chosen tier](#deployment-tiers) |
| Cube Store Worker | 1..2 | Depends on a [chosen tier](#cube-store-worker-tiers) |
| [Semantic Catalog][ref-semantic-catalog] | 2..4 | Depends on a [chosen tier](#semantic-catalog-tiers) |
@@ -114,14 +114,14 @@ The following resource types incur cost and apply to the _whole Cube Cloud accou
### Deployment tiers
-[Production clusters][ref-production-cluster] (including individual API instances)
-and [development instances][ref-development-instance] are involved in serving
+[Dedicated deployments][ref-production-cluster] (including individual API instances)
+and [Shared deployments][ref-development-instance] are involved in serving
requests through [APIs & integrations][ref-apis] under the following tiers:
| Tier | CCUs per hour | CPU and memory | Dependent features |
| ---- | :--- | --- | --- |
-| S | 4 — _for Production Cluster_
1 — _for Development Instance_
1 — _for Cube API Instance_ | 100% | — |
-| M | 8 — _for Production Cluster_
2 — _for Development Instance_
2 — _for Cube API Instance_ | 200% | [DAX API][ref-dax-api]|
+| S | 4 — _for Dedicated deployment_
1 — _for Shared deployment_
1 — _for Cube API Instance_ | 100% | — |
+| M | 8 — _for Dedicated deployment_
2 — _for Shared deployment_
2 — _for Cube API Instance_ | 200% | [DAX API][ref-dax-api]|
You can upgrade to a chosen tier in the
**Settings** of your deployment.
@@ -205,9 +205,9 @@ increase it to continue using AI features.
## Total cost examples
The following examples provide insight into the total cost to use Cube Cloud:
-- [Small-scale deployment](#small-scale-deployment) (production cluster, Premium product tier, S deployment tier).
-- [Medium-scale deployment](#medium-scale-deployment) (production cluster with auto-scaling, Enterprise product tier, S deployment tier).
-- [Large-scale deployment](#large-scale-deployment) (production multi-cluster with dedicated infrastructure, Enterprise product tier, M deployment tier).
+- [Small-scale deployment](#small-scale-deployment) (Dedicated deployment, Premium product tier, S deployment tier).
+- [Medium-scale deployment](#medium-scale-deployment) (Dedicated deployment with auto-scaling, Enterprise product tier, S deployment tier).
+- [Large-scale deployment](#large-scale-deployment) (Multi-cluster deployment with dedicated infrastructure, Enterprise product tier, M deployment tier).
### Small-scale deployment
@@ -216,23 +216,23 @@ a couple of teams in Eastern and Pacific time zones.
This organization:
* Uses the Premium product tier of Cube Cloud.
-* Runs a single Production Cluster (S tier) that is active 24/7 but never has to auto-scale
+* Runs a single Dedicated deployment (S tier) that is active 24/7 but never has to auto-scale
its API instances because the usage is spread evenly with no bursts.
* Operates on a small volume of data that requires the usage of just 2 Cube Store
Workers to run queries and refresh pre-aggregations mostly during working hours,
being active approximately 50% of the time.
-* Updates its data model infrequently and without using a dedicated Development
-Instance for testing purposes, with 2 data engineers spending just 1 hour a day each,
-in the development mode of the Production Cluster.
-
-| Resource | Usage per month | CCU per month |
-| ----------------------------------------------- | --------------------------------------------------------- | --------------------------------------------------- |
-| Production Cluster | 1 Production Cluster ×
24 hours per day ×
30 days | 720 hours ×
4 CCUs per hour =
**2880 CCUs** |
-| Additional Cube API Instance | — | — |
-| Cube Store Worker | 2 Cube Store Workers ×
12 hours per day ×
30 days | 720 hours ×
1 CCU per hour =
**720 CCUs** |
-| Development Instance | — | — |
-| Development Instance
(for development mode) | 2 users ×
1 hour per day ×
30 days | 60 hours ×
1 CCU per hour =
**60 CCUs** |
-| **Total** | | **3660 CCUs** |
+* Updates its data model infrequently and without using a dedicated Shared
+deployment for testing purposes, with 2 data engineers spending just 1 hour a day each,
+in the development mode of the Dedicated deployment.
+
+| Resource | Usage per month | CCU per month |
+| ---------------------------------------------- | ------------------------------------------------------------ | --------------------------------------------------- |
+| Dedicated deployment | 1 Dedicated deployment ×
24 hours per day ×
30 days | 720 hours ×
4 CCUs per hour =
**2880 CCUs** |
+| Additional Cube API Instance | — | — |
+| Cube Store Worker | 2 Cube Store Workers ×
12 hours per day ×
30 days | 720 hours ×
1 CCU per hour =
**720 CCUs** |
+| Shared deployment | — | — |
+| Shared deployment
(for development mode) | 2 users ×
1 hour per day ×
30 days | 60 hours ×
1 CCU per hour =
**60 CCUs** |
+| **Total** | | **3660 CCUs** |
### Medium-scale deployment
@@ -242,23 +242,23 @@ analytics in its SaaS platform that caters to a vast worldwide customer base.
This organization:
* Uses the Enterprise product tier of Cube Cloud.
-* Runs two Production Clusters (S tier) that are active 24/7 and auto-scale up to 8 API instances
+* Runs two Dedicated deployments (S tier) that are active 24/7 and auto-scale up to 8 API instances
during a peak hour every day.
* Operates on a moderate volume of data that requires the usage of 4 Cube Store
-Workers by both Production Clusters to run queries and refresh pre-aggregations 24/7,
+Workers by both Dedicated deployments to run queries and refresh pre-aggregations 24/7,
being active approximately 50% of the time.
-* Uses a dedicated Development Instance (S tier) for testing purposes that is active 12 hours a day.
+* Uses a dedicated Shared deployment (S tier) for testing purposes that is active 12 hours a day.
* Has a team of 5 data engineers who frequently update the data model, with each data engineer
-spending about 4 hours a day in the development mode of the dedicated Development Instance.
+spending about 4 hours a day in the development mode of the dedicated Shared deployment.
-| Resource | Usage per month | CCU per month |
-| ----------------------------------------------- | ------------------------------------------------------------------------------------- | ---------------------------------------------------- |
-| Production Cluster | 2 Production Clusters ×
24 hours per day ×
30 days | 1440 hours ×
4 CCUs per hour =
**5760 CCUs** |
-| Additional Cube API Instance | 2 Production Clusters ×
(8 – 2) API Instances ×
1 hour per day ×
30 days | 360 hours ×
1 CCU per hour =
**360 CCUs** |
-| Cube Store Worker | 2 Production Clusters ×
4 Cube Store Workers ×
12 hours per day ×
30 days | 2880 hours ×
1 CCU per hour =
**2880 CCUs** |
-| Development Instance | 1 Development Instance ×
12 hours per day ×
30 days | 360 hours ×
1 CCU per hour =
**360 CCUs** |
-| Development Instance
(for development mode) | 5 users ×
4 hours per day ×
30 days | 600 hours ×
1 CCU per hour =
**600 CCUs** |
-| **Total** | | **9960 CCUs** |
+| Resource | Usage per month | CCU per month |
+| ---------------------------------------------- | ---------------------------------------------------------------------------------------- | ---------------------------------------------------- |
+| Dedicated deployment | 2 Dedicated deployments ×
24 hours per day ×
30 days | 1440 hours ×
4 CCUs per hour =
**5760 CCUs** |
+| Additional Cube API Instance | 2 Dedicated deployments ×
(8 – 2) API Instances ×
1 hour per day ×
30 days | 360 hours ×
1 CCU per hour =
**360 CCUs** |
+| Cube Store Worker | 2 Dedicated deployments ×
4 Cube Store Workers ×
12 hours per day ×
30 days | 2880 hours ×
1 CCU per hour =
**2880 CCUs** |
+| Shared deployment | 1 Shared deployment ×
12 hours per day ×
30 days | 360 hours ×
1 CCU per hour =
**360 CCUs** |
+| Shared deployment
(for development mode) | 5 users ×
4 hours per day ×
30 days | 600 hours ×
1 CCU per hour =
**600 CCUs** |
+| **Total** | | **9960 CCUs** |
### Large-scale deployment
@@ -268,26 +268,26 @@ its globally distributed workforce, customer base, and (or) partners to operate
This organization:
* Uses the Enterprise product tier of Cube Cloud.
* Uses [dedicated infrastructure][ref-dedicated-infra].
-* Runs a Production Multi-Cluster that is active 24/7, includes 3 Production Clusters (M tier), with each
-Production Cluster auto-scaling up to 10 API instances during a few peak hours every day.
+* Runs a Multi-cluster deployment that is active 24/7, includes 3 Dedicated deployments (M tier), with each
+Dedicated deployment auto-scaling up to 10 API instances during a few peak hours every day.
* Operates on a large volume of data that requires the usage of 16 Cube Store Workers to run
queries and refresh pre-aggregations 24/7, being active approximately 50% of the time.
-* Uses a dedicated Development Instance (M tier) for testing purposes that is active 24 hours a day.
+* Uses a dedicated Shared deployment (M tier) for testing purposes that is active 24 hours a day.
* Has a team of 10 data engineers who frequently update the data model, with each data engineer
-spending about 4 hours a day in the development mode of the dedicated Development Instance.
+spending about 4 hours a day in the development mode of the dedicated Shared deployment.
* Uses a [Query History tier](#query-history-tiers) with 14-day data retention to inform the work
of data engineers.
-| Resource | Usage per month | CCU per month |
-| ----------------------------------------------- | ------------------------------------------------------------------------------------------- | ---------------------------------------------------- |
-| Dedicated infrastructure | 1 region ×
24 hours per day ×
30 days | 720 hours ×
3 CCUs per hour =
**2160 CCUs** |
-| Production Multi-Cluster | 3 Production Clusters ×
24 hours per day ×
30 days | 2160 hours ×
8 CCUs per hour =
**17280 CCUs** |
-| Additional Cube API Instance | 3 Production Clusters ×
(10 – 2) API Instances ×
4 hours per day ×
30 days | 2880 hours ×
2 CCU per hour =
**5760 CCUs** |
-| Cube Store Worker | 1 Production Multi-Cluster ×
16 Cube Store Workers ×
12 hours per day ×
30 days | 5760 hours ×
1 CCU per hour =
**5760 CCUs** |
-| Development Instance | 1 Development Instance ×
24 hours per day ×
30 days | 720 hours ×
2 CCU per hour =
**1440 CCUs** |
-| Development Instance
(for development mode) | 10 users ×
4 hours per day ×
30 days | 1200 hours ×
2 CCU per hour =
**2400 CCUs** |
-| Query History (M tier) | 24 hours per day ×
30 days | 720 hours ×
5 CCUs per hour =
**3600 CCUs** |
-| **Total** | | **38400 CCUs** |
+| Resource | Usage per month | CCU per month |
+| ---------------------------------------------- | ---------------------------------------------------------------------------------------------- | ----------------------------------------------------- |
+| Dedicated infrastructure | 1 region ×
24 hours per day ×
30 days | 720 hours ×
3 CCUs per hour =
**2160 CCUs** |
+| Multi-cluster deployment | 3 Dedicated deployments ×
24 hours per day ×
30 days | 2160 hours ×
8 CCUs per hour =
**17280 CCUs** |
+| Additional Cube API Instance | 3 Dedicated deployments ×
(10 – 2) API Instances ×
4 hours per day ×
30 days | 2880 hours ×
2 CCU per hour =
**5760 CCUs** |
+| Cube Store Worker | 1 Multi-cluster deployment ×
16 Cube Store Workers ×
12 hours per day ×
30 days | 5760 hours ×
1 CCU per hour =
**5760 CCUs** |
+| Shared deployment | 1 Shared deployment ×
24 hours per day ×
30 days | 720 hours ×
2 CCU per hour =
**1440 CCUs** |
+| Shared deployment
(for development mode) | 10 users ×
4 hours per day ×
30 days | 1200 hours ×
2 CCU per hour =
**2400 CCUs** |
+| Query History (M tier) | 24 hours per day ×
30 days | 720 hours ×
5 CCUs per hour =
**3600 CCUs** |
+| **Total** | | **38400 CCUs** |
## Payment terms
@@ -326,13 +326,13 @@ for the AI token consumption at the **Billing** page of their Cube Cloud account
[cube-pricing]: https://cube.dev/pricing
[link-contact-us]: https://cube.dev/contact
-[ref-cloud-deployment-dev-instance]: /docs/deployment/cloud/deployment-types#development-instance
-[ref-cloud-deployment-prod-cluster]: /docs/deployment/cloud/deployment-types#production-cluster
+[ref-cloud-deployment-dev-instance]: /docs/deployment/cloud/deployment-types#shared
+[ref-cloud-deployment-prod-cluster]: /docs/deployment/cloud/deployment-types#dedicated
[ref-cloud-limits]: /docs/deployment/cloud/limits
[ref-monitoring-integrations]: /docs/monitoring/integrations
[ref-monitoring-integrations-config]: /admin/deployment/monitoring-integrations#configuration
[ref-cloud-acl]: /admin/users-and-permissions/custom-roles
-[ref-cloud-deployment-prod-multicluster]: /docs/deployment/cloud/deployment-types#production-multi-cluster
+[ref-cloud-deployment-prod-multicluster]: /docs/deployment/cloud/deployment-types#multi-cluster
[ref-cloud-custom-domains]: /docs/deployment/cloud/custom-domains
[ref-cloud-vpc-peering]: /docs/deployment/cloud/vpc
[ref-sls]: /docs/integrations/semantic-layer-sync
@@ -346,8 +346,8 @@ for the AI token consumption at the **Billing** page of their Cube Cloud account
[ref-audit-log]: /admin/monitoring/audit-log
[ref-dedicated-infra]: /docs/deployment/cloud/infrastructure#dedicated-infrastructure
[ref-sso]: /docs/workspace/sso
-[ref-production-cluster]: /docs/deployment/cloud/deployment-types#production-cluster
-[ref-development-instance]: /docs/deployment/cloud/deployment-types#development-instance
+[ref-production-cluster]: /docs/deployment/cloud/deployment-types#dedicated
+[ref-development-instance]: /docs/deployment/cloud/deployment-types#shared
[ref-apis]: /reference
[ref-mdx-api]: /reference/mdx-api
[ref-dax-api]: /reference/dax-api
diff --git a/docs-mintlify/admin/deployment/auto-suspension.mdx b/docs-mintlify/admin/deployment/auto-suspension.mdx
index ab6df74437f36..b5763c4af4fd7 100644
--- a/docs-mintlify/admin/deployment/auto-suspension.mdx
+++ b/docs-mintlify/admin/deployment/auto-suspension.mdx
@@ -23,7 +23,7 @@ deployments**. See [effects on experience][self-effects] for details.
-Auto-suspension is not avaiable for [production multi-clusters][ref-prod-multi-cluster].
+Auto-suspension is not avaiable for [Multi-cluster deployments][ref-prod-multi-cluster].
@@ -35,9 +35,9 @@ deployment when API requests start coming in again:
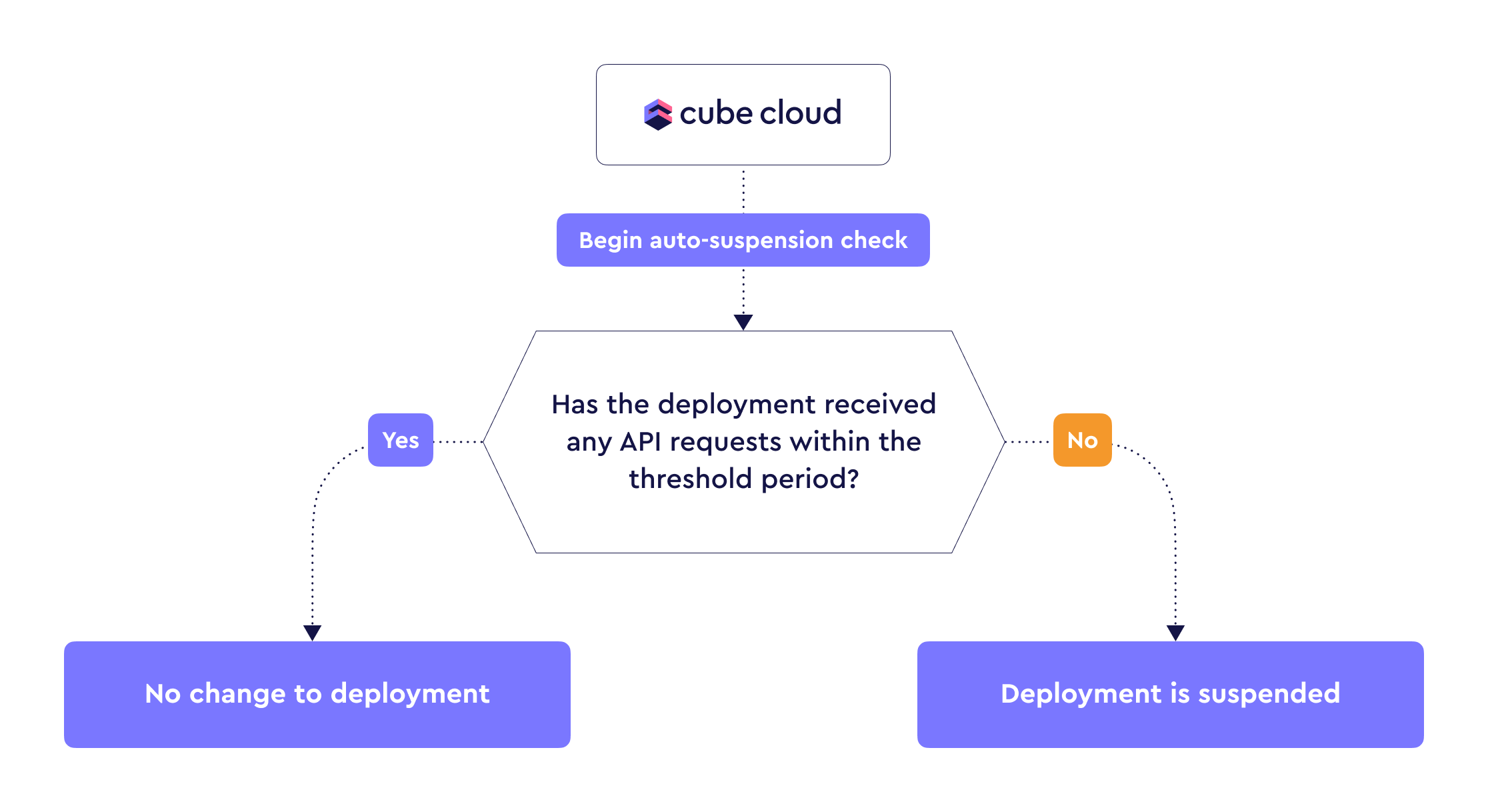 -[Development instances][ref-deployment-dev-instance] are auto-suspended
-automatically when not in use for 30 minutes, whereas [production
-clusters][ref-deployment-prod-cluster] can auto-suspend after no API
+[Shared deployments][ref-deployment-dev-instance] are auto-suspended
+automatically when not in use for 30 minutes, whereas [Dedicated
+deployments][ref-deployment-prod-cluster] can auto-suspend after no API
requests were received within a configurable time period.
During auto-suspension, resources are monitored in 5 minute intervals. This
@@ -114,9 +114,9 @@ longer in certain situations depending on two major factors:
Complex data models take more time to compile, and complex queries can cause
response times to be significantly longer than usual.
-[ref-deployment-dev-instance]: /docs/deployment/cloud/deployment-types#development-instance
-[ref-deployment-prod-cluster]: /docs/deployment/cloud/deployment-types#production-cluster
-[ref-prod-multi-cluster]: /docs/deployment/cloud/deployment-types#production-multi-cluster
+[ref-deployment-dev-instance]: /docs/deployment/cloud/deployment-types#shared
+[ref-deployment-prod-cluster]: /docs/deployment/cloud/deployment-types#dedicated
+[ref-prod-multi-cluster]: /docs/deployment/cloud/deployment-types#multi-cluster
[ref-deployment-pricing]: /admin/account-billing/pricing
[ref-monitoring]: /admin/deployment/monitoring-integrations
[ref-data-model]: /docs/data-modeling/overview
diff --git a/docs-mintlify/admin/deployment/continuous-deployment.mdx b/docs-mintlify/admin/deployment/continuous-deployment.mdx
index d424ef7ea645a..70756c59ecc54 100644
--- a/docs-mintlify/admin/deployment/continuous-deployment.mdx
+++ b/docs-mintlify/admin/deployment/continuous-deployment.mdx
@@ -48,71 +48,3 @@ session prior to connecting to your GitHub account from Cube.
Cube Cloud will automatically deploy from the specified production branch
(`master` by default).
-
-## Deploy with CLI
-
-
-
-Enabling this option will cause the **Data Model** page to display the
-last known state of a Git-based codebase (if available), instead of reflecting
-the latest modifications made. It is important to note that the logic will still
-be updated in both the API and the Playground.
-
-
-
-You can use [the CLI][ref-workspace-cli] to set up continuous deployment for a
-Git repository. You can also use it to manually deploy changes without
-continuous deployment.
-
-### Manual Deploys
-
-You can deploy your Cube project manually. This method uploads data models and
-configuration files directly from your local project directory.
-
-You can obtain a Cube Cloud deploy token from your
-deployment's **Settings** screen.
-
-```bash
-npx cubejs-cli deploy --token TOKEN
-```
-
-### Continuous Deployment
-
-You can use Cube CLI with your continuous integration tool.
-
-
-
-You can use the `CUBE_CLOUD_DEPLOY_AUTH` environment variable to pass the Cube
-Cloud deploy token to Cube CLI.
-
-
-
-Below is an example configuration for GitHub Actions:
-
-```yaml
-name: My Cube App
-on:
- push:
- paths:
- - "**"
- branches:
- - "master"
-jobs:
- deploy:
- name: Deploy My Cube App
- runs-on: ubuntu-latest
- timeout-minutes: 30
- steps:
- - name: Checkout
- uses: actions/checkout@v2
- - name: Use Node.js 20.x
- uses: actions/setup-node@v1
- with:
- node-version: 20.x
- - name: Install Cube backend server core
- run: npm i @cubejs-backend/server-core
- - name: Deploy to Cube Cloud
- run: npx cubejs-cli deploy --token ${{ secrets.CUBE_CLOUD_DEPLOY_AUTH }}
-```
-
-[ref-workspace-cli]: /docs/workspace/cli
\ No newline at end of file
diff --git a/docs-mintlify/admin/deployment/deployment-types.mdx b/docs-mintlify/admin/deployment/deployment-types.mdx
index 6ef694994feba..97828a6a90da4 100644
--- a/docs-mintlify/admin/deployment/deployment-types.mdx
+++ b/docs-mintlify/admin/deployment/deployment-types.mdx
@@ -1,55 +1,53 @@
---
title: Deployment types
sidebarTitle: Deployment types
-description: "Cube provides three deployment types: Development, Production, and Multi-cluster."
+description: "Cube provides three deployment types: Shared, Dedicated, and Multi-cluster."
---
-* [Development](#development) — designed for development use cases.
-* [Production](#production) — designed for production workloads and
-high-availability.
+* [Shared](#shared) — designed for development use cases. Runs on compute
+shared with other deployments within the selected region.
+* [Dedicated](#dedicated) — designed for production workloads and
+high-availability. Runs on compute dedicated to your deployment.
* [Multi-cluster](#multi-cluster) — designed for demanding production workloads,
high-scalability, high-availability, and advanced multi-tenancy configurations.
+Runs on multiple Dedicated deployments.
-## Development
+## Shared {#shared}
Available for free, no credit card required. Your free trial is limited to 2
-development deployments and only 1,000 queries per day. Upgrade to
+Shared deployments and only 1,000 queries per day. Upgrade to
[any paid plan](https://cube.dev/pricing) to unlock all features.
-
-[Development instances][ref-deployment-dev-instance] are auto-suspended
-automatically when not in use for 30 minutes, whereas [production
-clusters][ref-deployment-prod-cluster] can auto-suspend after no API
+[Shared deployments][ref-deployment-dev-instance] are auto-suspended
+automatically when not in use for 30 minutes, whereas [Dedicated
+deployments][ref-deployment-prod-cluster] can auto-suspend after no API
requests were received within a configurable time period.
During auto-suspension, resources are monitored in 5 minute intervals. This
@@ -114,9 +114,9 @@ longer in certain situations depending on two major factors:
Complex data models take more time to compile, and complex queries can cause
response times to be significantly longer than usual.
-[ref-deployment-dev-instance]: /docs/deployment/cloud/deployment-types#development-instance
-[ref-deployment-prod-cluster]: /docs/deployment/cloud/deployment-types#production-cluster
-[ref-prod-multi-cluster]: /docs/deployment/cloud/deployment-types#production-multi-cluster
+[ref-deployment-dev-instance]: /docs/deployment/cloud/deployment-types#shared
+[ref-deployment-prod-cluster]: /docs/deployment/cloud/deployment-types#dedicated
+[ref-prod-multi-cluster]: /docs/deployment/cloud/deployment-types#multi-cluster
[ref-deployment-pricing]: /admin/account-billing/pricing
[ref-monitoring]: /admin/deployment/monitoring-integrations
[ref-data-model]: /docs/data-modeling/overview
diff --git a/docs-mintlify/admin/deployment/continuous-deployment.mdx b/docs-mintlify/admin/deployment/continuous-deployment.mdx
index d424ef7ea645a..70756c59ecc54 100644
--- a/docs-mintlify/admin/deployment/continuous-deployment.mdx
+++ b/docs-mintlify/admin/deployment/continuous-deployment.mdx
@@ -48,71 +48,3 @@ session prior to connecting to your GitHub account from Cube.
Cube Cloud will automatically deploy from the specified production branch
(`master` by default).
-
-## Deploy with CLI
-
-
-
-Enabling this option will cause the **Data Model** page to display the
-last known state of a Git-based codebase (if available), instead of reflecting
-the latest modifications made. It is important to note that the logic will still
-be updated in both the API and the Playground.
-
-
-
-You can use [the CLI][ref-workspace-cli] to set up continuous deployment for a
-Git repository. You can also use it to manually deploy changes without
-continuous deployment.
-
-### Manual Deploys
-
-You can deploy your Cube project manually. This method uploads data models and
-configuration files directly from your local project directory.
-
-You can obtain a Cube Cloud deploy token from your
-deployment's **Settings** screen.
-
-```bash
-npx cubejs-cli deploy --token TOKEN
-```
-
-### Continuous Deployment
-
-You can use Cube CLI with your continuous integration tool.
-
-
-
-You can use the `CUBE_CLOUD_DEPLOY_AUTH` environment variable to pass the Cube
-Cloud deploy token to Cube CLI.
-
-
-
-Below is an example configuration for GitHub Actions:
-
-```yaml
-name: My Cube App
-on:
- push:
- paths:
- - "**"
- branches:
- - "master"
-jobs:
- deploy:
- name: Deploy My Cube App
- runs-on: ubuntu-latest
- timeout-minutes: 30
- steps:
- - name: Checkout
- uses: actions/checkout@v2
- - name: Use Node.js 20.x
- uses: actions/setup-node@v1
- with:
- node-version: 20.x
- - name: Install Cube backend server core
- run: npm i @cubejs-backend/server-core
- - name: Deploy to Cube Cloud
- run: npx cubejs-cli deploy --token ${{ secrets.CUBE_CLOUD_DEPLOY_AUTH }}
-```
-
-[ref-workspace-cli]: /docs/workspace/cli
\ No newline at end of file
diff --git a/docs-mintlify/admin/deployment/deployment-types.mdx b/docs-mintlify/admin/deployment/deployment-types.mdx
index 6ef694994feba..97828a6a90da4 100644
--- a/docs-mintlify/admin/deployment/deployment-types.mdx
+++ b/docs-mintlify/admin/deployment/deployment-types.mdx
@@ -1,55 +1,53 @@
---
title: Deployment types
sidebarTitle: Deployment types
-description: "Cube provides three deployment types: Development, Production, and Multi-cluster."
+description: "Cube provides three deployment types: Shared, Dedicated, and Multi-cluster."
---
-* [Development](#development) — designed for development use cases.
-* [Production](#production) — designed for production workloads and
-high-availability.
+* [Shared](#shared) — designed for development use cases. Runs on compute
+shared with other deployments within the selected region.
+* [Dedicated](#dedicated) — designed for production workloads and
+high-availability. Runs on compute dedicated to your deployment.
* [Multi-cluster](#multi-cluster) — designed for demanding production workloads,
high-scalability, high-availability, and advanced multi-tenancy configurations.
+Runs on multiple Dedicated deployments.
-## Development
+## Shared {#shared}
Available for free, no credit card required. Your free trial is limited to 2
-development deployments and only 1,000 queries per day. Upgrade to
+Shared deployments and only 1,000 queries per day. Upgrade to
[any paid plan](https://cube.dev/pricing) to unlock all features.
-
-
-
-
-
-
-
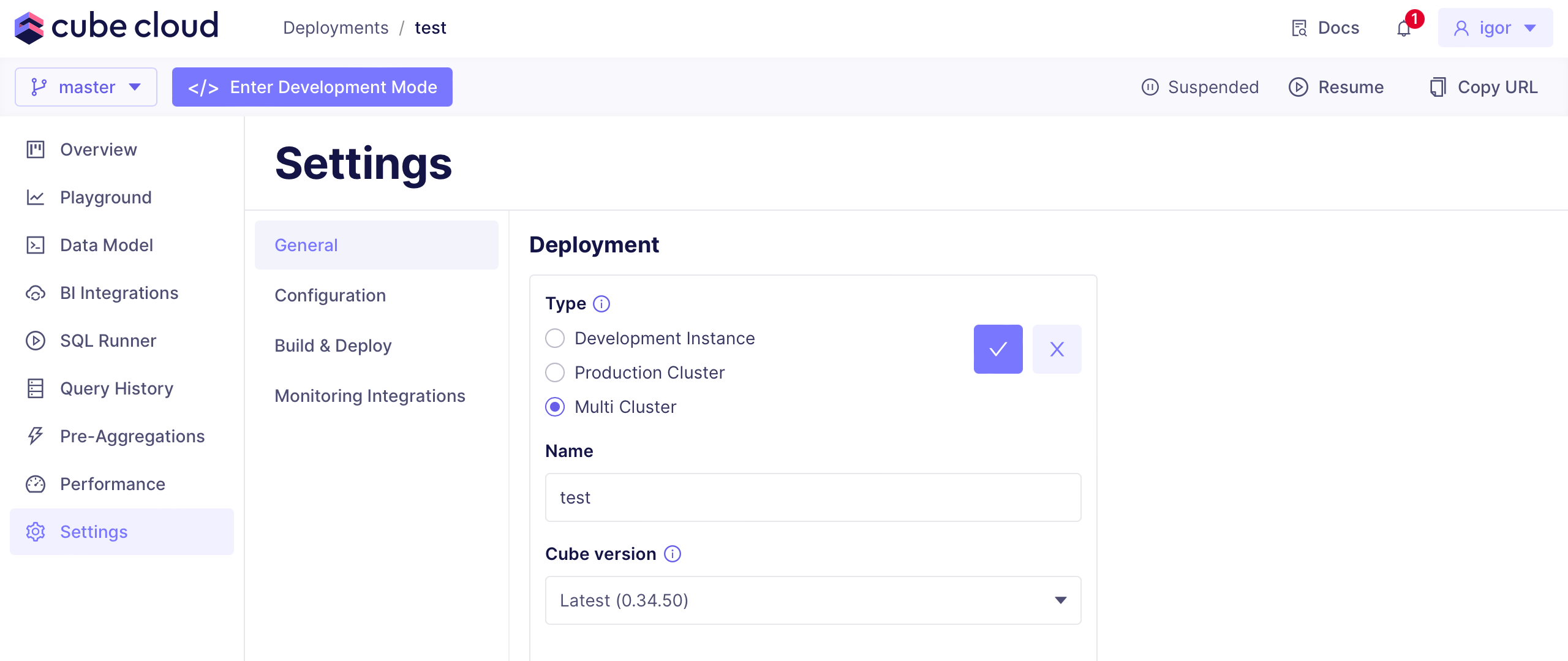 -
+with **✓**.
-To set the number of production deployments within your Multi-cluster
+To set the number of Dedicated deployments within your Multi-cluster
deployment, navigate to **Settings → Configuration** and edit
**Number of clusters**.
-
-
-
+with **✓**.
-To set the number of production deployments within your Multi-cluster
+To set the number of Dedicated deployments within your Multi-cluster
deployment, navigate to **Settings → Configuration** and edit
**Number of clusters**.
-
- 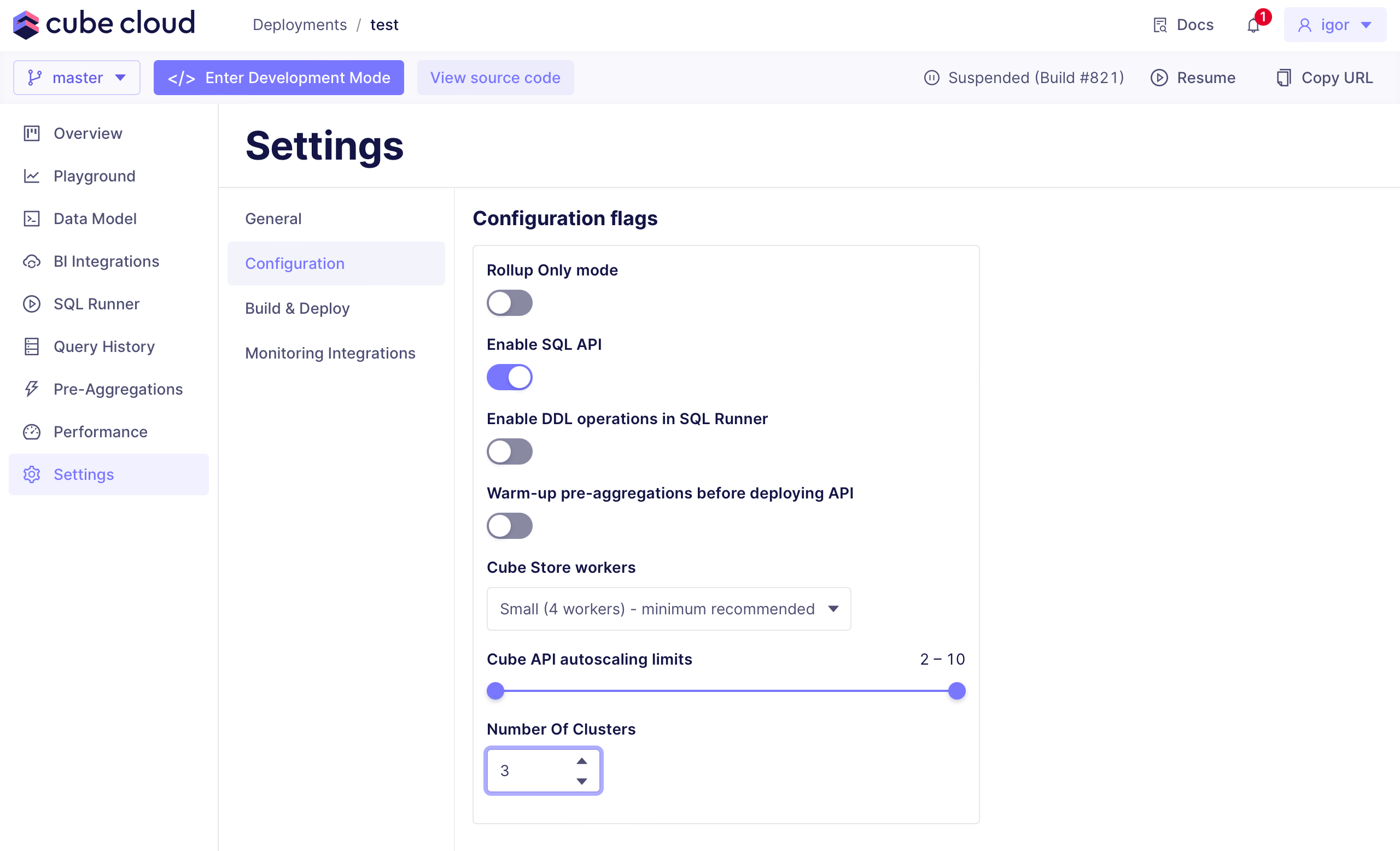 -
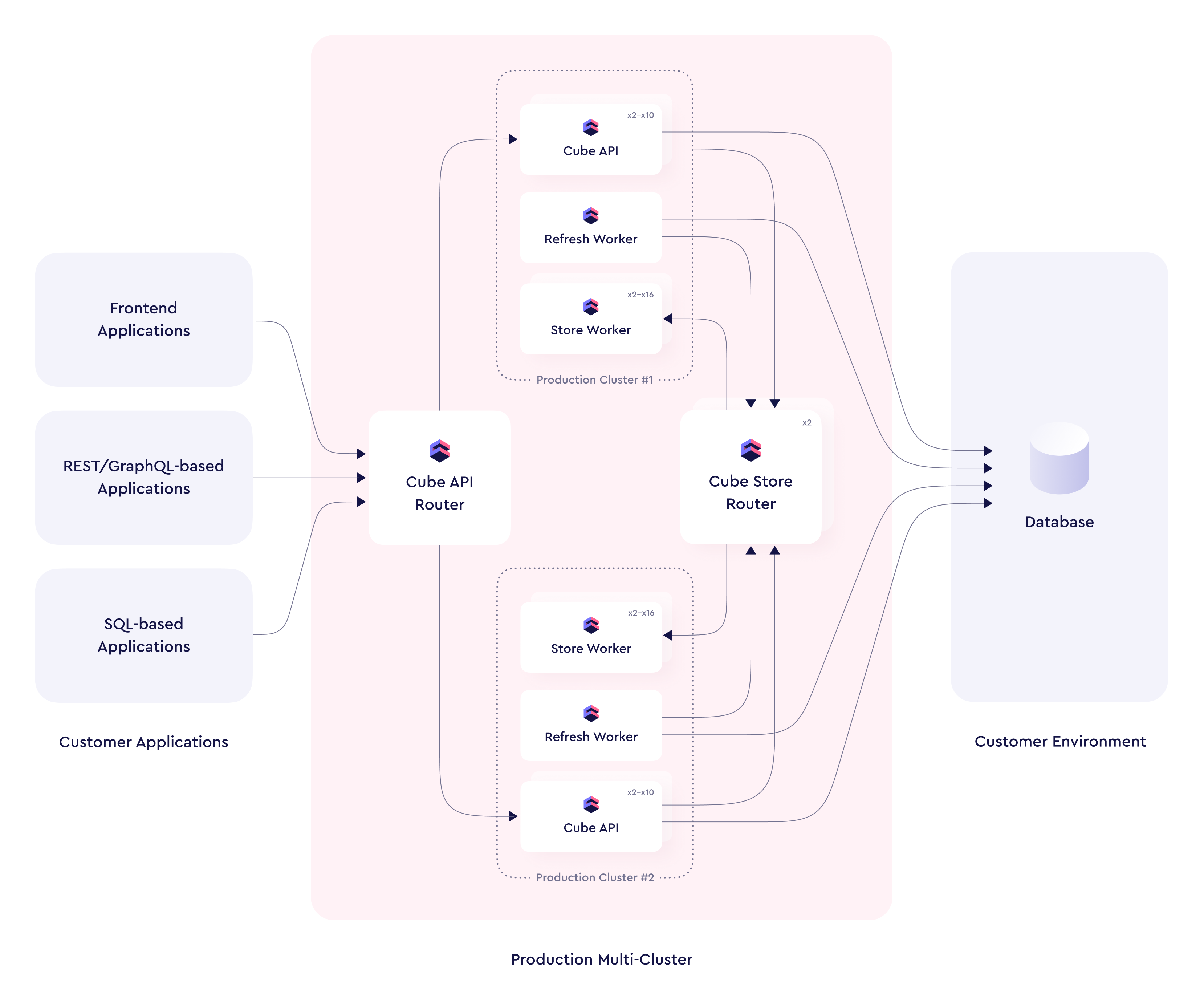
+### Routing traffic between Dedicated deployments
-### Routing traffic between production deployments
-
-Cube routes requests between multiple production deployments within a
+Cube routes requests between multiple Dedicated deployments within a
Multi-cluster deployment based on [`context_to_app_id`][ref-ctx-to-app-id].
In most cases, it should return an identifier that does not change over time
for each tenant.
The following implementation will make sure that all requests from a
-particular tenant are always routed to the same production deployment. This
-approach ensures that only one production deployment keeps compiled data model
+particular tenant are always routed to the same Dedicated deployment. This
+approach ensures that only one Dedicated deployment keeps compiled data model
cache for each tenant and serves its requests. It allows to reduce the
-footprint of the compiled data model cache on individual production deployments.
+footprint of the compiled data model cache on individual Dedicated deployments.
@@ -159,7 +136,7 @@ module.exports = {
If your implementation of `context_to_app_id` returns identifiers that change
over time for each tenant, requests from one tenant would likely hit multiple
-production deployments and you would not have the benefit of reduced memory
+Dedicated deployments and you would not have the benefit of reduced memory
footprint. Also you might see 502 or timeout errors in case of different
deployment nodes would return different `context_to_app_id` results for the
same request.
@@ -169,11 +146,7 @@ same request.
## Switching between deployment types
To switch a deployment's type, go to the deployment's **Settings** screen
-and select from the available options:
-
-
-
-
+### Routing traffic between Dedicated deployments
-### Routing traffic between production deployments
-
-Cube routes requests between multiple production deployments within a
+Cube routes requests between multiple Dedicated deployments within a
Multi-cluster deployment based on [`context_to_app_id`][ref-ctx-to-app-id].
In most cases, it should return an identifier that does not change over time
for each tenant.
The following implementation will make sure that all requests from a
-particular tenant are always routed to the same production deployment. This
-approach ensures that only one production deployment keeps compiled data model
+particular tenant are always routed to the same Dedicated deployment. This
+approach ensures that only one Dedicated deployment keeps compiled data model
cache for each tenant and serves its requests. It allows to reduce the
-footprint of the compiled data model cache on individual production deployments.
+footprint of the compiled data model cache on individual Dedicated deployments.
@@ -159,7 +136,7 @@ module.exports = {
If your implementation of `context_to_app_id` returns identifiers that change
over time for each tenant, requests from one tenant would likely hit multiple
-production deployments and you would not have the benefit of reduced memory
+Dedicated deployments and you would not have the benefit of reduced memory
footprint. Also you might see 502 or timeout errors in case of different
deployment nodes would return different `context_to_app_id` results for the
same request.
@@ -169,11 +146,7 @@ same request.
## Switching between deployment types
To switch a deployment's type, go to the deployment's **Settings** screen
-and select from the available options:
-
-
-  -
+and select from the available options.
[ref-ctx-to-app-id]: /reference/configuration/config#context_to_app_id
[ref-limits]: /docs/deployment/cloud/limits#resources
diff --git a/docs-mintlify/admin/deployment/environments.mdx b/docs-mintlify/admin/deployment/environments.mdx
index db2d753b14cf5..a1cdacae6a40d 100644
--- a/docs-mintlify/admin/deployment/environments.mdx
+++ b/docs-mintlify/admin/deployment/environments.mdx
@@ -25,7 +25,7 @@ The production environment is _always available_ unless [suspended][ref-suspend]
### Resources and costs
Depending on the [deployment type][ref-deployment-types], the production environment
-either runs on a development instance or on a production cluster with [multiple API
+either runs on a Shared deployment or on a Dedicated deployment with [multiple API
instances][ref-api-instance-scalability], incurring [relevant
costs][ref-pricing-deployment-tiers].
@@ -59,7 +59,7 @@ regardless of user activity.
### Resources and costs
-Staging environments run on development instances, incurring [relevant
+Staging environments run on Shared deployments, incurring [relevant
costs][ref-pricing-deployment-tiers]. However, they automatically suspend after 10 minutes
of inactivity, regardless of the [availability](#availability) setting, so you are only
charged for the time when staging environments are being used.
@@ -83,7 +83,7 @@ development mode. Otherwise, queries to this environment will fail.
### Resources and costs
-Development environments run on development instances, incurring [relevant
+Development environments run on Shared deployments, incurring [relevant
costs][ref-pricing-deployment-tiers]. However, they automatically suspend after 10 minutes
of inactivity, so you are only charged for the time when development environments are
being used.
diff --git a/docs-mintlify/admin/deployment/index.mdx b/docs-mintlify/admin/deployment/index.mdx
index 39c4dfaa089b7..512058600c136 100644
--- a/docs-mintlify/admin/deployment/index.mdx
+++ b/docs-mintlify/admin/deployment/index.mdx
@@ -173,8 +173,8 @@ Cube Cloud deployments only consume resources when they are needed to run worklo
* For the [production environment][ref-environments-prod], resources are always consumed
unless a deployment is [suspended][ref-auto-sus].
-* For any other [environment][ref-environments], a development instance is allocated
-while it's active. After a period of inactivity, the development instance is deallocated.
+* For any other [environment][ref-environments], a Shared deployment is allocated
+while it's active. After a period of inactivity, the Shared deployment is deallocated.
* For pre-aggregations, Cube Store workers are allocated while there's some
activity related to pre-aggregations, e.g., API endpoints are serving
requests to pre-aggregations, pre-aggregations are being built, etc.
diff --git a/docs-mintlify/admin/deployment/limits.mdx b/docs-mintlify/admin/deployment/limits.mdx
index 10490a14aa67a..69c2729b4af04 100644
--- a/docs-mintlify/admin/deployment/limits.mdx
+++ b/docs-mintlify/admin/deployment/limits.mdx
@@ -29,8 +29,8 @@ types][ref-deployment-types] and [product tiers][ref-pricing]:
| Number of deployments | 2 | Unlimited | Unlimited | Unlimited |
| Number of API instances per deployment | 1 | 10 | 10 | [Contact us][cube-contact-us] |
| Number of Cube Store workers per deployment | 2 | 16 | 16 | [Contact us][cube-contact-us] |
-| Queries per day for each [development instance][ref-dev-instance] | 1,000 | 10,000 | Unlimited | Unlimited |
-| Queries per day for each [production cluster][ref-prod-cluster] | — | 50,000 | Unlimited | Unlimited |
+| Queries per day for each [Shared deployment][ref-dev-instance] | 1,000 | 10,000 | Unlimited | Unlimited |
+| Queries per day for each [Dedicated deployment][ref-prod-cluster] | — | 50,000 | Unlimited | Unlimited |
| [Query History][ref-query-history] — retention period | 1 day | Depends on the [tier][ref-query-history-tiers] | Depends on the [tier][ref-query-history-tiers] | Depends on the [tier][ref-query-history-tiers] |
| [Query History][ref-query-history] — queries processed per day for each deployment | 1,000 | Depends on the [tier][ref-query-history-tiers] | Depends on the [tier][ref-query-history-tiers] | Depends on the [tier][ref-query-history-tiers] |
| [Audit Log][ref-audit-log] — retention period | — | — | — | 30 days |
@@ -58,7 +58,7 @@ This is a hard limit. Usage is calculated per Cube Cloud account, i.e., in total
for all deployments within an account.
When a threshold is hit, further queries will not be processed. In that case,
-consider upgrading a development instance to a production cluster.
+consider upgrading a Shared deployment to a Dedicated deployment.
Alternatively, consider upgrading to [another tier][ref-pricing].
### Queries processed by Query History per day
@@ -101,8 +101,8 @@ response.
[ref-pricing]: /admin/account-billing/pricing
[ref-query-history]: /admin/monitoring/query-history
[ref-monitoring-integrations]: /admin/deployment/monitoring-integrations
-[ref-dev-instance]: /docs/deployment/cloud/deployment-types#development-instance
-[ref-prod-cluster]: /docs/deployment/cloud/deployment-types#production-cluster
+[ref-dev-instance]: /docs/deployment/cloud/deployment-types#shared
+[ref-prod-cluster]: /docs/deployment/cloud/deployment-types#dedicated
[cube-contact-us]: https://cube.dev/contact
[ref-query-history-tiers]: /admin/account-billing/pricing#query-history-tiers
[ref-audit-log]: /admin/monitoring/audit-log
diff --git a/docs-mintlify/admin/deployment/scalability.mdx b/docs-mintlify/admin/deployment/scalability.mdx
index 8b1909af0c8b4..bc24060fb7db1 100644
--- a/docs-mintlify/admin/deployment/scalability.mdx
+++ b/docs-mintlify/admin/deployment/scalability.mdx
@@ -5,17 +5,17 @@ description: Tune Cube Cloud throughput and pre-aggregation capacity by scaling
Cube Cloud also allows adding additional infrastructure to your deployment to
increase scalability and performance beyond what is available with each
-Production Deployment.
+Dedicated deployment.
## Auto-scaling of API instances
-With a Production Cluster, 2 Cube API Instances are included. That said, it
+With a Dedicated deployment, 2 Cube API Instances are included. That said, it
is very common to use more, and [additional API instances][ref-limits] can be
added to your deployment to increase the throughput of your queries. A rough
estimate is that 1 Cube API Instance is needed for every 5-10
requests-per-second served. Cube API Instances can also auto-scale as needed.
-To change how many Cube API instances are available in the Production Cluster,
+To change how many Cube API instances are available in the Dedicated deployment,
go to the deployment’s **Settings** screen, and open
the **Configuration** tab. From this screen, you can set the minimum and
maximum number of Cube API instances for a deployment:
diff --git a/docs-mintlify/admin/deployment/warm-up.mdx b/docs-mintlify/admin/deployment/warm-up.mdx
index 39caba49c71eb..a1e6935c1e472 100644
--- a/docs-mintlify/admin/deployment/warm-up.mdx
+++ b/docs-mintlify/admin/deployment/warm-up.mdx
@@ -1,6 +1,6 @@
---
title: Deployment warm-up
-description: Covers optional pre-launch warm-up for data model compilation and pre-aggregations on production cluster deployments.
+description: Covers optional pre-launch warm-up for data model compilation and pre-aggregations on Dedicated deployments.
---
Deployment warm-up improves querying performance by executing time-consuming
@@ -15,8 +15,8 @@ Available on [Starter and above plans](https://cube.dev/pricing).
-Deployment warm-up is only available for [production cluster][ref-prod-cluster]
-and [production multi-cluster][ref-prod-multi-cluster] deployments.
+Deployment warm-up is only available for [Dedicated][ref-prod-cluster]
+and [Multi-cluster][ref-prod-multi-cluster] deployments.
@@ -90,8 +90,8 @@ and enable **Warm-up pre-aggregations before deploying API**:
-[ref-prod-cluster]: /docs/deployment/cloud/deployment-types#production-cluster
-[ref-prod-multi-cluster]: /docs/deployment/cloud/deployment-types#production-multi-cluster
+[ref-prod-cluster]: /docs/deployment/cloud/deployment-types#dedicated
+[ref-prod-multi-cluster]: /docs/deployment/cloud/deployment-types#multi-cluster
[ref-data-model]: /docs/data-modeling/overview
[ref-dynamic-data-model]: /docs/data-modeling/dynamic
[ref-multitenancy]: /embedding/multitenancy
diff --git a/docs-mintlify/admin/monitoring/performance.mdx b/docs-mintlify/admin/monitoring/performance.mdx
index 647c7946d07c9..9cbe3e3bd298f 100644
--- a/docs-mintlify/admin/monitoring/performance.mdx
+++ b/docs-mintlify/admin/monitoring/performance.mdx
@@ -56,17 +56,17 @@ compilation](#data-model-compilation).
Also, you can use this chart to **fine-tune the
[auto-suspension][ref-auto-sus] configuration**, e.g., by turning
auto-suspension off or increasing the auto-suspension threshold.
-For example, the following chart shows a [Development
-Instance][ref-dev-instance] deployment that is only accessed a few times
+For example, the following chart shows a [Shared
+deployment][ref-dev-instance] that is only accessed a few times
a day and automatically suspends after a short period of inactivity:
-
+and select from the available options.
[ref-ctx-to-app-id]: /reference/configuration/config#context_to_app_id
[ref-limits]: /docs/deployment/cloud/limits#resources
diff --git a/docs-mintlify/admin/deployment/environments.mdx b/docs-mintlify/admin/deployment/environments.mdx
index db2d753b14cf5..a1cdacae6a40d 100644
--- a/docs-mintlify/admin/deployment/environments.mdx
+++ b/docs-mintlify/admin/deployment/environments.mdx
@@ -25,7 +25,7 @@ The production environment is _always available_ unless [suspended][ref-suspend]
### Resources and costs
Depending on the [deployment type][ref-deployment-types], the production environment
-either runs on a development instance or on a production cluster with [multiple API
+either runs on a Shared deployment or on a Dedicated deployment with [multiple API
instances][ref-api-instance-scalability], incurring [relevant
costs][ref-pricing-deployment-tiers].
@@ -59,7 +59,7 @@ regardless of user activity.
### Resources and costs
-Staging environments run on development instances, incurring [relevant
+Staging environments run on Shared deployments, incurring [relevant
costs][ref-pricing-deployment-tiers]. However, they automatically suspend after 10 minutes
of inactivity, regardless of the [availability](#availability) setting, so you are only
charged for the time when staging environments are being used.
@@ -83,7 +83,7 @@ development mode. Otherwise, queries to this environment will fail.
### Resources and costs
-Development environments run on development instances, incurring [relevant
+Development environments run on Shared deployments, incurring [relevant
costs][ref-pricing-deployment-tiers]. However, they automatically suspend after 10 minutes
of inactivity, so you are only charged for the time when development environments are
being used.
diff --git a/docs-mintlify/admin/deployment/index.mdx b/docs-mintlify/admin/deployment/index.mdx
index 39c4dfaa089b7..512058600c136 100644
--- a/docs-mintlify/admin/deployment/index.mdx
+++ b/docs-mintlify/admin/deployment/index.mdx
@@ -173,8 +173,8 @@ Cube Cloud deployments only consume resources when they are needed to run worklo
* For the [production environment][ref-environments-prod], resources are always consumed
unless a deployment is [suspended][ref-auto-sus].
-* For any other [environment][ref-environments], a development instance is allocated
-while it's active. After a period of inactivity, the development instance is deallocated.
+* For any other [environment][ref-environments], a Shared deployment is allocated
+while it's active. After a period of inactivity, the Shared deployment is deallocated.
* For pre-aggregations, Cube Store workers are allocated while there's some
activity related to pre-aggregations, e.g., API endpoints are serving
requests to pre-aggregations, pre-aggregations are being built, etc.
diff --git a/docs-mintlify/admin/deployment/limits.mdx b/docs-mintlify/admin/deployment/limits.mdx
index 10490a14aa67a..69c2729b4af04 100644
--- a/docs-mintlify/admin/deployment/limits.mdx
+++ b/docs-mintlify/admin/deployment/limits.mdx
@@ -29,8 +29,8 @@ types][ref-deployment-types] and [product tiers][ref-pricing]:
| Number of deployments | 2 | Unlimited | Unlimited | Unlimited |
| Number of API instances per deployment | 1 | 10 | 10 | [Contact us][cube-contact-us] |
| Number of Cube Store workers per deployment | 2 | 16 | 16 | [Contact us][cube-contact-us] |
-| Queries per day for each [development instance][ref-dev-instance] | 1,000 | 10,000 | Unlimited | Unlimited |
-| Queries per day for each [production cluster][ref-prod-cluster] | — | 50,000 | Unlimited | Unlimited |
+| Queries per day for each [Shared deployment][ref-dev-instance] | 1,000 | 10,000 | Unlimited | Unlimited |
+| Queries per day for each [Dedicated deployment][ref-prod-cluster] | — | 50,000 | Unlimited | Unlimited |
| [Query History][ref-query-history] — retention period | 1 day | Depends on the [tier][ref-query-history-tiers] | Depends on the [tier][ref-query-history-tiers] | Depends on the [tier][ref-query-history-tiers] |
| [Query History][ref-query-history] — queries processed per day for each deployment | 1,000 | Depends on the [tier][ref-query-history-tiers] | Depends on the [tier][ref-query-history-tiers] | Depends on the [tier][ref-query-history-tiers] |
| [Audit Log][ref-audit-log] — retention period | — | — | — | 30 days |
@@ -58,7 +58,7 @@ This is a hard limit. Usage is calculated per Cube Cloud account, i.e., in total
for all deployments within an account.
When a threshold is hit, further queries will not be processed. In that case,
-consider upgrading a development instance to a production cluster.
+consider upgrading a Shared deployment to a Dedicated deployment.
Alternatively, consider upgrading to [another tier][ref-pricing].
### Queries processed by Query History per day
@@ -101,8 +101,8 @@ response.
[ref-pricing]: /admin/account-billing/pricing
[ref-query-history]: /admin/monitoring/query-history
[ref-monitoring-integrations]: /admin/deployment/monitoring-integrations
-[ref-dev-instance]: /docs/deployment/cloud/deployment-types#development-instance
-[ref-prod-cluster]: /docs/deployment/cloud/deployment-types#production-cluster
+[ref-dev-instance]: /docs/deployment/cloud/deployment-types#shared
+[ref-prod-cluster]: /docs/deployment/cloud/deployment-types#dedicated
[cube-contact-us]: https://cube.dev/contact
[ref-query-history-tiers]: /admin/account-billing/pricing#query-history-tiers
[ref-audit-log]: /admin/monitoring/audit-log
diff --git a/docs-mintlify/admin/deployment/scalability.mdx b/docs-mintlify/admin/deployment/scalability.mdx
index 8b1909af0c8b4..bc24060fb7db1 100644
--- a/docs-mintlify/admin/deployment/scalability.mdx
+++ b/docs-mintlify/admin/deployment/scalability.mdx
@@ -5,17 +5,17 @@ description: Tune Cube Cloud throughput and pre-aggregation capacity by scaling
Cube Cloud also allows adding additional infrastructure to your deployment to
increase scalability and performance beyond what is available with each
-Production Deployment.
+Dedicated deployment.
## Auto-scaling of API instances
-With a Production Cluster, 2 Cube API Instances are included. That said, it
+With a Dedicated deployment, 2 Cube API Instances are included. That said, it
is very common to use more, and [additional API instances][ref-limits] can be
added to your deployment to increase the throughput of your queries. A rough
estimate is that 1 Cube API Instance is needed for every 5-10
requests-per-second served. Cube API Instances can also auto-scale as needed.
-To change how many Cube API instances are available in the Production Cluster,
+To change how many Cube API instances are available in the Dedicated deployment,
go to the deployment’s **Settings** screen, and open
the **Configuration** tab. From this screen, you can set the minimum and
maximum number of Cube API instances for a deployment:
diff --git a/docs-mintlify/admin/deployment/warm-up.mdx b/docs-mintlify/admin/deployment/warm-up.mdx
index 39caba49c71eb..a1e6935c1e472 100644
--- a/docs-mintlify/admin/deployment/warm-up.mdx
+++ b/docs-mintlify/admin/deployment/warm-up.mdx
@@ -1,6 +1,6 @@
---
title: Deployment warm-up
-description: Covers optional pre-launch warm-up for data model compilation and pre-aggregations on production cluster deployments.
+description: Covers optional pre-launch warm-up for data model compilation and pre-aggregations on Dedicated deployments.
---
Deployment warm-up improves querying performance by executing time-consuming
@@ -15,8 +15,8 @@ Available on [Starter and above plans](https://cube.dev/pricing).
-Deployment warm-up is only available for [production cluster][ref-prod-cluster]
-and [production multi-cluster][ref-prod-multi-cluster] deployments.
+Deployment warm-up is only available for [Dedicated][ref-prod-cluster]
+and [Multi-cluster][ref-prod-multi-cluster] deployments.
@@ -90,8 +90,8 @@ and enable **Warm-up pre-aggregations before deploying API**:
-[ref-prod-cluster]: /docs/deployment/cloud/deployment-types#production-cluster
-[ref-prod-multi-cluster]: /docs/deployment/cloud/deployment-types#production-multi-cluster
+[ref-prod-cluster]: /docs/deployment/cloud/deployment-types#dedicated
+[ref-prod-multi-cluster]: /docs/deployment/cloud/deployment-types#multi-cluster
[ref-data-model]: /docs/data-modeling/overview
[ref-dynamic-data-model]: /docs/data-modeling/dynamic
[ref-multitenancy]: /embedding/multitenancy
diff --git a/docs-mintlify/admin/monitoring/performance.mdx b/docs-mintlify/admin/monitoring/performance.mdx
index 647c7946d07c9..9cbe3e3bd298f 100644
--- a/docs-mintlify/admin/monitoring/performance.mdx
+++ b/docs-mintlify/admin/monitoring/performance.mdx
@@ -56,17 +56,17 @@ compilation](#data-model-compilation).
Also, you can use this chart to **fine-tune the
[auto-suspension][ref-auto-sus] configuration**, e.g., by turning
auto-suspension off or increasing the auto-suspension threshold.
-For example, the following chart shows a [Development
-Instance][ref-dev-instance] deployment that is only accessed a few times
+For example, the following chart shows a [Shared
+deployment][ref-dev-instance] that is only accessed a few times
a day and automatically suspends after a short period of inactivity:
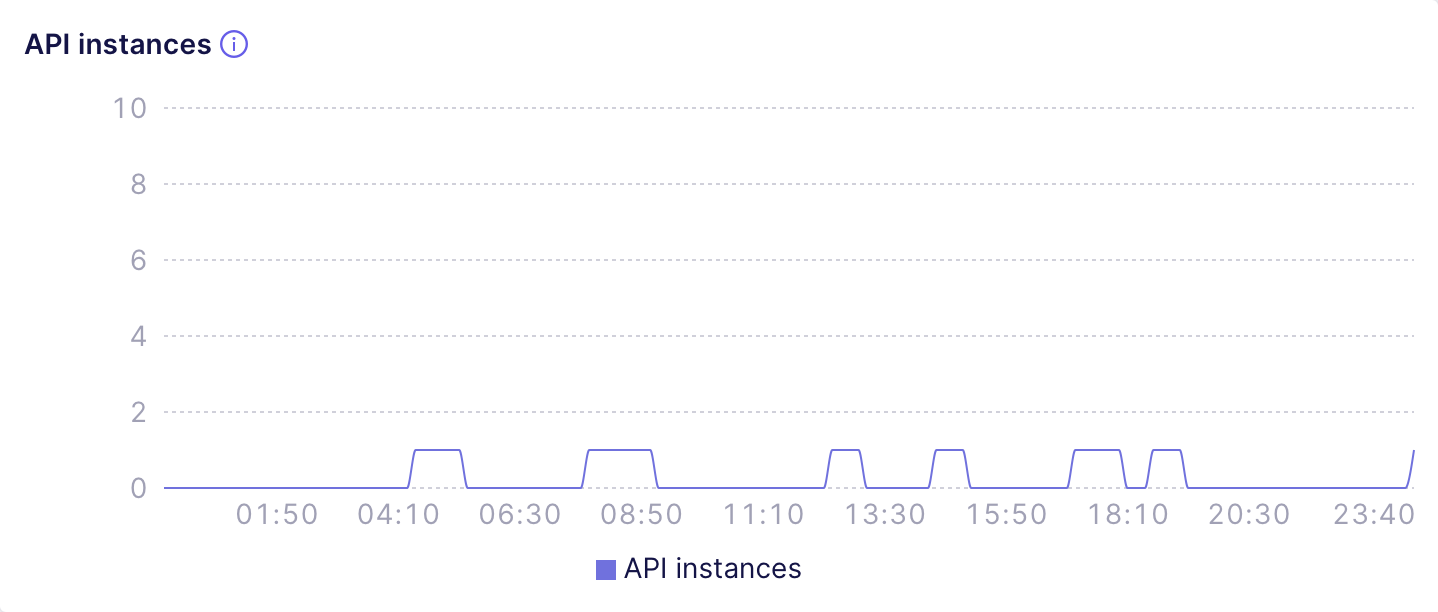 -The next chart shows a misconfigured [Production Cluster][ref-prod-cluster]
-deployment that serves the requests throughout the whole day but was
-configured to auto-suspend with a tiny threshold:
+The next chart shows a misconfigured [Dedicated
+deployment][ref-prod-cluster] that serves the requests throughout the whole
+day but was configured to auto-suspend with a tiny threshold:
-The next chart shows a misconfigured [Production Cluster][ref-prod-cluster]
-deployment that serves the requests throughout the whole day but was
-configured to auto-suspend with a tiny threshold:
+The next chart shows a misconfigured [Dedicated
+deployment][ref-prod-cluster] that serves the requests throughout the whole
+day but was configured to auto-suspend with a tiny threshold:
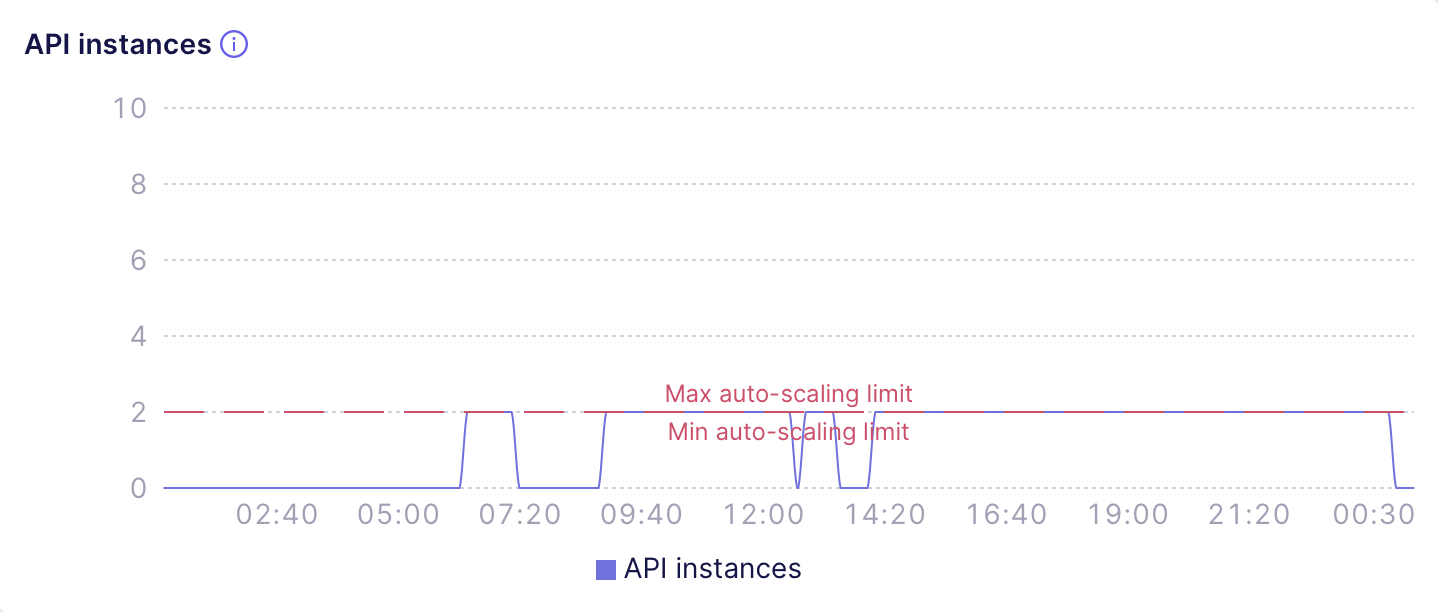 @@ -126,9 +126,9 @@ configuration** (e.g., turn it off or increase the threshold so that API
instances suspend less frequently), **identify [multitenancy][ref-multitenancy]
misconfiguration** (e.g., suboptimal bucketing via
[`context_to_app_id`][ref-context-to-app-id]), or
-**consider using a [multi-cluster deployment][ref-multi-cluster]** to
-distribute requests to different tenants over a number of Production
-Cluster deployments.
+**consider using a [Multi-cluster deployment][ref-multi-cluster]** to
+distribute requests to different tenants over a number of Dedicated
+deployments.
### Cube Store
@@ -176,9 +176,9 @@ for queries and jobs.
[ref-scalability-api]: /docs/deployment/cloud/scalability#auto-scaling-of-api-instances
[ref-scalability-cube-store]: /docs/deployment/cloud/scalability#sizing-cube-store-workers
[ref-auto-sus]: /docs/deployment/cloud/auto-suspension
-[ref-dev-instance]: /docs/deployment/cloud/deployment-types#development-instance
-[ref-prod-cluster]: /docs/deployment/cloud/deployment-types#production-cluster
-[ref-multi-cluster]: /docs/deployment/cloud/deployment-types#production-multi-cluster
+[ref-dev-instance]: /docs/deployment/cloud/deployment-types#shared
+[ref-prod-cluster]: /docs/deployment/cloud/deployment-types#dedicated
+[ref-multi-cluster]: /docs/deployment/cloud/deployment-types#multi-cluster
[ref-pre-aggregations]: /docs/pre-aggregations/using-pre-aggregations
[ref-multitenancy]: /embedding/multitenancy
[ref-context-to-app-id]: /reference/configuration/config#context_to_app_id
diff --git a/docs-mintlify/docs/integrations/semantic-layer-sync/index.mdx b/docs-mintlify/docs/integrations/semantic-layer-sync/index.mdx
index 5f2e9aeeceebe..b3b4bd4d2d53f 100644
--- a/docs-mintlify/docs/integrations/semantic-layer-sync/index.mdx
+++ b/docs-mintlify/docs/integrations/semantic-layer-sync/index.mdx
@@ -339,7 +339,7 @@ any value from the following list: `day`, `hour`, `minute`, or `days`, `hours`,
-Development instances and [auto-suspended][ref-auto-sus] production clusters
+Shared deployments and [auto-suspended][ref-auto-sus] Dedicated deployments
can't run syncs on schedule.
diff --git a/docs-mintlify/docs/pre-aggregations/refreshing-pre-aggregations.mdx b/docs-mintlify/docs/pre-aggregations/refreshing-pre-aggregations.mdx
index 39216a65016c0..c95d3c58f3700 100644
--- a/docs-mintlify/docs/pre-aggregations/refreshing-pre-aggregations.mdx
+++ b/docs-mintlify/docs/pre-aggregations/refreshing-pre-aggregations.mdx
@@ -42,10 +42,10 @@ If you're using [multitenancy][ref-multitenancy], you'd need to deploy several C
clusters (each one per a reduced set of tenants) so there will be multiple refresh
workers which will work only on a subset of your tenants.
-If you're using Cube Cloud, you can use a [production multi-cluster][ref-production-multi-cluster]
+If you're using Cube Cloud, you can use a [Multi-cluster deployment][ref-production-multi-cluster]
that would automatically do this for you.
[ref-multitenancy]: /embedding/multitenancy
[ref-preaggs]: /docs/pre-aggregations/using-pre-aggregations
-[ref-production-multi-cluster]: /docs/deployment/cloud/deployment-types#production-multi-cluster
\ No newline at end of file
+[ref-production-multi-cluster]: /docs/deployment/cloud/deployment-types#multi-cluster
\ No newline at end of file
diff --git a/packages/cubejs-schema-compiler/src/parser/PythonParser.ts b/packages/cubejs-schema-compiler/src/parser/PythonParser.ts
index a26cc6c7dfef1..572509f78e696 100644
--- a/packages/cubejs-schema-compiler/src/parser/PythonParser.ts
+++ b/packages/cubejs-schema-compiler/src/parser/PythonParser.ts
@@ -18,6 +18,12 @@ import Python3Parser, {
Single_string_template_atomContext,
ArglistContext,
CallArgumentsContext,
+ // eslint-disable-next-line camelcase
+ Not_testContext,
+ // eslint-disable-next-line camelcase
+ And_testContext,
+ // eslint-disable-next-line camelcase
+ Or_testContext,
} from './Python3Parser';
import { UserError } from '../compiler/UserError';
import Python3ParserVisitor from './Python3ParserVisitor';
@@ -223,6 +229,21 @@ export class PythonParser {
return { args: children };
} else if (node instanceof LambdefContext) {
return t.arrowFunctionExpression(children[0].args, children[1]);
+ } else if (node instanceof Not_testContext) {
+ if (node.getChildCount() === 1) {
+ return children[0];
+ }
+ return t.unaryExpression('!', children[0]);
+ } else if (node instanceof And_testContext) {
+ if (children.length === 1) {
+ return children[0];
+ }
+ return children.reduce((left, right) => t.logicalExpression('&&', left, right));
+ } else if (node instanceof Or_testContext) {
+ if (children.length === 1) {
+ return children[0];
+ }
+ return children.reduce((left, right) => t.logicalExpression('||', left, right));
} else if (node instanceof ArglistContext) {
return children;
} else {
diff --git a/packages/cubejs-testing/birdbox-fixtures/rbac/cube.js b/packages/cubejs-testing/birdbox-fixtures/rbac/cube.js
index 4a94e5645707b..6a4d8ad267b99 100644
--- a/packages/cubejs-testing/birdbox-fixtures/rbac/cube.js
+++ b/packages/cubejs-testing/birdbox-fixtures/rbac/cube.js
@@ -186,6 +186,42 @@ module.exports = {
},
};
}
+ if (user === 'region_user') {
+ if (password && password !== 'region_user_password') {
+ throw new Error(`Password doesn't match for ${user}`);
+ }
+ return {
+ password,
+ superuser: false,
+ securityContext: {
+ auth: {
+ username: 'region_user',
+ userAttributes: {
+ allowedProductIds: [1, 2],
+ },
+ roles: [],
+ groups: ['user_group', 'region_group'],
+ },
+ },
+ };
+ }
+ if (user === 'region_user_no_filter') {
+ if (password && password !== 'region_user_no_filter_password') {
+ throw new Error(`Password doesn't match for ${user}`);
+ }
+ return {
+ password,
+ superuser: false,
+ securityContext: {
+ auth: {
+ username: 'region_user_no_filter',
+ userAttributes: {},
+ roles: [],
+ groups: ['user_group'],
+ },
+ },
+ };
+ }
if (user === 'sc_test') {
if (password && password !== 'sc_test_password') {
throw new Error(`Password doesn't match for ${user}`);
diff --git a/packages/cubejs-testing/birdbox-fixtures/rbac/model/cubes/region_test.yaml b/packages/cubejs-testing/birdbox-fixtures/rbac/model/cubes/region_test.yaml
new file mode 100644
index 0000000000000..8e4406b849f41
--- /dev/null
+++ b/packages/cubejs-testing/birdbox-fixtures/rbac/model/cubes/region_test.yaml
@@ -0,0 +1,24 @@
+cubes:
+ - name: region_test
+ sql_table: public.line_items
+
+ measures:
+ - name: count
+ type: count
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: product_id
+ sql: product_id
+ type: number
+
+ access_policy:
+ - role: "*"
+ member_level:
+ includes: "*"
+ row_level:
+ allow_all: true
diff --git a/packages/cubejs-testing/birdbox-fixtures/rbac/model/views/region_test_view.yaml b/packages/cubejs-testing/birdbox-fixtures/rbac/model/views/region_test_view.yaml
new file mode 100644
index 0000000000000..13337e94b66d7
--- /dev/null
+++ b/packages/cubejs-testing/birdbox-fixtures/rbac/model/views/region_test_view.yaml
@@ -0,0 +1,24 @@
+views:
+ - name: region_test_view
+ cubes:
+ - join_path: region_test
+ includes: "*"
+ access_policy:
+ - group: user_group
+ conditions:
+ - if: "{ security_context.auth.groups and security_context.auth.groups.includes('region_group') }"
+ member_level:
+ includes: "*"
+ row_level:
+ filters:
+ - member: product_id
+ operator: equals
+ values: security_context.auth.userAttributes.allowedProductIds
+
+ - group: user_group
+ conditions:
+ - if: "{ not (security_context.auth.groups and security_context.auth.groups.includes('region_group')) }"
+ member_level:
+ includes: "*"
+ row_level:
+ allow_all: true
diff --git a/packages/cubejs-testing/test/smoke-rbac.test.ts b/packages/cubejs-testing/test/smoke-rbac.test.ts
index dced4c3a8a706..7599c570cc099 100644
--- a/packages/cubejs-testing/test/smoke-rbac.test.ts
+++ b/packages/cubejs-testing/test/smoke-rbac.test.ts
@@ -1059,6 +1059,77 @@ describe('Cube RBAC Engine', () => {
});
});
+ /**
+ * Group-based conditional row filtering test.
+ *
+ * A view (region_test_view) wraps the region_test cube (backed by
+ * line_items). A single access policy for "user_group" uses conditions
+ * to check security_context.auth.groups for "region_group" membership:
+ * - If groups.includes('region_group') is true, the first policy
+ * matches and filters rows by product_id using allowedProductIds.
+ * - If !groups.includes('region_group'), the second policy matches
+ * and grants allowAll.
+ *
+ * The conditions are mutually exclusive (includes vs !includes) so
+ * only one policy matches per user, avoiding the union-overlap
+ * problem. A user with both user_group and region_group is correctly
+ * filtered because the condition on the first policy evaluates to
+ * true, and the condition on the second evaluates to false.
+ *
+ * Two users:
+ * - region_user: groups = ['user_group', 'region_group'],
+ * allowedProductIds = [1, 2]
+ * → sees only rows with product_id in [1, 2]
+ * - region_user_no_filter: groups = ['user_group']
+ * → sees all rows
+ */
+ describe('RBAC via SQL API region group conditional row filter', () => {
+ let regionConn: PgClient;
+ let noFilterConn: PgClient;
+
+ beforeAll(async () => {
+ regionConn = await createPostgresClient('region_user', 'region_user_password');
+ noFilterConn = await createPostgresClient('region_user_no_filter', 'region_user_no_filter_password');
+ });
+
+ afterAll(async () => {
+ await regionConn.end();
+ await noFilterConn.end();
+ }, JEST_AFTER_ALL_DEFAULT_TIMEOUT);
+
+ test('user with region_group sees only rows matching their allowed product IDs', async () => {
+ const res = await regionConn.query(
+ 'SELECT * FROM region_test_view ORDER BY id LIMIT 50'
+ );
+ expect(res.rows.length).toBeGreaterThan(0);
+ for (const row of res.rows) {
+ expect([1, 2]).toContain(row.product_id);
+ }
+ });
+
+ test('user without region_group sees all rows (no row filter)', async () => {
+ const res = await noFilterConn.query(
+ 'SELECT * FROM region_test_view ORDER BY id LIMIT 50'
+ );
+ expect(res.rows.length).toBeGreaterThan(0);
+ const productIds = new Set(res.rows.map((r: any) => r.product_id));
+ expect(productIds.size).toBeGreaterThan(2);
+ });
+
+ test('filtered user count is less than unfiltered user count', async () => {
+ const filteredRes = await regionConn.query(
+ 'SELECT MEASURE(count) as cnt FROM region_test_view'
+ );
+ const unfilteredRes = await noFilterConn.query(
+ 'SELECT MEASURE(count) as cnt FROM region_test_view'
+ );
+ const filteredCount = Number(filteredRes.rows[0].cnt);
+ const unfilteredCount = Number(unfilteredRes.rows[0].cnt);
+ expect(filteredCount).toBeGreaterThan(0);
+ expect(unfilteredCount).toBeGreaterThan(filteredCount);
+ });
+ });
+
describe('RBAC via REST API', () => {
let client: CubeApi;
let defaultClient: CubeApi;
@@ -126,9 +126,9 @@ configuration** (e.g., turn it off or increase the threshold so that API
instances suspend less frequently), **identify [multitenancy][ref-multitenancy]
misconfiguration** (e.g., suboptimal bucketing via
[`context_to_app_id`][ref-context-to-app-id]), or
-**consider using a [multi-cluster deployment][ref-multi-cluster]** to
-distribute requests to different tenants over a number of Production
-Cluster deployments.
+**consider using a [Multi-cluster deployment][ref-multi-cluster]** to
+distribute requests to different tenants over a number of Dedicated
+deployments.
### Cube Store
@@ -176,9 +176,9 @@ for queries and jobs.
[ref-scalability-api]: /docs/deployment/cloud/scalability#auto-scaling-of-api-instances
[ref-scalability-cube-store]: /docs/deployment/cloud/scalability#sizing-cube-store-workers
[ref-auto-sus]: /docs/deployment/cloud/auto-suspension
-[ref-dev-instance]: /docs/deployment/cloud/deployment-types#development-instance
-[ref-prod-cluster]: /docs/deployment/cloud/deployment-types#production-cluster
-[ref-multi-cluster]: /docs/deployment/cloud/deployment-types#production-multi-cluster
+[ref-dev-instance]: /docs/deployment/cloud/deployment-types#shared
+[ref-prod-cluster]: /docs/deployment/cloud/deployment-types#dedicated
+[ref-multi-cluster]: /docs/deployment/cloud/deployment-types#multi-cluster
[ref-pre-aggregations]: /docs/pre-aggregations/using-pre-aggregations
[ref-multitenancy]: /embedding/multitenancy
[ref-context-to-app-id]: /reference/configuration/config#context_to_app_id
diff --git a/docs-mintlify/docs/integrations/semantic-layer-sync/index.mdx b/docs-mintlify/docs/integrations/semantic-layer-sync/index.mdx
index 5f2e9aeeceebe..b3b4bd4d2d53f 100644
--- a/docs-mintlify/docs/integrations/semantic-layer-sync/index.mdx
+++ b/docs-mintlify/docs/integrations/semantic-layer-sync/index.mdx
@@ -339,7 +339,7 @@ any value from the following list: `day`, `hour`, `minute`, or `days`, `hours`,
-Development instances and [auto-suspended][ref-auto-sus] production clusters
+Shared deployments and [auto-suspended][ref-auto-sus] Dedicated deployments
can't run syncs on schedule.
diff --git a/docs-mintlify/docs/pre-aggregations/refreshing-pre-aggregations.mdx b/docs-mintlify/docs/pre-aggregations/refreshing-pre-aggregations.mdx
index 39216a65016c0..c95d3c58f3700 100644
--- a/docs-mintlify/docs/pre-aggregations/refreshing-pre-aggregations.mdx
+++ b/docs-mintlify/docs/pre-aggregations/refreshing-pre-aggregations.mdx
@@ -42,10 +42,10 @@ If you're using [multitenancy][ref-multitenancy], you'd need to deploy several C
clusters (each one per a reduced set of tenants) so there will be multiple refresh
workers which will work only on a subset of your tenants.
-If you're using Cube Cloud, you can use a [production multi-cluster][ref-production-multi-cluster]
+If you're using Cube Cloud, you can use a [Multi-cluster deployment][ref-production-multi-cluster]
that would automatically do this for you.
[ref-multitenancy]: /embedding/multitenancy
[ref-preaggs]: /docs/pre-aggregations/using-pre-aggregations
-[ref-production-multi-cluster]: /docs/deployment/cloud/deployment-types#production-multi-cluster
\ No newline at end of file
+[ref-production-multi-cluster]: /docs/deployment/cloud/deployment-types#multi-cluster
\ No newline at end of file
diff --git a/packages/cubejs-schema-compiler/src/parser/PythonParser.ts b/packages/cubejs-schema-compiler/src/parser/PythonParser.ts
index a26cc6c7dfef1..572509f78e696 100644
--- a/packages/cubejs-schema-compiler/src/parser/PythonParser.ts
+++ b/packages/cubejs-schema-compiler/src/parser/PythonParser.ts
@@ -18,6 +18,12 @@ import Python3Parser, {
Single_string_template_atomContext,
ArglistContext,
CallArgumentsContext,
+ // eslint-disable-next-line camelcase
+ Not_testContext,
+ // eslint-disable-next-line camelcase
+ And_testContext,
+ // eslint-disable-next-line camelcase
+ Or_testContext,
} from './Python3Parser';
import { UserError } from '../compiler/UserError';
import Python3ParserVisitor from './Python3ParserVisitor';
@@ -223,6 +229,21 @@ export class PythonParser {
return { args: children };
} else if (node instanceof LambdefContext) {
return t.arrowFunctionExpression(children[0].args, children[1]);
+ } else if (node instanceof Not_testContext) {
+ if (node.getChildCount() === 1) {
+ return children[0];
+ }
+ return t.unaryExpression('!', children[0]);
+ } else if (node instanceof And_testContext) {
+ if (children.length === 1) {
+ return children[0];
+ }
+ return children.reduce((left, right) => t.logicalExpression('&&', left, right));
+ } else if (node instanceof Or_testContext) {
+ if (children.length === 1) {
+ return children[0];
+ }
+ return children.reduce((left, right) => t.logicalExpression('||', left, right));
} else if (node instanceof ArglistContext) {
return children;
} else {
diff --git a/packages/cubejs-testing/birdbox-fixtures/rbac/cube.js b/packages/cubejs-testing/birdbox-fixtures/rbac/cube.js
index 4a94e5645707b..6a4d8ad267b99 100644
--- a/packages/cubejs-testing/birdbox-fixtures/rbac/cube.js
+++ b/packages/cubejs-testing/birdbox-fixtures/rbac/cube.js
@@ -186,6 +186,42 @@ module.exports = {
},
};
}
+ if (user === 'region_user') {
+ if (password && password !== 'region_user_password') {
+ throw new Error(`Password doesn't match for ${user}`);
+ }
+ return {
+ password,
+ superuser: false,
+ securityContext: {
+ auth: {
+ username: 'region_user',
+ userAttributes: {
+ allowedProductIds: [1, 2],
+ },
+ roles: [],
+ groups: ['user_group', 'region_group'],
+ },
+ },
+ };
+ }
+ if (user === 'region_user_no_filter') {
+ if (password && password !== 'region_user_no_filter_password') {
+ throw new Error(`Password doesn't match for ${user}`);
+ }
+ return {
+ password,
+ superuser: false,
+ securityContext: {
+ auth: {
+ username: 'region_user_no_filter',
+ userAttributes: {},
+ roles: [],
+ groups: ['user_group'],
+ },
+ },
+ };
+ }
if (user === 'sc_test') {
if (password && password !== 'sc_test_password') {
throw new Error(`Password doesn't match for ${user}`);
diff --git a/packages/cubejs-testing/birdbox-fixtures/rbac/model/cubes/region_test.yaml b/packages/cubejs-testing/birdbox-fixtures/rbac/model/cubes/region_test.yaml
new file mode 100644
index 0000000000000..8e4406b849f41
--- /dev/null
+++ b/packages/cubejs-testing/birdbox-fixtures/rbac/model/cubes/region_test.yaml
@@ -0,0 +1,24 @@
+cubes:
+ - name: region_test
+ sql_table: public.line_items
+
+ measures:
+ - name: count
+ type: count
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: product_id
+ sql: product_id
+ type: number
+
+ access_policy:
+ - role: "*"
+ member_level:
+ includes: "*"
+ row_level:
+ allow_all: true
diff --git a/packages/cubejs-testing/birdbox-fixtures/rbac/model/views/region_test_view.yaml b/packages/cubejs-testing/birdbox-fixtures/rbac/model/views/region_test_view.yaml
new file mode 100644
index 0000000000000..13337e94b66d7
--- /dev/null
+++ b/packages/cubejs-testing/birdbox-fixtures/rbac/model/views/region_test_view.yaml
@@ -0,0 +1,24 @@
+views:
+ - name: region_test_view
+ cubes:
+ - join_path: region_test
+ includes: "*"
+ access_policy:
+ - group: user_group
+ conditions:
+ - if: "{ security_context.auth.groups and security_context.auth.groups.includes('region_group') }"
+ member_level:
+ includes: "*"
+ row_level:
+ filters:
+ - member: product_id
+ operator: equals
+ values: security_context.auth.userAttributes.allowedProductIds
+
+ - group: user_group
+ conditions:
+ - if: "{ not (security_context.auth.groups and security_context.auth.groups.includes('region_group')) }"
+ member_level:
+ includes: "*"
+ row_level:
+ allow_all: true
diff --git a/packages/cubejs-testing/test/smoke-rbac.test.ts b/packages/cubejs-testing/test/smoke-rbac.test.ts
index dced4c3a8a706..7599c570cc099 100644
--- a/packages/cubejs-testing/test/smoke-rbac.test.ts
+++ b/packages/cubejs-testing/test/smoke-rbac.test.ts
@@ -1059,6 +1059,77 @@ describe('Cube RBAC Engine', () => {
});
});
+ /**
+ * Group-based conditional row filtering test.
+ *
+ * A view (region_test_view) wraps the region_test cube (backed by
+ * line_items). A single access policy for "user_group" uses conditions
+ * to check security_context.auth.groups for "region_group" membership:
+ * - If groups.includes('region_group') is true, the first policy
+ * matches and filters rows by product_id using allowedProductIds.
+ * - If !groups.includes('region_group'), the second policy matches
+ * and grants allowAll.
+ *
+ * The conditions are mutually exclusive (includes vs !includes) so
+ * only one policy matches per user, avoiding the union-overlap
+ * problem. A user with both user_group and region_group is correctly
+ * filtered because the condition on the first policy evaluates to
+ * true, and the condition on the second evaluates to false.
+ *
+ * Two users:
+ * - region_user: groups = ['user_group', 'region_group'],
+ * allowedProductIds = [1, 2]
+ * → sees only rows with product_id in [1, 2]
+ * - region_user_no_filter: groups = ['user_group']
+ * → sees all rows
+ */
+ describe('RBAC via SQL API region group conditional row filter', () => {
+ let regionConn: PgClient;
+ let noFilterConn: PgClient;
+
+ beforeAll(async () => {
+ regionConn = await createPostgresClient('region_user', 'region_user_password');
+ noFilterConn = await createPostgresClient('region_user_no_filter', 'region_user_no_filter_password');
+ });
+
+ afterAll(async () => {
+ await regionConn.end();
+ await noFilterConn.end();
+ }, JEST_AFTER_ALL_DEFAULT_TIMEOUT);
+
+ test('user with region_group sees only rows matching their allowed product IDs', async () => {
+ const res = await regionConn.query(
+ 'SELECT * FROM region_test_view ORDER BY id LIMIT 50'
+ );
+ expect(res.rows.length).toBeGreaterThan(0);
+ for (const row of res.rows) {
+ expect([1, 2]).toContain(row.product_id);
+ }
+ });
+
+ test('user without region_group sees all rows (no row filter)', async () => {
+ const res = await noFilterConn.query(
+ 'SELECT * FROM region_test_view ORDER BY id LIMIT 50'
+ );
+ expect(res.rows.length).toBeGreaterThan(0);
+ const productIds = new Set(res.rows.map((r: any) => r.product_id));
+ expect(productIds.size).toBeGreaterThan(2);
+ });
+
+ test('filtered user count is less than unfiltered user count', async () => {
+ const filteredRes = await regionConn.query(
+ 'SELECT MEASURE(count) as cnt FROM region_test_view'
+ );
+ const unfilteredRes = await noFilterConn.query(
+ 'SELECT MEASURE(count) as cnt FROM region_test_view'
+ );
+ const filteredCount = Number(filteredRes.rows[0].cnt);
+ const unfilteredCount = Number(unfilteredRes.rows[0].cnt);
+ expect(filteredCount).toBeGreaterThan(0);
+ expect(unfilteredCount).toBeGreaterThan(filteredCount);
+ });
+ });
+
describe('RBAC via REST API', () => {
let client: CubeApi;
let defaultClient: CubeApi;