diff --git a/docs-mintlify/docs.json b/docs-mintlify/docs.json
index d5b1378c8697b..d9bfe80ad087f 100644
--- a/docs-mintlify/docs.json
+++ b/docs-mintlify/docs.json
@@ -81,20 +81,24 @@
"pages": [
"docs/data-modeling/overview",
{
- "group": "Concepts",
- "root": "docs/data-modeling/concepts/index",
+ "group": "Views",
+ "root": "docs/data-modeling/views",
"pages": [
- "docs/data-modeling/concepts/syntax",
- "docs/data-modeling/concepts/calculated-members",
- "docs/data-modeling/concepts/multi-stage-calculations",
- "docs/data-modeling/concepts/working-with-joins",
- "docs/data-modeling/concepts/code-reusability-extending-cubes",
- "docs/data-modeling/concepts/polymorphic-cubes",
- "docs/data-modeling/concepts/multi-fact-queries",
- "docs/data-modeling/concepts/data-blending"
+ "docs/data-modeling/multi-fact-views"
]
},
+ {
+ "group": "Cubes",
+ "root": "docs/data-modeling/cubes",
+ "pages": [
+ "docs/data-modeling/extending-cubes"
+ ]
+ },
+ "docs/data-modeling/joins",
+ "docs/data-modeling/measures",
+ "docs/data-modeling/dimensions",
"docs/data-modeling/ai-context",
+ "docs/data-modeling/concepts/syntax",
{
"group": "Access Control",
"pages": [
@@ -585,7 +589,8 @@
"recipes/data-modeling/cohort-retention",
"recipes/data-modeling/xirr",
"recipes/data-modeling/dbt",
- "recipes/data-modeling/custom-order"
+ "recipes/data-modeling/custom-order",
+ "recipes/data-modeling/polymorphic-cubes"
]
}
]
diff --git a/docs-mintlify/docs/data-modeling/access-control/member-level-security.mdx b/docs-mintlify/docs/data-modeling/access-control/member-level-security.mdx
index 75a3eeaf3197f..58ec6766cbf37 100644
--- a/docs-mintlify/docs/data-modeling/access-control/member-level-security.mdx
+++ b/docs-mintlify/docs/data-modeling/access-control/member-level-security.mdx
@@ -145,8 +145,8 @@ them entirely, see [data masking][ref-data-masking] in access policies.
[ref-data-modeling-concepts]: /docs/data-modeling/concepts
[ref-apis]: /reference
-[ref-cubes]: /docs/data-modeling/concepts#cubes
-[ref-views]: /docs/data-modeling/concepts#views
+[ref-cubes]: /docs/data-modeling/cubes
+[ref-views]: /docs/data-modeling/views
[ref-dap]: /docs/data-modeling/access-control/data-access-policies
[ref-ref-cubes]: /reference/data-modeling/cube
[ref-ref-views]: /reference/data-modeling/view
diff --git a/docs-mintlify/docs/data-modeling/access-control/row-level-security.mdx b/docs-mintlify/docs/data-modeling/access-control/row-level-security.mdx
index 5f66ffa5a2ba7..72345f1791491 100644
--- a/docs-mintlify/docs/data-modeling/access-control/row-level-security.mdx
+++ b/docs-mintlify/docs/data-modeling/access-control/row-level-security.mdx
@@ -65,8 +65,8 @@ cube(`orders`, {
[ref-data-modeling-concepts]: /docs/data-modeling/concepts
[ref-apis]: /reference
-[ref-cubes]: /docs/data-modeling/concepts#cubes
-[ref-views]: /docs/data-modeling/concepts#views
+[ref-cubes]: /docs/data-modeling/cubes
+[ref-views]: /docs/data-modeling/views
[ref-cubes-sql]: /reference/data-modeling/cube#sql
[ref-dynamic-data-modeling]: /docs/data-modeling/dynamic
[ref-dap]: /docs/data-modeling/access-control/data-access-policies
diff --git a/docs-mintlify/docs/data-modeling/concepts/calculated-members.mdx b/docs-mintlify/docs/data-modeling/concepts/calculated-members.mdx
deleted file mode 100644
index 62257a87e3cc9..0000000000000
--- a/docs-mintlify/docs/data-modeling/concepts/calculated-members.mdx
+++ /dev/null
@@ -1,724 +0,0 @@
----
-title: Calculated measures and dimensions
-description: Patterns for measures and dimensions built from SQL expressions, cross-member references, and subqueries—including ratios, proxies, and decomposition for pre-aggregations.
----
-
-Often, dimensions are mapped to table columns and measures are defined as
-aggregations of top of table columns. However, measures and dimensions can also
-[reference][ref-references] other members of the same or other cubes, use [SQL
-expressions][ref-sql-expressions], and perform calculations involving other measures
-and dimensions.
-
-Most common patterns are known as [calculated measures](#calculated-measures),
-[proxy dimensions](#proxy-dimensions), and [subquery dimensions](#subquery-dimensions).
-
-## Calculated measures
-
-**Calculated measures perform calculations on other measures using SQL functions and
-operators.** They provide a way to decompose complex measures (e.g., ratios or percents)
-into formulas that involve simpler measures. Also, calculated measures [can
-help][ref-decomposition-recipe] to use [non-additive][ref-non-additive] measures with
-pre-aggregations.
-
-### Members of the same cube
-
-In the following example, the `completed_ratio` measure is calculated as a division of
-`completed_count` by total `count`. Note that the result is also multiplied by `1.0`
-since [integer division in SQL][link-postgres-division] would otherwise produce an
-integer value.
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- sql: |
- SELECT 1 AS id, 'processing' AS status UNION ALL
- SELECT 2 AS id, 'completed' AS status UNION ALL
- SELECT 3 AS id, 'completed' AS status
-
- measures:
- - name: count
- type: count
-
- - name: completed_count
- type: count
- filters:
- - sql: "{CUBE}.status = 'completed'"
-
- - name: completed_ratio
- sql: "1.0 * {completed_count} / {count}"
- type: number
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- sql: `
- SELECT 1 AS id, 'processing' AS status UNION ALL
- SELECT 2 AS id, 'completed' AS status UNION ALL
- SELECT 3 AS id, 'completed' AS status
- `,
-
- measures: {
- count: {
- type: `count`
- },
-
- completed_count: {
- type: `count`,
- filters: [{
- sql: `${CUBE}.status = 'completed'`
- }]
- },
-
- completed_ratio: {
- sql: `1.0 * ${completed_count} / ${count}`,
- type: `number`
- }
- }
-})
-```
-
-
-
-If you query for `completed_ratio`, Cube will generate the following SQL:
-
-```sql
-SELECT
- 1.0 * COUNT(
- CASE WHEN ("orders".status = 'completed') THEN 1 END
- ) / COUNT(*) "orders__completed_ratio"
-FROM (
- SELECT 1 AS id, 'processing' AS status UNION ALL
- SELECT 2 AS id, 'completed' AS status UNION ALL
- SELECT 3 AS id, 'completed' AS status
-) AS "orders"
-```
-
-### Members of other cubes
-
-If you have `first_cube` that is [joined][ref-joins] to `second_cube`, you can define a
-calculated measure that references measures from both `first_cube` and `second_cube`.
-When you query for this calculated measure, Cube will transparently generate SQL with
-necessary joins.
-
-In the following example, the `orders.purchases_to_users_ratio` measure references the
-`purchases` measure from the `orders` cube and the `count` measure from the `users` cube:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- sql: >
- SELECT 1 AS id, 11 AS user_id, 'processing' AS status UNION ALL
- SELECT 2 AS id, 11 AS user_id, 'completed' AS status UNION ALL
- SELECT 3 AS id, 11 AS user_id, 'completed' AS status
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- measures:
- - name: purchases
- type: count
- filters:
- - sql: "{CUBE}.status = 'completed'"
-
- - name: users
- sql: >
- SELECT 11 AS id, 'Alice' AS name UNION ALL
- SELECT 12 AS id, 'Bob' AS name UNION ALL
- SELECT 13 AS id, 'Eve' AS name
-
- joins:
- - name: orders
- sql: "{CUBE}.id = {orders}.user_id"
- relationship: one_to_many
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- measures:
- - name: count
- type: count
-
- - name: purchases_to_users_ratio
- sql: "1.0 * {orders.purchases} / {CUBE.count}"
- type: number
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- sql: `
- SELECT 1 AS id, 11 AS user_id, 'processing' AS status UNION ALL
- SELECT 2 AS id, 11 AS user_id, 'completed' AS status UNION ALL
- SELECT 3 AS id, 11 AS user_id, 'completed' AS status
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- }
- },
-
- measures: {
- purchases: {
- type: `count`,
- filters: [{
- sql: `${CUBE}.status = 'completed'`
- }]
- }
- }
-})
-
-cube(`users`, {
- sql: `
- SELECT 11 AS id, 'Alice' AS name UNION ALL
- SELECT 12 AS id, 'Bob' AS name UNION ALL
- SELECT 13 AS id, 'Eve' AS name
- `,
-
- joins: {
- orders: {
- sql: `${CUBE}.id = ${orders}.user_id`,
- relationship: `one_to_many`
- }
- },
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- }
- },
-
- measures: {
- count: {
- type: `count`
- },
-
- purchases_to_users_ratio: {
- sql: `100.0 * ${orders.purchases} / ${CUBE.count}`,
- type: `number`,
- format: `percent`
- }
- }
-})
-```
-
-
-
-If you query for `users.purchases_to_users_ratio`, Cube will generate the following SQL:
-
-```sql
-SELECT
- 1.0 * COUNT(
- CASE
- WHEN ("orders".status = 'completed') THEN "orders".id
- END
- ) / COUNT(DISTINCT "users".id) "users__purchases_to_users_ratio"
-FROM (
- SELECT 11 AS id, 'Alice' AS name UNION ALL
- SELECT 12 AS id, 'Bob' AS name UNION ALL
- SELECT 13 AS id, 'Eve' AS name
-) AS "users"
-LEFT JOIN (
- SELECT 1 AS id, 11 AS user_id, 'processing' AS status UNION ALL
- SELECT 2 AS id, 11 AS user_id, 'completed' AS status UNION ALL
- SELECT 3 AS id, 11 AS user_id, 'completed' AS status
-) AS "orders" ON "users".id = "orders".user_id
-```
-
-## Proxy dimensions
-
-**Proxy dimensions reference dimensions from the same cube or other cubes.**
-Proxy dimensions are convenient for reusing existing dimensions when defining
-new ones.
-
-### Members of the same cube
-
-If you have a dimension with a non-trivial definition, you can reference that
-dimension to reuse the existing definition and reduce code duplication.
-
-In the following example, the `full_name` dimension references `initials` and
-`last_name` dimensions of the same cube:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: users
- sql_table: users
-
- dimensions:
- - name: initials
- sql: "SUBSTR(first_name, 1, 1)"
- type: string
-
- - name: last_name
- sql: "UPPER(last_name)"
- type: string
-
- - name: full_name
- sql: "{initials} || '. ' || {last_name}"
- type: string
-```
-
-```javascript title="JavaScript"
-cube(`users`, {
- sql_table: `users`,
-
- dimensions: {
- initials: {
- sql: `SUBSTR(first_name, 1, 1)`,
- type: `string`
- },
-
- last_name: {
- sql: `UPPER(last_name)`,
- type: `string`
- },
-
- full_name: {
- sql: `${initials} || '. ' || ${last_name}`,
- type: `string`
- }
- }
-})
-```
-
-
-
-If you query for `users.full_name`, Cube will generate the following SQL:
-
-```sql
-SELECT
- SUBSTR(first_name, 1, 1) || '. ' || UPPER(last_name) "users__full_name"
-FROM
- users AS "users"
-GROUP BY
- 1
-```
-
-### Members of other cubes
-
-If you have `first_cube` that is [joined][ref-joins] to `second_cube`, you can use a
-proxy dimension to bring `second_cube.dimension` to `first_cube` as `dimension` (or
-under a different name). When you query for a proxy dimension, Cube will transparently
-generate SQL with necessary joins.
-
-In the following example, `orders.user_name` is a proxy dimension that brings the
-`users.name` dimension to `orders`. You can also see that there's a join relationship
-between `orders` and `users`:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- sql: |
- SELECT 1 AS id, 1 AS user_id UNION ALL
- SELECT 2 AS id, 1 AS user_id UNION ALL
- SELECT 3 AS id, 2 AS user_id
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: user_name
- sql: "{users.name}"
- type: string
-
- measures:
- - name: count
- type: count
-
- joins:
- - name: users
- sql: "{users}.id = {orders}.user_id"
- relationship: one_to_many
-
- - name: users
- sql: |
- SELECT 1 AS id, 'Alice' AS name UNION ALL
- SELECT 2 AS id, 'Bob' AS name
-
- dimensions:
- - name: name
- sql: name
- type: string
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- sql: `
- SELECT 1 AS id, 1 AS user_id UNION ALL
- SELECT 2 AS id, 1 AS user_id UNION ALL
- SELECT 3 AS id, 2 AS user_id
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- user_name: {
- sql: `${users.name}`,
- type: `string`
- }
- },
-
- measures: {
- count: {
- type: `count`
- }
- },
-
- joins: {
- users: {
- sql: `${users}.id = ${orders}.user_id`,
- relationship: `one_to_many`
- }
- }
-})
-
-cube(`users`, {
- sql: `
- SELECT 1 AS id, 'Alice' AS name UNION ALL
- SELECT 2 AS id, 'Bob' AS name
- `,
-
- dimensions: {
- name: {
- sql: `name`,
- type: `string`
- }
- }
-})
-```
-
-
-
-If you query for `orders.user_name` and `orders.count`, Cube will generate the
-following SQL:
-
-```sql
-SELECT
- "users".name "orders__user_name",
- COUNT(DISTINCT "orders".id) "orders__count"
-FROM (
- SELECT 1 AS id, 1 AS user_id UNION ALL
- SELECT 2 AS id, 1 AS user_id UNION ALL
- SELECT 3 AS id, 2 AS user_id
-) AS "orders"
-LEFT JOIN (
- SELECT 1 AS id, 'Alice' AS name UNION ALL
- SELECT 2 AS id, 'Bob' AS name
-) AS "users" ON "users".id = "orders".user_id
-GROUP BY 1
-```
-
-Note that if you query for `orders.user_name` only, Cube will figure out that it's
-equivalent to querying just `users.name` and there's no need to generate a join in SQL:
-
-```sql
-SELECT
- "users".name "orders__user_name"
-FROM (
- SELECT 1 AS id, 'Alice' AS name UNION ALL
- SELECT 2 AS id, 'Bob' AS name
-) AS "users"
-GROUP BY 1
-```
-
-### Time dimension granularity
-
-When referencing a [time dimension][ref-time-dimension] of the same or another
-cube, you can specificy a granularity to refer to a time value with that specific
-granularity. It can be one of the [default granularities][ref-default-granularities]
-(e.g., `year` or `week`) or a [custom granularity][ref-custom-granularities]:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: users
- sql: |
- SELECT '2025-01-01T00:00:00Z' AS created_at UNION ALL
- SELECT '2025-02-01T00:00:00Z' AS created_at UNION ALL
- SELECT '2025-03-01T00:00:00Z' AS created_at
-
- dimensions:
- - name: created_at
- sql: created_at
- type: time
-
- granularities:
- - name: sunday_week
- interval: 1 week
- offset: -1 day
-
- - name: created_at__year
- sql: "{created_at.year}"
- type: time
-
- - name: created_at__sunday_week
- sql: "{created_at.sunday_week}"
- type: time
-```
-
-```javascript title="JavaScript"
-cube(`users`, {
- sql: `
- SELECT '2025-01-01T00:00:00Z' AS created_at UNION ALL
- SELECT '2025-02-01T00:00:00Z' AS created_at UNION ALL
- SELECT '2025-03-01T00:00:00Z' AS created_at
- `,
-
- dimensions: {
- created_at: {
- sql: `created_at`,
- type: `time`,
-
- granularities: {
- sunday_week: {
- interval: `1 week`,
- offset: `-1 day`
- }
- }
- },
-
- created_at__year: {
- sql: `${created_at.year}`,
- type: `time`
- },
-
- created_at__sunday_week: {
- sql: `${created_at.sunday_week}`,
- type: `time`
- }
- }
-})
-```
-
-
-
-If you query for `users.created_at`, `users.created_at__sunday_week`, and
-`users.created_at__year` dimensions, Cube will generate the following SQL:
-
-```sql
-SELECT
- "users".created_at "users__created_at",
- date_trunc('week', ("users".created_at::timestamptz AT TIME ZONE 'UTC') - interval '-1 day') + interval '-1 day' "users__created_at__sunday_week",
- date_trunc('year', ("users".created_at::timestamptz AT TIME ZONE 'UTC')) "users__created_at__year"
-FROM (
- SELECT '2025-01-01T00:00:00Z' AS created_at UNION ALL
- SELECT '2025-02-01T00:00:00Z' AS created_at UNION ALL
- SELECT '2025-03-01T00:00:00Z' AS created_at
-) AS "users"
-GROUP BY 1, 2, 3
-```
-
-## Subquery dimensions
-
-**Subquery dimensions reference measures from other cubes.** Subquery dimensions
-provide a way to define measures that aggregate values of other measures. They can be
-useful to calculate nested and filtered aggregates.
-
-
-
-See the following recipes:
-
-- To learn how to calculate [nested aggregates][ref-nested-aggregates-recipe].
-- To learn how to calculate [filtered aggregates][ref-filtered-aggregates-recipe].
-
-
-
-If you have `first_cube` that is [joined][ref-joins] to `second_cube`, you can use a
-subquery dimension to bring `second_cube.measure` to `first_cube` as `dimension` (or
-under a different name). When you query for a subquery dimension, Cube will
-transparently generate SQL with necessary joins. It works as a [correlated
-subquery][wiki-correlated-subquery] but is implemented via joins for optimal
-performance and portability.
-
-In the following example, `users.order_count` is a subquery dimension that brings the
-`orders.count` measure to `users`. Note that the [`sub_query` parameter][ref-ref-subquery]
-is set to `true` on `users.order_count`. You can also see that there's a join
-relationship between `orders` and `users`:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- sql: |
- SELECT 1 AS id, 1 AS user_id UNION ALL
- SELECT 2 AS id, 1 AS user_id UNION ALL
- SELECT 3 AS id, 2 AS user_id
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- measures:
- - name: count
- type: count
-
- joins:
- - name: users
- sql: "{users}.id = {orders}.user_id"
- relationship: one_to_many
-
- - name: users
- sql: |
- SELECT 1 AS id, 'Alice' AS name UNION ALL
- SELECT 2 AS id, 'Bob' AS name
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: name
- sql: name
- type: string
-
- - name: order_count
- sql: "{orders.count}"
- type: number
- sub_query: true
-
- measures:
- - name: avg_order_count
- sql: "{order_count}"
- type: avg
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- sql: `
- SELECT 1 AS id, 1 AS user_id UNION ALL
- SELECT 2 AS id, 1 AS user_id UNION ALL
- SELECT 3 AS id, 2 AS user_id
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- }
- },
-
- measures: {
- count: {
- type: `count`
- }
- },
-
- joins: {
- users: {
- sql: `${users}.id = ${orders}.user_id`,
- relationship: `one_to_many`
- }
- }
-})
-
-cube(`users`, {
- sql: `
- SELECT 1 AS id, 'Alice' AS name UNION ALL
- SELECT 2 AS id, 'Bob' AS name
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- name: {
- sql: `name`,
- type: `string`
- },
-
- order_count: {
- sql: `${orders.count}`,
- type: `number`,
- sub_query: true
- }
- },
-
- measures: {
- avg_order_count: {
- sql: `${order_count}`,
- type: `avg`
- }
- }
-})
-```
-
-
-
-You can reference subquery dimensions in measures just like usual dimensions. In the
-example above, the `avg_order_count` measure performs an aggregation on `order_count`.
-
-If you query for `users.name` and `users.order_count`, Cube will generate the
-following SQL:
-
-```sql
-SELECT
- "users".name "users__name",
- "users__order_count" "users__order_count"
-FROM (
- SELECT 1 AS id, 'Alice' AS name UNION ALL
- SELECT 2 AS id, 'Bob' AS name
-) AS "users"
-LEFT JOIN (
- SELECT
- "users_order_count_subquery__users".id "users__id",
- count(distinct "users_order_count_subquery__orders".id) "users__order_count"
- FROM (
- SELECT 1 AS id, 1 AS user_id UNION ALL
- SELECT 2 AS id, 1 AS user_id UNION ALL
- SELECT 3 AS id, 2 AS user_id
- ) AS "users_order_count_subquery__orders"
- LEFT JOIN (
- SELECT 1 AS id, 'Alice' AS name UNION ALL
- SELECT 2 AS id, 'Bob' AS name
- ) AS "users_order_count_subquery__users" ON "users_order_count_subquery__users".id = "users_order_count_subquery__orders".user_id
- GROUP BY 1
-) AS "users_order_count_subquery" ON "users_order_count_subquery"."users__id" = "users".id
-GROUP BY 1, 2
-```
-
-
-[ref-references]: /docs/data-modeling/syntax#references
-[ref-sql-expressions]: /docs/data-modeling/syntax#sql-expressions
-[ref-joins]: /docs/data-modeling/concepts/working-with-joins
-[ref-ref-subquery]: /reference/data-modeling/dimensions#sub_query
-[ref-decomposition-recipe]: /recipes/pre-aggregations/non-additivity#decomposing-into-a-formula-with-additive-measures
-[ref-nested-aggregates-recipe]: /recipes/data-modeling/nested-aggregates
-[ref-filtered-aggregates-recipe]: /recipes/data-modeling/filtered-aggregates
-[ref-non-additive]: /docs/data-modeling/concepts#measure-additivity
-[link-postgres-division]: https://www.postgresql.org/docs/current/functions-math.html#FUNCTIONS-MATH
-[wiki-correlated-subquery]: https://en.wikipedia.org/wiki/Correlated_subquery
-[ref-time-dimension]: /reference/data-modeling/dimensions#type
-[ref-default-granularities]: /docs/data-modeling/concepts#time-dimensions
-[ref-custom-granularities]: /reference/data-modeling/dimensions#granularities
\ No newline at end of file
diff --git a/docs-mintlify/docs/data-modeling/concepts/calendar-cubes.mdx b/docs-mintlify/docs/data-modeling/concepts/calendar-cubes.mdx
index 524fc7fbedec8..a7f952f0f68fa 100644
--- a/docs-mintlify/docs/data-modeling/concepts/calendar-cubes.mdx
+++ b/docs-mintlify/docs/data-modeling/concepts/calendar-cubes.mdx
@@ -470,8 +470,8 @@ When querying `sales.revenue` by `custom_calendar.date` with monthly granularity
expression in the generated SQL.
-[ref-time-shift]: /docs/data-modeling/concepts/multi-stage-calculations#time-shift
-[ref-time-dimension]: /docs/data-modeling/concepts#time-dimensions
+[ref-time-shift]: /docs/data-modeling/measures#time-shift
+[ref-time-dimension]: /docs/data-modeling/dimensions#time-dimensions
[ref-granularities]: /reference/data-modeling/dimensions#granularities
[ref-cubes]: /reference/data-modeling/cube
[ref-cubes-calendar]: /reference/data-modeling/cube#calendar
diff --git a/docs-mintlify/docs/data-modeling/concepts/index.mdx b/docs-mintlify/docs/data-modeling/concepts/index.mdx
deleted file mode 100644
index 6a3096829bf4b..0000000000000
--- a/docs-mintlify/docs/data-modeling/concepts/index.mdx
+++ /dev/null
@@ -1,860 +0,0 @@
----
-title: Concepts
-description: Learn foundational OLAP concepts like cubes, dimensions, measures, and joins used in Cube data modeling.
----
-
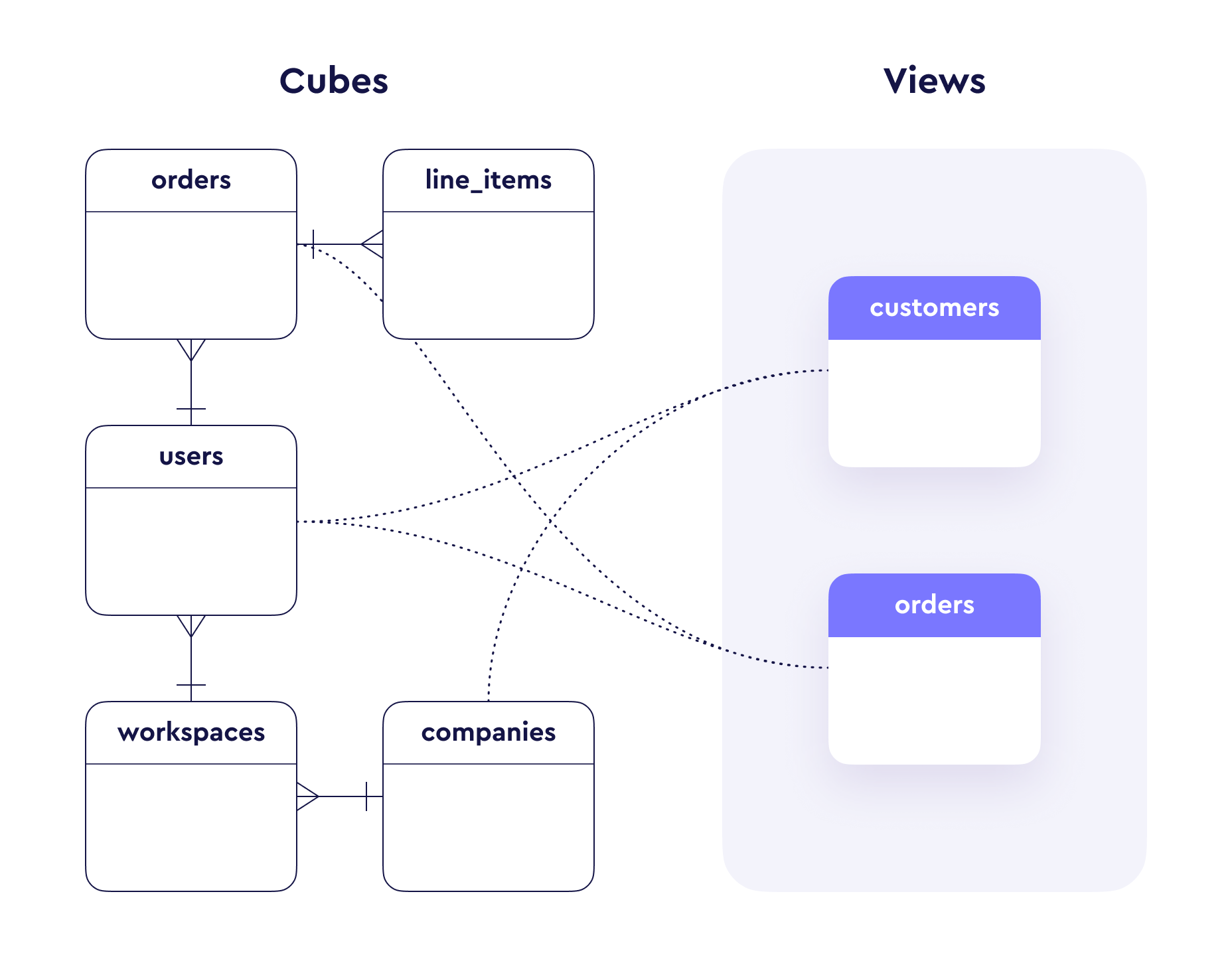
-Cube's key concepts are [cubes](#cubes), [views](#views), and members
-([measures](#measures), [dimensions](#dimensions)). This page is intended
-for both newcomers and regular users to refresh their understanding.
-
-
-  -
-
-We'll use a sample e-commerce database with two tables, `orders` and
-`line_items` to illustrate the concepts throughout this page:
-
-**`orders`**
-
-| **id** | **status** | **completed_at** | **created_at** |
-| ------ | ---------- | -------------------------- | -------------------------- |
-| 1 | completed | 2019-01-05 00:00:00.000000 | 2019-01-02 00:00:00.000000 |
-| 2 | shipped | 2019-01-17 00:00:00.000000 | 2019-01-02 00:00:00.000000 |
-| 3 | completed | 2019-01-27 00:00:00.000000 | 2019-01-02 00:00:00.000000 |
-| 4 | shipped | 2019-01-09 00:00:00.000000 | 2019-01-02 00:00:00.000000 |
-| 5 | processing | 2019-01-29 00:00:00.000000 | 2019-01-02 00:00:00.000000 |
-
-**`line_items`**
-
-| **id** | **product_id** | **order_id** | **quantity** | **price** | **created_at** |
-| ------ | -------------- | ------------ | ------------ | --------- | -------------------------- |
-| 1 | 31 | 1 | 1 | 275 | 2019-01-31 00:00:00.000000 |
-| 2 | 49 | 2 | 6 | 248 | 2021-01-20 00:00:00.000000 |
-| 3 | 89 | 3 | 6 | 197 | 2021-11-25 00:00:00.000000 |
-| 4 | 71 | 4 | 8 | 223 | 2019-12-23 00:00:00.000000 |
-| 5 | 64 | 5 | 5 | 75 | 2019-04-20 00:00:00.000000 |
-
-We'll be following the [entity-first](#entity-first-approach) approach to
-designing the data model.
-
-
-
-See [this recipe][ref-entities-vs-metrics-recipe] to learn about entity-first and
-metrics-first approaches.
-
-
-
-## Cubes
-
-_Cubes_ represent datasets in Cube and are conceptually similar to [views in
-SQL][wiki-view-sql]. Cubes are usually declared in separate files with one
-cube per file. Typically, a cube points to a single table in
-your [data source][ref-data-sources] using the [`sql_table` property][ref-schema-ref-sql-table]:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- sql_table: orders
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- sql_table: `orders`
-})
-```
-
-
-
-
-
-If you're using dbt, see [this recipe][ref-cube-with-dbt] to streamline defining cubes
-on top of dbt models.
-
-
-
-You can also use the [`sql` property][ref-schema-ref-sql] to accommodate more
-complex SQL queries:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- sql: |
- SELECT *
- FROM orders, line_items
- WHERE orders.id = line_items.order_id
-
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- sql: `
- SELECT *
- FROM orders, line_items
- WHERE orders.id = line_items.order_id
- `
-})
-```
-
-
-
-Each cube contains the definitions of its _members_: [dimensions](#dimensions),
-[measures](#measures), and [segments](#segments). You can control the access to
-cubes and their members by configuring the [member-level security][ref-mls].
-
-[Joins](#joins) are used to define relations between cubes.
-[Pre-aggregations](#pre-aggregations) are used to accelerate queries to cubes.
-Cubes and their members can be further referenced by [views](#views).
-
-Note that cubes support [extension][ref-extending-cubes],
-[polymorphism][ref-polymorphic-cubes], and [data blending][ref-data-blending].
-Custom calendars, such as retail calendars, can be implemented using [calendar
-cubes][ref-calendar-cubes].
-
-Cubes can be defined statically and you can also build [dynamic data
-models][ref-dynamic-data-models].
-
-
-
-Cube supports data models that consist of thousands of cubes and views.
-For large [multi-tenancy][ref-multitenancy] configurations, e.g., with more than
-100 tenants, consider using a [multi-cluster deployment][ref-pmc].
-
-
-
-
-
-See the reference documentaton for the full list of cube [parameters][ref-cubes].
-
-
-
-## Views
-
-_Views_ sit on top of the data graph of cubes and create a facade of your whole
-data model with which data consumers can interact. They are useful for defining
-metrics, managing governance and data access, and controlling ambiguous join
-paths.
-
-Views do **not** define their own members. Instead, they reference cubes by
-specific join paths and include their members.
-
-In the example below, we create the `orders` view which includes select members
-from `base_orders`, `products`, and `users` cubes:
-
-
-
-```yaml title="YAML"
-views:
- - name: orders
-
- cubes:
- - join_path: base_orders
- includes:
- - status
- - created_date
- - total_amount
- - total_amount_shipped
- - count
- - average_order_value
-
- - join_path: base_orders.line_items.products
- includes:
- - name: name
- alias: product
-
- - join_path: base_orders.users
- prefix: true
- includes: "*"
- excludes:
- - company
-```
-
-```javascript title="JavaScript"
-view(`orders`, {
- cubes: [
- {
- join_path: base_orders,
- includes: [
- `status`,
- `created_date`,
- `total_amount`,
- `total_amount_shipped`,
- `count`,
- `average_order_value`
- ]
- },
- {
- join_path: base_orders.line_items.products,
- includes: [
- {
- name: `name`,
- alias: `product`
- }
- ]
- },
- {
- join_path: base_orders.users,
- prefix: true,
- includes: `*`,
- excludes: [`company`]
- }
- ]
-})
-```
-
-
-
-Views do **not** define any [pre-aggregations](#pre-aggregations). Instead,
-they [reuse][ref-matching-preaggs] pre-aggregations from underlying cubes.
-
-View can be defined statically and you can also build [dynamic data
-models][ref-dynamic-data-models].
-
-
-
-See the reference documentaton for the full list of view [parameters][ref-views].
-
-
-
-### Folders
-
-Optionally, members of a view can be organized into [folders][ref-ref-folders].
-Each folder would contain a subset of members of the view.
-
-Cube supports both flat and nested folder structures, which can be used with various
-[visualization tools][ref-viz-tools]. If a specific tool does not support nested folders,
-they will be exposed to such a tool as an equivalent flat structure. Check [APIs &
-Integrations][ref-apis-support] for details on the nested folders support.
-
-## Dimensions
-
-_Dimensions_ represent the properties of a **single** data point in the cube.
-[The `orders` table](#top) contains only dimensions, so representing them in the
-`orders` cube is straightforward:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- # ...
-
- dimensions:
- - name: id
- sql: id
- type: number
- # Here we explicitly let Cube know this field is the primary key
- # This is required for de-duplicating results when using joins
- primary_key: true
-
- - name: status
- sql: status
- type: string
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- // ...
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- // Here we explicitly let Cube know this field is the primary key
- // This is required for de-duplicating results when using joins
- primary_key: true
- },
-
- status: {
- sql: `status`,
- type: `string`
- }
- }
-})
-```
-
-
-
-Note that the `id` dimension is defined as a [primary key][ref-ref-primary-key].
-It is also possible to have more than one primary key dimension in a cube if
-you'd like them all to be parts of a composite key.
-
-[The `line_items` table](#top) also has a couple of dimensions which can be
-represented as follows:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: line_items
- # ...
-
- dimensions:
- - name: id
- sql: id
- type: number
- # Again, we explicitly let Cube know this field is the primary key
- # This is required for de-duplicating results when using joins
- primary_key: true
-
- - name: order_id
- sql: order_id
- type: number
-```
-
-```javascript title="JavaScript"
-cube(`line_items`, {
- // ...
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- // Again, we explicitly let Cube know this field is the primary key
- // This is required for de-duplicating results when using joins
- primary_key: true
- },
-
- order_id: {
- sql: `order_id`,
- type: `number`
- }
- }
-})
-```
-
-
-
-If needed, dimensions can be organized into [hierarchies][ref-ref-hierarchies].
-Also, [proxy dimensions][ref-proxy-dimensions] are helpful for code reusability
-and [subquery dimensions][ref-subquery-dimensions] can be used to join cubes
-implicitly.
-
-
-
-See the reference documentaton for the full list of [dimension parameters][ref-dimensions].
-
-
-
-### Dimension types
-
-Dimensions can be of different types, e.g., `string`, `number`, or `time`. Often,
-data types in SQL are mapped to dimension types in the following way:
-
-| Data type in SQL | Dimension type in Cube |
-| --- | --- |
-| `timestamp`, `date`, `time` | [`time`](/reference/data-modeling/dimensions#type) |
-| `text`, `varchar` | [`string`](/reference/data-modeling/dimensions#type) |
-| `integer`, `bigint`, `decimal` | [`number`](/reference/data-modeling/dimensions#type) |
-| `boolean` | [`boolean`](/reference/data-modeling/dimensions#type) |
-
-
-
-See the [dimension type reference][ref-ref-dimension-types] for details.
-
-
-
-### Time dimensions
-
-Time-based properties are modeled using dimensions of the [`time`
-type][ref-ref-time-dimensions]. They allow grouping the result set by a unit of
-time (e.g., days, weeks, month, etc.), also known as the *time dimension
-granularity*.
-
-The following granularities are available by default for any time dimension:
-`year`, `quarter`, `month`, `week` (starting on Monday), `day`, `hour`, `minute`,
-`second`. You can also define [custom granularities][ref-ref-dimension-granularities]
-and optionally expose them via [proxy dimensions][ref-proxy-granularity] in case
-you need to use weeks starting on Sunday, fiscal years, etc.
-
-
-
-See the following recipes:
-- For a [custom granularity][ref-custom-granularity-recipe] example.
-- For a [custom calendar][ref-custom-calendar-recipe] example.
-
-
-
-Here's how we can add time dimensions to the data model:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- # ...
-
- dimensions:
- - name: created_at
- sql: created_at
- type: time
- # You can use this time dimension with all default granularities:
- # year, quarter, month, week, day, hour, minute, second
-
- - name: completed_at
- sql: completed_at
- type: time
- # You can use this time dimension with all default granularities
- # and an additional custom granularity defined below
- granularities:
- - name: fiscal_year_starting_on_february_01
- interval: 1 year
- offset: 1 month
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- // ...
-
- dimensions: {
- created_at: {
- sql: `created_at`,
- type: `time`
- // You can use this time dimension with all default granularities:
- // year, quarter, month, week, day, hour, minute, second
- },
-
- completed_at: {
- sql: `completed_at`,
- type: `time`,
- // You can use this time dimension with all default granularities
- // and an additional custom granularity defined below
- granularities: {
- fiscal_year_starting_on_february_01: {
- interval: `1 year`,
- offset: `1 month`
- }
- }
- }
- }
-})
-```
-
-
-
-Time dimensions are essential to enabling performance boosts such as
-[partitioned pre-aggregations][ref-caching-use-preaggs-partition-time] and
-[incremental refreshes][ref-tutorial-incremental-preagg].
-
-## Measures
-
-_Measures_ represent the properties of a **set of data points** in the cube. To
-add a measure called `count` to our `orders` cube, for example, we can do the
-following:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- # ...
-
- measures:
- - name: count
- type: count
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- // ...
-
- measures: {
- count: {
- type: `count`
- }
- }
-})
-```
-
-
-
-In our `LineItems` cube, we can also create a measure to sum up the total value
-of line items sold:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: line_items
- # ...
-
- measures:
- - name: total
- sql: price
- type: sum
-```
-
-```javascript title="JavaScript"
-cube(`line_items`, {
- // ...
-
- measures: {
- total: {
- sql: `price`,
- type: `sum`
- }
- }
-})
-```
-
-
-
-[Calculated measures][ref-calculated-measures] and [subquery dimensions][ref-subquery-dimensions]
-can be used for measure composition. [Multi-stage calculations][ref-multi-stage-calculations]
-enable data modeling of more sophisticated measures.
-
-
-
-See the reference documentaton for the full list of measure [parameters][ref-measures].
-
-
-
-### Measure types
-
-Measures can be of different types, e.g., `count`, `sum`, or `number`. Often,
-aggregate functions in SQL are mapped to measure types in the following way:
-
-| Aggregate function in SQL | Measure type in Cube |
-| --- | --- |
-| `AVG` | [`avg`](/reference/data-modeling/measures#type) |
-| `BOOL_AND`, `BOOL_OR` | [`boolean`](/reference/data-modeling/measures#type) |
-| `COUNT` | [`count`](/reference/data-modeling/measures#type) |
-| `COUNT(DISTINCT …)` | [`count_distinct`](/reference/data-modeling/measures#type) |
-| `APPROX_COUNT_DISTINCT` | [`count_distinct_approx`](/reference/data-modeling/measures#type) |
-| `MAX` | [`max`](/reference/data-modeling/measures#type) |
-| `MIN` | [`min`](/reference/data-modeling/measures#type) |
-| `PERCENTILE_CONT`, `MEDIAN` | [`number`](/reference/data-modeling/measures#type) |
-| `STRING_AGG`, `LISTAGG` | [`string`](/reference/data-modeling/measures#type) |
-| `SUM` | [`sum`](/reference/data-modeling/measures#type) |
-| Any function returning a timestamp, e.g., `MAX(time)` | [`time`](/reference/data-modeling/measures#type) |
-
-
-
-See the [measure type reference][ref-ref-measure-types] for details.
-
-
-
-
-
-See the following recipes:
-- To learn how to define [average and percentile measures][ref-avg-and-percentile-recipe],
-- To learn how to calculate [period-over-period changes][ref-period-over-period-recipe].
-
-
-
-### Measure additivity
-
-Additivity is a property of measures that detemines whether measure values,
-once calculated for a set of dimensions, can be further aggregated to calculate
-measure values for a subset of these dimensions.
-
-Measure additivity has an impact on [pre-aggregation
-matching][ref-matching-preaggs].
-
-Additivity of a measure depends on its [type](#measure-types). Only measures
-with the following types are considered *additive*:
-[`count`](/reference/data-modeling/measures#type),
-[`count_distinct_approx`](/reference/data-modeling/measures#type),
-[`min`](/reference/data-modeling/measures#type),
-[`max`](/reference/data-modeling/measures#type),
-[`sum`](/reference/data-modeling/measures#type).
-Measures with all other types are considered *non-additive*.
-
-#### Example
-
-Consider the following cube:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: employees
- sql: |
- SELECT 1 AS id, 'Ali' AS first_name, 20 AS age, 'Los Gatos' AS city UNION ALL
- SELECT 2 AS id, 'Bob' AS first_name, 30 AS age, 'San Diego' AS city UNION ALL
- SELECT 3 AS id, 'Eve' AS first_name, 40 AS age, 'San Diego' AS city
-
- measures:
- - name: count
- type: count
-
- - name: avg_age
- sql: age
- type: avg
-
- dimensions:
- - name: city
- sql: city
- type: string
-```
-
-```javascript title="JavaScript"
-cube(`employees`, {
- sql: `
- SELECT 1 AS id, 'Ali' AS first_name, 20 AS age, 'Los Gatos' AS city UNION ALL
- SELECT 2 AS id, 'Bob' AS first_name, 30 AS age, 'San Diego' AS city UNION ALL
- SELECT 3 AS id, 'Eve' AS first_name, 40 AS age, 'San Diego' AS city
- `,
-
- measures: {
- count: {
- type: `count`
- },
-
- avg_age: {
- sql: `age`,
- type: `avg`
- }
- },
-
- dimensions: {
- city: {
- sql: `city`,
- type: `string`
- }
- }
-})
-```
-
-
-
-If we run a query that includes `city` as a dimension and `count` and `avg_age`
-as measures, we'll get the following results:
-
-| city | count | avg_age |
-| --------- | ----- | ------- |
-| Los Gatos | 1 | 20 |
-| San Diego | 2 | 35 |
-
-Then, if we remove the `city` dimension from the query, we'll get the following
-results:
-
-| count | avg_age |
-| ----- | ------- |
-| 3 | 30 |
-
-As you can see, the value of the `count` measure that we've got for the second
-query could have been calculated based on the results of the first one:
-`1 + 2 = 3`. It explains why the `count` measure, having the `count` type, is
-considered *additive*.
-
-However, the value of the `avg_age` measure that we've got for the second query
-can't be calculated based on the results of the first one: there's no way to
-derive `30` from `20` and `35`. This is why the `avg_age` measure, having the
-`avg` type, is considered *non-additive*.
-
-### Leaf measures
-
-Measures that do not [reference][ref-syntax-references] other measures are
-considered *leaf measures*.
-
-By definition, all measures that only reference SQL
-[columns][ref-syntax-references-column] and expressions are *leaf measures*.
-On the other hand, [calculated measures][ref-calculated-measures] might not
-necessarily be *leaf measures* because they can reference other measures.
-
-Whether a query contains only [additive](#measure-additivity) leaf measures has
-an impact on [pre-aggregation matching][ref-matching-preaggs].
-
-## Joins
-
-_Joins_ define the relationships between cubes, which then allows accessing and
-comparing properties from two or more cubes at the same time. In Cube, all joins
-are `LEFT JOIN`s.
-
-
-
-An `INNER JOIN` can be replicated with Cube; when making a Cube query, add a
-filter for `IS NOT NULL` on the required column.
-
-
-
-In the following example, we are left-joining the `line_items` cube onto our
-`orders` cube:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- # ...
-
- joins:
- - name: line_items
- # Here we use the `CUBE` global to refer to the current cube,
- # so the following is equivalent to `orders.id = line_items.order_id`
- sql: "{CUBE}.id = {line_items.order_id}"
- relationship: many_to_one
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- // ...
-
- joins: {
- line_items: {
- relationship: `many_to_one`,
- // Here we use the `CUBE` global to refer to the current cube,
- // so the following is equivalent to `orders.id = line_items.order_id`
- sql: `${CUBE}.id = ${line_items.order_id}`
- }
- }
-})
-```
-
-
-
-There are three types of join relationships (`one_to_one`, `one_to_many`, and
-`many_to_one`) and a few [other concepts][ref-working-with-joins] such as the
-direction of joins and transitive joins pitfalls.
-
-
-
-See the reference documentaton for the full list of join [parameters][ref-joins].
-
-
-
-## Segments
-
-_Segments_ are pre-defined filters that are kept within the data model instead of
-[a Cube query][ref-backend-query-filters]. They help to simplify queries and make
-it easy to reuse common filters across a variety of queries.
-
-To add a segment which limits results to completed orders, we can do the
-following:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- # ...
-
- segments:
- - name: only_completed
- sql: "{CUBE}.status = 'completed'"
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- // ...
-
- segments: {
- only_completed: {
- sql: `${CUBE}.status = 'completed'`
- }
- }
-})
-```
-
-
-
-
-
-See the reference documentaton for the full list of segment [parameters][ref-segments].
-
-
-
-## Pre-aggregations
-
-_Pre-aggregations_ provide a powerful way to accelerate frequently used queries
-and keep the cache up-to-date. Within a data model, they are defined using the
-`pre_aggregations` property:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- # ...
-
- pre_aggregations:
- - name: main
- measures:
- - count
- dimensions:
- - status
- time_dimension: created_at
- granularity: day
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- // ...
-
- pre_aggregations: {
- main: {
- measures: [CUBE.count],
- dimensions: [CUBE.status],
- timeDimension: CUBE.created_at,
- granularity: `day`
- }
- }
-})
-```
-
-
-
-A more thorough introduction can be found in [Getting Started with
-Pre-Aggregations][ref-caching-preaggs-intro].
-
-
-
-See the reference documentaton for the full list of pre-aggregation
-[parameters][ref-preaggs].
-
-
-
-
-[ref-backend-query-filters]: /reference/rest-api/query-format#filters-format
-[ref-caching-preaggs-intro]: /docs/pre-aggregations/getting-started-pre-aggregations
-[ref-caching-use-preaggs-partition-time]: /docs/pre-aggregations/using-pre-aggregations#partitioning
-[ref-ref-dimension-types]: /reference/data-modeling/dimensions#type
-[ref-ref-measure-types]: /reference/data-modeling/measures#type
-[ref-schema-ref-sql]: /reference/data-modeling/cube#sql
-[ref-schema-ref-sql-table]: /reference/data-modeling/cube#sql_table
-[ref-tutorial-incremental-preagg]: /reference/data-modeling/pre-aggregations#incremental
-[ref-cubes]: /reference/data-modeling/cube
-[ref-views]: /reference/data-modeling/view
-[ref-dimensions]: /reference/data-modeling/dimensions
-[ref-measures]: /reference/data-modeling/measures
-[ref-joins]: /reference/data-modeling/joins
-[ref-segments]: /reference/data-modeling/segments
-[ref-preaggs]: /reference/data-modeling/pre-aggregations
-[ref-extending-cubes]: /docs/data-modeling/concepts/code-reusability-extending-cubes
-[ref-polymorphic-cubes]: /docs/data-modeling/concepts/polymorphic-cubes
-[ref-data-blending]: /docs/data-modeling/concepts/data-blending
-[ref-dynamic-data-models]: /docs/data-modeling/dynamic
-[ref-proxy-dimensions]: /docs/data-modeling/concepts/calculated-members#proxy-dimensions
-[ref-subquery-dimensions]: /docs/data-modeling/concepts/calculated-members#subquery-dimensions
-[ref-calculated-measures]: /docs/data-modeling/concepts/calculated-members#calculated-measures
-[ref-working-with-joins]: /docs/data-modeling/concepts/working-with-joins
-
-[wiki-view-sql]: https://en.wikipedia.org/wiki/View_(SQL)
-[ref-matching-preaggs]: /docs/pre-aggregations/matching-pre-aggregations
-[ref-syntax-references]: /docs/data-modeling/syntax#references
-[ref-syntax-references-column]: /docs/data-modeling/syntax#column
-[ref-calculated-measures]: /docs/data-modeling/overview#4-using-calculated-measures
-[ref-multitenancy]: /admin/connect-to-data/multitenancy
-[ref-pmc]: /docs/deployment/cloud/deployment-types#production-multi-cluster
-[ref-ref-time-dimensions]: /reference/data-modeling/dimensions#type
-[ref-ref-dimension-granularities]: /reference/data-modeling/dimensions#granularities
-[ref-ref-primary-key]: /reference/data-modeling/dimensions#primary_key
-[ref-custom-granularity-recipe]: /recipes/data-modeling/custom-granularity
-[ref-proxy-granularity]: /docs/data-modeling/concepts/calculated-members#time-dimension-granularity
-[ref-mls]: /docs/data-modeling/access-control/member-level-security
-[ref-ref-hierarchies]: /reference/data-modeling/hierarchies
-[ref-ref-folders]: /reference/data-modeling/view#folders
-[ref-multi-stage-calculations]: /docs/data-modeling/concepts/multi-stage-calculations
-[ref-entities-vs-metrics-recipe]: /recipes/data-modeling/designing-metrics
-[ref-avg-and-percentile-recipe]: /recipes/data-modeling/percentiles
-[ref-period-over-period-recipe]: /recipes/data-modeling/period-over-period
-[ref-custom-calendar-recipe]: /recipes/data-modeling/custom-calendar
-[ref-cube-with-dbt]: /recipes/data-modeling/dbt
-[ref-apis-support]: /reference#data-modeling
-[ref-viz-tools]: /admin/connect-to-data/visualization-tools
-[ref-data-sources]: /admin/connect-to-data/data-sources
-[ref-calendar-cubes]: /docs/data-modeling/concepts/calendar-cubes
\ No newline at end of file
diff --git a/docs-mintlify/docs/data-modeling/concepts/multi-fact-queries.mdx b/docs-mintlify/docs/data-modeling/concepts/multi-fact-queries.mdx
deleted file mode 100644
index 2478ef352154a..0000000000000
--- a/docs-mintlify/docs/data-modeling/concepts/multi-fact-queries.mdx
+++ /dev/null
@@ -1,499 +0,0 @@
----
-title: Multi-fact queries
-description: When a view includes measures from multiple root fact tables, Cube builds separate aggregating subqueries and joins their results on common dimensions.
----
-
-When a [view](/reference/data-modeling/view) includes measures from multiple root
-fact tables, Cube can automatically execute a _multi-fact query_. Instead of
-joining all fact tables together and risking row multiplication, Cube builds a
-**separate aggregating subquery for each fact table** and then joins the results
-on the common dimensions.
-
-
-
-Multi-fact queries are powered by Tesseract, the [next-generation data modeling
-engine][link-tesseract]. Tesseract is currently in preview. Use the
-[`CUBEJS_TESSERACT_SQL_PLANNER`](/reference/configuration/environment-variables#cubejs_tesseract_sql_planner) environment variable to enable it.
-
-
-
-## When a multi-fact query is triggered
-
-A multi-fact query is triggered when a view has **multiple root fact tables**
-whose measures are queried together. Each distinct root fact table in the view
-becomes its own aggregating subquery, and the results are joined on the common
-dimensions shared across those facts.
-
-Consider a data model with two fact cubes, `orders` and `returns`. Both are
-joined to two shared dimension tables: `customers` and a `dates` date spine:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: customers
- sql_table: customers
-
- dimensions:
- - name: id
- type: number
- sql: id
- primary_key: true
- - name: name
- type: string
- sql: name
- - name: city
- type: string
- sql: city
-
- - name: dates
- sql_table: dates
-
- dimensions:
- - name: date
- type: time
- sql: date
- primary_key: true
-
- - name: orders
- sql_table: orders
-
- joins:
- - name: customers
- relationship: many_to_one
- sql: "{orders}.customer_id = {customers.id}"
- - name: dates
- relationship: many_to_one
- sql: "DATE_TRUNC('day', {orders}.created_at) = {dates.date}"
-
- dimensions:
- - name: id
- type: number
- sql: id
- primary_key: true
- - name: customer_id
- type: number
- sql: customer_id
- - name: status
- type: string
- sql: status
-
- measures:
- - name: count
- type: count
- - name: total_amount
- type: sum
- sql: amount
-
- - name: returns
- sql_table: returns
-
- joins:
- - name: customers
- relationship: many_to_one
- sql: "{returns}.customer_id = {customers.id}"
- - name: dates
- relationship: many_to_one
- sql: "DATE_TRUNC('day', {returns}.created_at) = {dates.date}"
-
- dimensions:
- - name: id
- type: number
- sql: id
- primary_key: true
- - name: customer_id
- type: number
- sql: customer_id
-
- measures:
- - name: count
- type: count
- - name: total_refund
- type: sum
- sql: refund_amount
-```
-
-```javascript title="JavaScript"
-cube(`customers`, {
- sql_table: `customers`,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- name: {
- sql: `name`,
- type: `string`
- },
-
- city: {
- sql: `city`,
- type: `string`
- }
- }
-})
-
-cube(`dates`, {
- sql_table: `dates`,
-
- dimensions: {
- date: {
- sql: `date`,
- type: `time`,
- primary_key: true
- }
- }
-})
-
-cube(`orders`, {
- sql_table: `orders`,
-
- joins: {
- customers: {
- relationship: `many_to_one`,
- sql: `${orders}.customer_id = ${customers.id}`
- },
-
- dates: {
- relationship: `many_to_one`,
- sql: `DATE_TRUNC('day', ${orders}.created_at) = ${dates.date}`
- }
- },
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- customer_id: {
- sql: `customer_id`,
- type: `number`
- },
-
- status: {
- sql: `status`,
- type: `string`
- }
- },
-
- measures: {
- count: {
- type: `count`
- },
-
- total_amount: {
- sql: `amount`,
- type: `sum`
- }
- }
-})
-
-cube(`returns`, {
- sql_table: `returns`,
-
- joins: {
- customers: {
- relationship: `many_to_one`,
- sql: `${returns}.customer_id = ${customers.id}`
- },
-
- dates: {
- relationship: `many_to_one`,
- sql: `DATE_TRUNC('day', ${returns}.created_at) = ${dates.date}`
- }
- },
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- customer_id: {
- sql: `customer_id`,
- type: `number`
- }
- },
-
- measures: {
- count: {
- type: `count`
- },
-
- total_refund: {
- sql: `refund_amount`,
- type: `sum`
- }
- }
-})
-```
-
-
-
-You can then define a view where `orders` and `returns` are separate root
-fact tables. The shared dimension tables — `customers` and `dates` — are
-each included with their own root-level join paths, not nested under a
-specific fact like `orders.customers`. This makes their dimensions common to
-both facts so they can be used to join the subquery results. The `prefix`
-parameter disambiguates identically named members from different fact cubes:
-
-
-
-```yaml title="YAML"
-views:
- - name: customer_overview
- cubes:
- - join_path: orders
- includes:
- - count
- - total_amount
- prefix: true
- - join_path: customers
- includes:
- - name
- - city
- - join_path: dates
- includes:
- - date
- - join_path: returns
- includes:
- - count
- - total_refund
- prefix: true
-```
-
-```javascript title="JavaScript"
-view(`customer_overview`, {
- cubes: [
- {
- join_path: orders,
- includes: [`count`, `total_amount`],
- prefix: true
- },
- {
- join_path: customers,
- includes: [`name`, `city`]
- },
- {
- join_path: dates,
- includes: [`date`]
- },
- {
- join_path: returns,
- includes: [`count`, `total_refund`],
- prefix: true
- }
- ]
-})
-```
-
-
-
-This view has two root fact tables (`orders` and `returns`) and two shared
-dimension tables (`customers` and `dates`). Because each dimension table is
-included at its own root-level join path rather than scoped under a single
-fact, their dimensions are available as common join keys for both fact
-subqueries.
-
-When you query measures from both facts — such as `orders_count`,
-`orders_total_amount`, `returns_count`, and `returns_total_refund` — grouped
-by common dimensions like `name`, `city`, and `date`, Cube detects the
-multiple roots and triggers a multi-fact query.
-
-## Join path requirements
-
-To ensure correct join paths within a multi-fact view, follow these rules:
-
-- **Within each root fact table**, any join paths to related cubes (e.g.,
- `orders.line_items`) should be listed explicitly in the view. This removes
- ambiguity about which tables are involved in each fact's subquery.
-- **Dimension tables that join to other, less granular dimension tables**
- (e.g., `customers` joining to `regions`) should also declare those join
- paths explicitly in the view if those dimensions are needed.
-- **Between root fact tables and root dimension tables**, one-hop joins must
- be defined at the cube level (as shown in the `orders` and `returns` cubes
- above, each declaring a direct join to `customers` and `dates`). This
- allows the multi-fact view to unambiguously resolve how each fact reaches
- each common dimension table.
-
-In the example above, both `orders` and `returns` declare direct joins to
-`customers` and `dates`. This means the view can build separate subqueries
-where each fact independently joins to the same dimension tables — without
-relying on transitive or implicit join paths.
-
-## How multi-fact queries work
-
-Cube analyzes the join hints for each measure and groups them by their
-**join key** — the set of tables involved in the join path from the root to
-the measure's cube. Measures that share the same join key are placed in the
-same group; measures with different join keys form separate groups. When there
-are **two or more groups**, the query is classified as multi-fact.
-
-The query is then executed in the following stages:
-
-### 1. Separate aggregating subqueries
-
-For each group of measures, Cube builds an independent aggregating subquery.
-Each subquery joins only the tables needed for that group's measures, applies
-all relevant filters and segments, and aggregates the results by the common
-dimensions.
-
-For example, given a query for `orders_count`, `orders_total_amount`,
-`returns_count`, and `returns_total_refund` grouped by `name`, `city`, and
-`date`:
-
-- **Subquery 1** (orders group): joins `orders` to `customers` and `dates`,
- computes `COUNT(*)` and `SUM(amount)`, grouped by `customers.name`,
- `customers.city`, and `dates.date`.
-- **Subquery 2** (returns group): joins `returns` to `customers` and `dates`,
- computes `COUNT(*)` and `SUM(refund_amount)`, grouped by `customers.name`,
- `customers.city`, and `dates.date`.
-
-### 2. Join on common dimensions
-
-The results of the subqueries are joined with `FULL JOIN` semantics on all
-common dimension columns — in this case, `name`, `city`, and `date`. This
-ensures that all rows from both fact tables are represented, even when a
-customer has orders but no returns, or vice versa. The actual SQL
-implementation may vary depending on database capabilities.
-
-### 3. Final result
-
-The final `SELECT` pulls measures from their respective subqueries and
-dimensions from the joined result. Rows with data in only one fact table
-will show `NULL` for measures from the other.
-
-For the `customer_overview` view, the result looks like:
-
-| name | city | date | orders_count | orders_total_amount | returns_count | returns_total_refund |
-| --- | --- | --- | --- | --- | --- | --- |
-| Alice | New York | 2025-01-15 | 2 | 200.00 | 0 | NULL |
-| Alice | New York | 2025-02-10 | 2 | 225.00 | 1 | 100.00 |
-| Bob | Seattle | 2025-01-20 | 3 | 550.00 | 2 | 130.00 |
-| Charlie | New York | 2025-02-05 | 0 | NULL | 2 | 100.00 |
-| Diana | Boston | 2025-03-01 | 1 | 400.00 | 0 | NULL |
-
-Notice that Charlie has no orders and Diana has no returns — both are still
-included in the results with `NULL` values for the missing fact table.
-
-## More than two fact tables
-
-Multi-fact queries are not limited to two root fact tables. If a view includes
-three or more fact tables, each one gets its own aggregating subquery, and all
-results are joined together on the common dimensions.
-
-For instance, adding a `reviews` cube as a third root fact in the view and
-querying `orders_count`, `returns_count`, and `reviews_count` grouped by
-`name`, `city`, and `date` produces three separate subqueries, all joined on
-those common dimensions.
-
-## All facts must share the same common dimensions
-
-Every root fact table in a multi-fact view must be joinable to the **same set
-of common dimension tables**. The subquery results are joined on these common
-dimensions, so if a fact table cannot reach one of the dimension tables, the
-join will fail.
-
-If a fact table does not naturally have a foreign key for one of the common
-dimension tables, you can create a **synthetic join** by selecting `NULL` for
-the missing foreign key in the cube's `sql` definition:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: refunds
- sql: >
- SELECT *, NULL AS customer_id FROM refunds
- joins:
- - name: customers
- relationship: many_to_one
- sql: "{refunds}.customer_id = {customers.id}"
- - name: dates
- relationship: many_to_one
- sql: "DATE_TRUNC('day', {refunds}.created_at) = {dates.date}"
-
- dimensions:
- - name: id
- type: number
- sql: id
- primary_key: true
-
- measures:
- - name: count
- type: count
- - name: total_amount
- type: sum
- sql: amount
-```
-
-```javascript title="JavaScript"
-cube(`refunds`, {
- sql: `SELECT *, NULL AS customer_id FROM refunds`,
-
- joins: {
- customers: {
- relationship: `many_to_one`,
- sql: `${refunds}.customer_id = ${customers.id}`
- },
-
- dates: {
- relationship: `many_to_one`,
- sql: `DATE_TRUNC('day', ${refunds}.created_at) = ${dates.date}`
- }
- },
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- }
- },
-
- measures: {
- count: {
- type: `count`
- },
-
- total_amount: {
- sql: `amount`,
- type: `sum`
- }
- }
-})
-```
-
-
-
-In this example, the `refunds` table has no `customer_id` column. By selecting
-`NULL AS customer_id` in the cube's SQL, the join to `customers` is
-syntactically valid. The `customer_id` will always be `NULL`, so refund rows
-will never match a specific customer, but the subquery can still participate
-in the multi-fact join on the full set of common dimensions.
-
-## Filters in multi-fact queries
-
-Filters on **common dimensions** (like `name`, `city`, or `date`) are applied to every
-subquery, ensuring consistent filtering across all fact tables.
-
-Filters on **fact-specific dimensions** (like `orders.status`) are applied only
-to the subquery for that specific fact table. Other fact table subqueries remain
-unaffected.
-
-**Measure filters** (e.g., `orders_count > 1`) are applied as `HAVING`
-conditions after the subqueries are joined, filtering the combined result set.
-
-## Segments in multi-fact queries
-
-[Segments](/reference/data-modeling/segments) that belong to a specific fact table are applied only
-to that fact table's subquery. For example, applying an `orders.completed_orders`
-segment filters only the orders subquery while leaving returns unaffected.
-
-[link-tesseract]: https://cube.dev/blog/introducing-tesseract
diff --git a/docs-mintlify/docs/data-modeling/concepts/multi-stage-calculations.mdx b/docs-mintlify/docs/data-modeling/concepts/multi-stage-calculations.mdx
deleted file mode 100644
index 7207d669b8691..0000000000000
--- a/docs-mintlify/docs/data-modeling/concepts/multi-stage-calculations.mdx
+++ /dev/null
@@ -1,714 +0,0 @@
----
-title: Multi-stage calculations
-description: "Measures are usually calculated as aggregations over dimensions or arbitrary SQL expressions."
----
-
-[Measures][ref-measures] are usually calculated as aggregations over [dimensions][ref-dimensions]
-or arbitrary SQL expressions.
-
-_Multi-stage calculations_ enable data modeling of more sophisticated _multi-stage measures_.
-They are calculated in two or more stages and often involve manipulations on already
-aggregated data. Each stage results in one or more [common table expressions][link-cte]
-(CTEs) in the generated SQL query.
-
-
-
-Multi-stage calculations are powered by Tesseract, the [next-generation data modeling
-engine][link-tesseract]. Tesseract is currently in preview. Use the
-[`CUBEJS_TESSERACT_SQL_PLANNER`](/reference/configuration/environment-variables#cubejs_tesseract_sql_planner) environment variable to enable it.
-
-
-
-
-
-Multi-stage calculations are not currently accelerated by pre-aggregations.
-Please track [this issue](https://github.com/cube-js/cube/issues/8487).
-
-
-
-Common uses of multi-stage calculations:
-
-- [Rolling window](#rolling-window), e.g., cumulative counts or moving averages.
-- [Time-shift](#time-shift), e.g., year-over-year sales growth.
-- [Period-to-date](#period-to-date), e.g., year-to-date (YTD) analysis.
-- [Conditional measure](#conditional-measure), e.g., amount in a selected currency.
-
-**Some calculations use inner and outer aggregation stages.** The _inner_ stage computes
-a base measure at a specific granularity, and the _outer_ stage aggregates those results
-according to the query's dimensions:
-
-- [Fixed dimension](#fixed-dimension), e.g., percent of total — use the [`group_by`][ref-group-by]
-parameter to group by only the listed dimensions.
-- [Nested aggregate](#nested-aggregate), e.g., average of per-customer averages — use the
-[`add_group_by`][ref-add-group-by] parameter to group by query dimensions plus listed.
-- [Ranking](#ranking), e.g., ranking products by revenue — use the [`reduce_by`][ref-reduce-by]
-parameter to group by query dimensions minus listed.
-
-## Rolling window
-
-Rolling window calculations are used to calculate metrics over a moving window of time.
-Use the [`rolling_window` parameter][ref-rolling-window] of a measure to define
-a rolling window.
-
-### Stages
-
-Here's how the rolling window calculation is performed:
-
-- **Date range.** First, the date range for the query is determined.
-If there's a time dimension with a date range filter in the query, it's used.
-Otherwise, the date range is determined by selecting the minimum and maximum
-values for the time dimension.
-
-
-
-Tesseract enables rolling window calculations without the date range for the time dimension.
-If Tesseract is not used, the date range must be provided. Otherwise, the query would
-fail with the following error: `Time series queries without dateRange aren't supported`.
-
-
-
-- **Time windows.** Then, the series of time windows is calculated. The size of the
-window is defined by the time dimension granularity and the `trailing` and
-`leading` parameters.
-- **Measure.** Finally, the measure is calculated for each window.
-
-### Example
-
-Data model:
-
-```yaml
-
-cubes:
- - name: orders
- sql: |
- SELECT 1 AS id, '2025-01-01'::TIMESTAMP AS time UNION ALL
- SELECT 2 AS id, '2025-01-11'::TIMESTAMP AS time UNION ALL
- SELECT 3 AS id, '2025-01-21'::TIMESTAMP AS time UNION ALL
- SELECT 4 AS id, '2025-01-31'::TIMESTAMP AS time UNION ALL
- SELECT 5 AS id, '2025-02-01'::TIMESTAMP AS time UNION ALL
- SELECT 6 AS id, '2025-02-11'::TIMESTAMP AS time UNION ALL
- SELECT 7 AS id, '2025-02-21'::TIMESTAMP AS time UNION ALL
- SELECT 8 AS id, '2025-03-01'::TIMESTAMP AS time UNION ALL
- SELECT 9 AS id, '2025-03-11'::TIMESTAMP AS time UNION ALL
- SELECT 10 AS id, '2025-03-21'::TIMESTAMP AS time UNION ALL
- SELECT 11 AS id, '2025-03-31'::TIMESTAMP AS time UNION ALL
- SELECT 12 AS id, '2025-04-01'::TIMESTAMP AS time
-
- dimensions:
- - name: time
- sql: time
- type: time
-
- measures:
- - name: rolling_count_month
- sql: id
- type: count
- rolling_window:
- trailing: unbounded
-```
-
-Query and result:
-
-
-
-
-
-We'll use a sample e-commerce database with two tables, `orders` and
-`line_items` to illustrate the concepts throughout this page:
-
-**`orders`**
-
-| **id** | **status** | **completed_at** | **created_at** |
-| ------ | ---------- | -------------------------- | -------------------------- |
-| 1 | completed | 2019-01-05 00:00:00.000000 | 2019-01-02 00:00:00.000000 |
-| 2 | shipped | 2019-01-17 00:00:00.000000 | 2019-01-02 00:00:00.000000 |
-| 3 | completed | 2019-01-27 00:00:00.000000 | 2019-01-02 00:00:00.000000 |
-| 4 | shipped | 2019-01-09 00:00:00.000000 | 2019-01-02 00:00:00.000000 |
-| 5 | processing | 2019-01-29 00:00:00.000000 | 2019-01-02 00:00:00.000000 |
-
-**`line_items`**
-
-| **id** | **product_id** | **order_id** | **quantity** | **price** | **created_at** |
-| ------ | -------------- | ------------ | ------------ | --------- | -------------------------- |
-| 1 | 31 | 1 | 1 | 275 | 2019-01-31 00:00:00.000000 |
-| 2 | 49 | 2 | 6 | 248 | 2021-01-20 00:00:00.000000 |
-| 3 | 89 | 3 | 6 | 197 | 2021-11-25 00:00:00.000000 |
-| 4 | 71 | 4 | 8 | 223 | 2019-12-23 00:00:00.000000 |
-| 5 | 64 | 5 | 5 | 75 | 2019-04-20 00:00:00.000000 |
-
-We'll be following the [entity-first](#entity-first-approach) approach to
-designing the data model.
-
-
-
-See [this recipe][ref-entities-vs-metrics-recipe] to learn about entity-first and
-metrics-first approaches.
-
-
-
-## Cubes
-
-_Cubes_ represent datasets in Cube and are conceptually similar to [views in
-SQL][wiki-view-sql]. Cubes are usually declared in separate files with one
-cube per file. Typically, a cube points to a single table in
-your [data source][ref-data-sources] using the [`sql_table` property][ref-schema-ref-sql-table]:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- sql_table: orders
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- sql_table: `orders`
-})
-```
-
-
-
-
-
-If you're using dbt, see [this recipe][ref-cube-with-dbt] to streamline defining cubes
-on top of dbt models.
-
-
-
-You can also use the [`sql` property][ref-schema-ref-sql] to accommodate more
-complex SQL queries:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- sql: |
- SELECT *
- FROM orders, line_items
- WHERE orders.id = line_items.order_id
-
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- sql: `
- SELECT *
- FROM orders, line_items
- WHERE orders.id = line_items.order_id
- `
-})
-```
-
-
-
-Each cube contains the definitions of its _members_: [dimensions](#dimensions),
-[measures](#measures), and [segments](#segments). You can control the access to
-cubes and their members by configuring the [member-level security][ref-mls].
-
-[Joins](#joins) are used to define relations between cubes.
-[Pre-aggregations](#pre-aggregations) are used to accelerate queries to cubes.
-Cubes and their members can be further referenced by [views](#views).
-
-Note that cubes support [extension][ref-extending-cubes],
-[polymorphism][ref-polymorphic-cubes], and [data blending][ref-data-blending].
-Custom calendars, such as retail calendars, can be implemented using [calendar
-cubes][ref-calendar-cubes].
-
-Cubes can be defined statically and you can also build [dynamic data
-models][ref-dynamic-data-models].
-
-
-
-Cube supports data models that consist of thousands of cubes and views.
-For large [multi-tenancy][ref-multitenancy] configurations, e.g., with more than
-100 tenants, consider using a [multi-cluster deployment][ref-pmc].
-
-
-
-
-
-See the reference documentaton for the full list of cube [parameters][ref-cubes].
-
-
-
-## Views
-
-_Views_ sit on top of the data graph of cubes and create a facade of your whole
-data model with which data consumers can interact. They are useful for defining
-metrics, managing governance and data access, and controlling ambiguous join
-paths.
-
-Views do **not** define their own members. Instead, they reference cubes by
-specific join paths and include their members.
-
-In the example below, we create the `orders` view which includes select members
-from `base_orders`, `products`, and `users` cubes:
-
-
-
-```yaml title="YAML"
-views:
- - name: orders
-
- cubes:
- - join_path: base_orders
- includes:
- - status
- - created_date
- - total_amount
- - total_amount_shipped
- - count
- - average_order_value
-
- - join_path: base_orders.line_items.products
- includes:
- - name: name
- alias: product
-
- - join_path: base_orders.users
- prefix: true
- includes: "*"
- excludes:
- - company
-```
-
-```javascript title="JavaScript"
-view(`orders`, {
- cubes: [
- {
- join_path: base_orders,
- includes: [
- `status`,
- `created_date`,
- `total_amount`,
- `total_amount_shipped`,
- `count`,
- `average_order_value`
- ]
- },
- {
- join_path: base_orders.line_items.products,
- includes: [
- {
- name: `name`,
- alias: `product`
- }
- ]
- },
- {
- join_path: base_orders.users,
- prefix: true,
- includes: `*`,
- excludes: [`company`]
- }
- ]
-})
-```
-
-
-
-Views do **not** define any [pre-aggregations](#pre-aggregations). Instead,
-they [reuse][ref-matching-preaggs] pre-aggregations from underlying cubes.
-
-View can be defined statically and you can also build [dynamic data
-models][ref-dynamic-data-models].
-
-
-
-See the reference documentaton for the full list of view [parameters][ref-views].
-
-
-
-### Folders
-
-Optionally, members of a view can be organized into [folders][ref-ref-folders].
-Each folder would contain a subset of members of the view.
-
-Cube supports both flat and nested folder structures, which can be used with various
-[visualization tools][ref-viz-tools]. If a specific tool does not support nested folders,
-they will be exposed to such a tool as an equivalent flat structure. Check [APIs &
-Integrations][ref-apis-support] for details on the nested folders support.
-
-## Dimensions
-
-_Dimensions_ represent the properties of a **single** data point in the cube.
-[The `orders` table](#top) contains only dimensions, so representing them in the
-`orders` cube is straightforward:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- # ...
-
- dimensions:
- - name: id
- sql: id
- type: number
- # Here we explicitly let Cube know this field is the primary key
- # This is required for de-duplicating results when using joins
- primary_key: true
-
- - name: status
- sql: status
- type: string
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- // ...
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- // Here we explicitly let Cube know this field is the primary key
- // This is required for de-duplicating results when using joins
- primary_key: true
- },
-
- status: {
- sql: `status`,
- type: `string`
- }
- }
-})
-```
-
-
-
-Note that the `id` dimension is defined as a [primary key][ref-ref-primary-key].
-It is also possible to have more than one primary key dimension in a cube if
-you'd like them all to be parts of a composite key.
-
-[The `line_items` table](#top) also has a couple of dimensions which can be
-represented as follows:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: line_items
- # ...
-
- dimensions:
- - name: id
- sql: id
- type: number
- # Again, we explicitly let Cube know this field is the primary key
- # This is required for de-duplicating results when using joins
- primary_key: true
-
- - name: order_id
- sql: order_id
- type: number
-```
-
-```javascript title="JavaScript"
-cube(`line_items`, {
- // ...
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- // Again, we explicitly let Cube know this field is the primary key
- // This is required for de-duplicating results when using joins
- primary_key: true
- },
-
- order_id: {
- sql: `order_id`,
- type: `number`
- }
- }
-})
-```
-
-
-
-If needed, dimensions can be organized into [hierarchies][ref-ref-hierarchies].
-Also, [proxy dimensions][ref-proxy-dimensions] are helpful for code reusability
-and [subquery dimensions][ref-subquery-dimensions] can be used to join cubes
-implicitly.
-
-
-
-See the reference documentaton for the full list of [dimension parameters][ref-dimensions].
-
-
-
-### Dimension types
-
-Dimensions can be of different types, e.g., `string`, `number`, or `time`. Often,
-data types in SQL are mapped to dimension types in the following way:
-
-| Data type in SQL | Dimension type in Cube |
-| --- | --- |
-| `timestamp`, `date`, `time` | [`time`](/reference/data-modeling/dimensions#type) |
-| `text`, `varchar` | [`string`](/reference/data-modeling/dimensions#type) |
-| `integer`, `bigint`, `decimal` | [`number`](/reference/data-modeling/dimensions#type) |
-| `boolean` | [`boolean`](/reference/data-modeling/dimensions#type) |
-
-
-
-See the [dimension type reference][ref-ref-dimension-types] for details.
-
-
-
-### Time dimensions
-
-Time-based properties are modeled using dimensions of the [`time`
-type][ref-ref-time-dimensions]. They allow grouping the result set by a unit of
-time (e.g., days, weeks, month, etc.), also known as the *time dimension
-granularity*.
-
-The following granularities are available by default for any time dimension:
-`year`, `quarter`, `month`, `week` (starting on Monday), `day`, `hour`, `minute`,
-`second`. You can also define [custom granularities][ref-ref-dimension-granularities]
-and optionally expose them via [proxy dimensions][ref-proxy-granularity] in case
-you need to use weeks starting on Sunday, fiscal years, etc.
-
-
-
-See the following recipes:
-- For a [custom granularity][ref-custom-granularity-recipe] example.
-- For a [custom calendar][ref-custom-calendar-recipe] example.
-
-
-
-Here's how we can add time dimensions to the data model:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- # ...
-
- dimensions:
- - name: created_at
- sql: created_at
- type: time
- # You can use this time dimension with all default granularities:
- # year, quarter, month, week, day, hour, minute, second
-
- - name: completed_at
- sql: completed_at
- type: time
- # You can use this time dimension with all default granularities
- # and an additional custom granularity defined below
- granularities:
- - name: fiscal_year_starting_on_february_01
- interval: 1 year
- offset: 1 month
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- // ...
-
- dimensions: {
- created_at: {
- sql: `created_at`,
- type: `time`
- // You can use this time dimension with all default granularities:
- // year, quarter, month, week, day, hour, minute, second
- },
-
- completed_at: {
- sql: `completed_at`,
- type: `time`,
- // You can use this time dimension with all default granularities
- // and an additional custom granularity defined below
- granularities: {
- fiscal_year_starting_on_february_01: {
- interval: `1 year`,
- offset: `1 month`
- }
- }
- }
- }
-})
-```
-
-
-
-Time dimensions are essential to enabling performance boosts such as
-[partitioned pre-aggregations][ref-caching-use-preaggs-partition-time] and
-[incremental refreshes][ref-tutorial-incremental-preagg].
-
-## Measures
-
-_Measures_ represent the properties of a **set of data points** in the cube. To
-add a measure called `count` to our `orders` cube, for example, we can do the
-following:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- # ...
-
- measures:
- - name: count
- type: count
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- // ...
-
- measures: {
- count: {
- type: `count`
- }
- }
-})
-```
-
-
-
-In our `LineItems` cube, we can also create a measure to sum up the total value
-of line items sold:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: line_items
- # ...
-
- measures:
- - name: total
- sql: price
- type: sum
-```
-
-```javascript title="JavaScript"
-cube(`line_items`, {
- // ...
-
- measures: {
- total: {
- sql: `price`,
- type: `sum`
- }
- }
-})
-```
-
-
-
-[Calculated measures][ref-calculated-measures] and [subquery dimensions][ref-subquery-dimensions]
-can be used for measure composition. [Multi-stage calculations][ref-multi-stage-calculations]
-enable data modeling of more sophisticated measures.
-
-
-
-See the reference documentaton for the full list of measure [parameters][ref-measures].
-
-
-
-### Measure types
-
-Measures can be of different types, e.g., `count`, `sum`, or `number`. Often,
-aggregate functions in SQL are mapped to measure types in the following way:
-
-| Aggregate function in SQL | Measure type in Cube |
-| --- | --- |
-| `AVG` | [`avg`](/reference/data-modeling/measures#type) |
-| `BOOL_AND`, `BOOL_OR` | [`boolean`](/reference/data-modeling/measures#type) |
-| `COUNT` | [`count`](/reference/data-modeling/measures#type) |
-| `COUNT(DISTINCT …)` | [`count_distinct`](/reference/data-modeling/measures#type) |
-| `APPROX_COUNT_DISTINCT` | [`count_distinct_approx`](/reference/data-modeling/measures#type) |
-| `MAX` | [`max`](/reference/data-modeling/measures#type) |
-| `MIN` | [`min`](/reference/data-modeling/measures#type) |
-| `PERCENTILE_CONT`, `MEDIAN` | [`number`](/reference/data-modeling/measures#type) |
-| `STRING_AGG`, `LISTAGG` | [`string`](/reference/data-modeling/measures#type) |
-| `SUM` | [`sum`](/reference/data-modeling/measures#type) |
-| Any function returning a timestamp, e.g., `MAX(time)` | [`time`](/reference/data-modeling/measures#type) |
-
-
-
-See the [measure type reference][ref-ref-measure-types] for details.
-
-
-
-
-
-See the following recipes:
-- To learn how to define [average and percentile measures][ref-avg-and-percentile-recipe],
-- To learn how to calculate [period-over-period changes][ref-period-over-period-recipe].
-
-
-
-### Measure additivity
-
-Additivity is a property of measures that detemines whether measure values,
-once calculated for a set of dimensions, can be further aggregated to calculate
-measure values for a subset of these dimensions.
-
-Measure additivity has an impact on [pre-aggregation
-matching][ref-matching-preaggs].
-
-Additivity of a measure depends on its [type](#measure-types). Only measures
-with the following types are considered *additive*:
-[`count`](/reference/data-modeling/measures#type),
-[`count_distinct_approx`](/reference/data-modeling/measures#type),
-[`min`](/reference/data-modeling/measures#type),
-[`max`](/reference/data-modeling/measures#type),
-[`sum`](/reference/data-modeling/measures#type).
-Measures with all other types are considered *non-additive*.
-
-#### Example
-
-Consider the following cube:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: employees
- sql: |
- SELECT 1 AS id, 'Ali' AS first_name, 20 AS age, 'Los Gatos' AS city UNION ALL
- SELECT 2 AS id, 'Bob' AS first_name, 30 AS age, 'San Diego' AS city UNION ALL
- SELECT 3 AS id, 'Eve' AS first_name, 40 AS age, 'San Diego' AS city
-
- measures:
- - name: count
- type: count
-
- - name: avg_age
- sql: age
- type: avg
-
- dimensions:
- - name: city
- sql: city
- type: string
-```
-
-```javascript title="JavaScript"
-cube(`employees`, {
- sql: `
- SELECT 1 AS id, 'Ali' AS first_name, 20 AS age, 'Los Gatos' AS city UNION ALL
- SELECT 2 AS id, 'Bob' AS first_name, 30 AS age, 'San Diego' AS city UNION ALL
- SELECT 3 AS id, 'Eve' AS first_name, 40 AS age, 'San Diego' AS city
- `,
-
- measures: {
- count: {
- type: `count`
- },
-
- avg_age: {
- sql: `age`,
- type: `avg`
- }
- },
-
- dimensions: {
- city: {
- sql: `city`,
- type: `string`
- }
- }
-})
-```
-
-
-
-If we run a query that includes `city` as a dimension and `count` and `avg_age`
-as measures, we'll get the following results:
-
-| city | count | avg_age |
-| --------- | ----- | ------- |
-| Los Gatos | 1 | 20 |
-| San Diego | 2 | 35 |
-
-Then, if we remove the `city` dimension from the query, we'll get the following
-results:
-
-| count | avg_age |
-| ----- | ------- |
-| 3 | 30 |
-
-As you can see, the value of the `count` measure that we've got for the second
-query could have been calculated based on the results of the first one:
-`1 + 2 = 3`. It explains why the `count` measure, having the `count` type, is
-considered *additive*.
-
-However, the value of the `avg_age` measure that we've got for the second query
-can't be calculated based on the results of the first one: there's no way to
-derive `30` from `20` and `35`. This is why the `avg_age` measure, having the
-`avg` type, is considered *non-additive*.
-
-### Leaf measures
-
-Measures that do not [reference][ref-syntax-references] other measures are
-considered *leaf measures*.
-
-By definition, all measures that only reference SQL
-[columns][ref-syntax-references-column] and expressions are *leaf measures*.
-On the other hand, [calculated measures][ref-calculated-measures] might not
-necessarily be *leaf measures* because they can reference other measures.
-
-Whether a query contains only [additive](#measure-additivity) leaf measures has
-an impact on [pre-aggregation matching][ref-matching-preaggs].
-
-## Joins
-
-_Joins_ define the relationships between cubes, which then allows accessing and
-comparing properties from two or more cubes at the same time. In Cube, all joins
-are `LEFT JOIN`s.
-
-
-
-An `INNER JOIN` can be replicated with Cube; when making a Cube query, add a
-filter for `IS NOT NULL` on the required column.
-
-
-
-In the following example, we are left-joining the `line_items` cube onto our
-`orders` cube:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- # ...
-
- joins:
- - name: line_items
- # Here we use the `CUBE` global to refer to the current cube,
- # so the following is equivalent to `orders.id = line_items.order_id`
- sql: "{CUBE}.id = {line_items.order_id}"
- relationship: many_to_one
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- // ...
-
- joins: {
- line_items: {
- relationship: `many_to_one`,
- // Here we use the `CUBE` global to refer to the current cube,
- // so the following is equivalent to `orders.id = line_items.order_id`
- sql: `${CUBE}.id = ${line_items.order_id}`
- }
- }
-})
-```
-
-
-
-There are three types of join relationships (`one_to_one`, `one_to_many`, and
-`many_to_one`) and a few [other concepts][ref-working-with-joins] such as the
-direction of joins and transitive joins pitfalls.
-
-
-
-See the reference documentaton for the full list of join [parameters][ref-joins].
-
-
-
-## Segments
-
-_Segments_ are pre-defined filters that are kept within the data model instead of
-[a Cube query][ref-backend-query-filters]. They help to simplify queries and make
-it easy to reuse common filters across a variety of queries.
-
-To add a segment which limits results to completed orders, we can do the
-following:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- # ...
-
- segments:
- - name: only_completed
- sql: "{CUBE}.status = 'completed'"
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- // ...
-
- segments: {
- only_completed: {
- sql: `${CUBE}.status = 'completed'`
- }
- }
-})
-```
-
-
-
-
-
-See the reference documentaton for the full list of segment [parameters][ref-segments].
-
-
-
-## Pre-aggregations
-
-_Pre-aggregations_ provide a powerful way to accelerate frequently used queries
-and keep the cache up-to-date. Within a data model, they are defined using the
-`pre_aggregations` property:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- # ...
-
- pre_aggregations:
- - name: main
- measures:
- - count
- dimensions:
- - status
- time_dimension: created_at
- granularity: day
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- // ...
-
- pre_aggregations: {
- main: {
- measures: [CUBE.count],
- dimensions: [CUBE.status],
- timeDimension: CUBE.created_at,
- granularity: `day`
- }
- }
-})
-```
-
-
-
-A more thorough introduction can be found in [Getting Started with
-Pre-Aggregations][ref-caching-preaggs-intro].
-
-
-
-See the reference documentaton for the full list of pre-aggregation
-[parameters][ref-preaggs].
-
-
-
-
-[ref-backend-query-filters]: /reference/rest-api/query-format#filters-format
-[ref-caching-preaggs-intro]: /docs/pre-aggregations/getting-started-pre-aggregations
-[ref-caching-use-preaggs-partition-time]: /docs/pre-aggregations/using-pre-aggregations#partitioning
-[ref-ref-dimension-types]: /reference/data-modeling/dimensions#type
-[ref-ref-measure-types]: /reference/data-modeling/measures#type
-[ref-schema-ref-sql]: /reference/data-modeling/cube#sql
-[ref-schema-ref-sql-table]: /reference/data-modeling/cube#sql_table
-[ref-tutorial-incremental-preagg]: /reference/data-modeling/pre-aggregations#incremental
-[ref-cubes]: /reference/data-modeling/cube
-[ref-views]: /reference/data-modeling/view
-[ref-dimensions]: /reference/data-modeling/dimensions
-[ref-measures]: /reference/data-modeling/measures
-[ref-joins]: /reference/data-modeling/joins
-[ref-segments]: /reference/data-modeling/segments
-[ref-preaggs]: /reference/data-modeling/pre-aggregations
-[ref-extending-cubes]: /docs/data-modeling/concepts/code-reusability-extending-cubes
-[ref-polymorphic-cubes]: /docs/data-modeling/concepts/polymorphic-cubes
-[ref-data-blending]: /docs/data-modeling/concepts/data-blending
-[ref-dynamic-data-models]: /docs/data-modeling/dynamic
-[ref-proxy-dimensions]: /docs/data-modeling/concepts/calculated-members#proxy-dimensions
-[ref-subquery-dimensions]: /docs/data-modeling/concepts/calculated-members#subquery-dimensions
-[ref-calculated-measures]: /docs/data-modeling/concepts/calculated-members#calculated-measures
-[ref-working-with-joins]: /docs/data-modeling/concepts/working-with-joins
-
-[wiki-view-sql]: https://en.wikipedia.org/wiki/View_(SQL)
-[ref-matching-preaggs]: /docs/pre-aggregations/matching-pre-aggregations
-[ref-syntax-references]: /docs/data-modeling/syntax#references
-[ref-syntax-references-column]: /docs/data-modeling/syntax#column
-[ref-calculated-measures]: /docs/data-modeling/overview#4-using-calculated-measures
-[ref-multitenancy]: /admin/connect-to-data/multitenancy
-[ref-pmc]: /docs/deployment/cloud/deployment-types#production-multi-cluster
-[ref-ref-time-dimensions]: /reference/data-modeling/dimensions#type
-[ref-ref-dimension-granularities]: /reference/data-modeling/dimensions#granularities
-[ref-ref-primary-key]: /reference/data-modeling/dimensions#primary_key
-[ref-custom-granularity-recipe]: /recipes/data-modeling/custom-granularity
-[ref-proxy-granularity]: /docs/data-modeling/concepts/calculated-members#time-dimension-granularity
-[ref-mls]: /docs/data-modeling/access-control/member-level-security
-[ref-ref-hierarchies]: /reference/data-modeling/hierarchies
-[ref-ref-folders]: /reference/data-modeling/view#folders
-[ref-multi-stage-calculations]: /docs/data-modeling/concepts/multi-stage-calculations
-[ref-entities-vs-metrics-recipe]: /recipes/data-modeling/designing-metrics
-[ref-avg-and-percentile-recipe]: /recipes/data-modeling/percentiles
-[ref-period-over-period-recipe]: /recipes/data-modeling/period-over-period
-[ref-custom-calendar-recipe]: /recipes/data-modeling/custom-calendar
-[ref-cube-with-dbt]: /recipes/data-modeling/dbt
-[ref-apis-support]: /reference#data-modeling
-[ref-viz-tools]: /admin/connect-to-data/visualization-tools
-[ref-data-sources]: /admin/connect-to-data/data-sources
-[ref-calendar-cubes]: /docs/data-modeling/concepts/calendar-cubes
\ No newline at end of file
diff --git a/docs-mintlify/docs/data-modeling/concepts/multi-fact-queries.mdx b/docs-mintlify/docs/data-modeling/concepts/multi-fact-queries.mdx
deleted file mode 100644
index 2478ef352154a..0000000000000
--- a/docs-mintlify/docs/data-modeling/concepts/multi-fact-queries.mdx
+++ /dev/null
@@ -1,499 +0,0 @@
----
-title: Multi-fact queries
-description: When a view includes measures from multiple root fact tables, Cube builds separate aggregating subqueries and joins their results on common dimensions.
----
-
-When a [view](/reference/data-modeling/view) includes measures from multiple root
-fact tables, Cube can automatically execute a _multi-fact query_. Instead of
-joining all fact tables together and risking row multiplication, Cube builds a
-**separate aggregating subquery for each fact table** and then joins the results
-on the common dimensions.
-
-
-
-Multi-fact queries are powered by Tesseract, the [next-generation data modeling
-engine][link-tesseract]. Tesseract is currently in preview. Use the
-[`CUBEJS_TESSERACT_SQL_PLANNER`](/reference/configuration/environment-variables#cubejs_tesseract_sql_planner) environment variable to enable it.
-
-
-
-## When a multi-fact query is triggered
-
-A multi-fact query is triggered when a view has **multiple root fact tables**
-whose measures are queried together. Each distinct root fact table in the view
-becomes its own aggregating subquery, and the results are joined on the common
-dimensions shared across those facts.
-
-Consider a data model with two fact cubes, `orders` and `returns`. Both are
-joined to two shared dimension tables: `customers` and a `dates` date spine:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: customers
- sql_table: customers
-
- dimensions:
- - name: id
- type: number
- sql: id
- primary_key: true
- - name: name
- type: string
- sql: name
- - name: city
- type: string
- sql: city
-
- - name: dates
- sql_table: dates
-
- dimensions:
- - name: date
- type: time
- sql: date
- primary_key: true
-
- - name: orders
- sql_table: orders
-
- joins:
- - name: customers
- relationship: many_to_one
- sql: "{orders}.customer_id = {customers.id}"
- - name: dates
- relationship: many_to_one
- sql: "DATE_TRUNC('day', {orders}.created_at) = {dates.date}"
-
- dimensions:
- - name: id
- type: number
- sql: id
- primary_key: true
- - name: customer_id
- type: number
- sql: customer_id
- - name: status
- type: string
- sql: status
-
- measures:
- - name: count
- type: count
- - name: total_amount
- type: sum
- sql: amount
-
- - name: returns
- sql_table: returns
-
- joins:
- - name: customers
- relationship: many_to_one
- sql: "{returns}.customer_id = {customers.id}"
- - name: dates
- relationship: many_to_one
- sql: "DATE_TRUNC('day', {returns}.created_at) = {dates.date}"
-
- dimensions:
- - name: id
- type: number
- sql: id
- primary_key: true
- - name: customer_id
- type: number
- sql: customer_id
-
- measures:
- - name: count
- type: count
- - name: total_refund
- type: sum
- sql: refund_amount
-```
-
-```javascript title="JavaScript"
-cube(`customers`, {
- sql_table: `customers`,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- name: {
- sql: `name`,
- type: `string`
- },
-
- city: {
- sql: `city`,
- type: `string`
- }
- }
-})
-
-cube(`dates`, {
- sql_table: `dates`,
-
- dimensions: {
- date: {
- sql: `date`,
- type: `time`,
- primary_key: true
- }
- }
-})
-
-cube(`orders`, {
- sql_table: `orders`,
-
- joins: {
- customers: {
- relationship: `many_to_one`,
- sql: `${orders}.customer_id = ${customers.id}`
- },
-
- dates: {
- relationship: `many_to_one`,
- sql: `DATE_TRUNC('day', ${orders}.created_at) = ${dates.date}`
- }
- },
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- customer_id: {
- sql: `customer_id`,
- type: `number`
- },
-
- status: {
- sql: `status`,
- type: `string`
- }
- },
-
- measures: {
- count: {
- type: `count`
- },
-
- total_amount: {
- sql: `amount`,
- type: `sum`
- }
- }
-})
-
-cube(`returns`, {
- sql_table: `returns`,
-
- joins: {
- customers: {
- relationship: `many_to_one`,
- sql: `${returns}.customer_id = ${customers.id}`
- },
-
- dates: {
- relationship: `many_to_one`,
- sql: `DATE_TRUNC('day', ${returns}.created_at) = ${dates.date}`
- }
- },
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- customer_id: {
- sql: `customer_id`,
- type: `number`
- }
- },
-
- measures: {
- count: {
- type: `count`
- },
-
- total_refund: {
- sql: `refund_amount`,
- type: `sum`
- }
- }
-})
-```
-
-
-
-You can then define a view where `orders` and `returns` are separate root
-fact tables. The shared dimension tables — `customers` and `dates` — are
-each included with their own root-level join paths, not nested under a
-specific fact like `orders.customers`. This makes their dimensions common to
-both facts so they can be used to join the subquery results. The `prefix`
-parameter disambiguates identically named members from different fact cubes:
-
-
-
-```yaml title="YAML"
-views:
- - name: customer_overview
- cubes:
- - join_path: orders
- includes:
- - count
- - total_amount
- prefix: true
- - join_path: customers
- includes:
- - name
- - city
- - join_path: dates
- includes:
- - date
- - join_path: returns
- includes:
- - count
- - total_refund
- prefix: true
-```
-
-```javascript title="JavaScript"
-view(`customer_overview`, {
- cubes: [
- {
- join_path: orders,
- includes: [`count`, `total_amount`],
- prefix: true
- },
- {
- join_path: customers,
- includes: [`name`, `city`]
- },
- {
- join_path: dates,
- includes: [`date`]
- },
- {
- join_path: returns,
- includes: [`count`, `total_refund`],
- prefix: true
- }
- ]
-})
-```
-
-
-
-This view has two root fact tables (`orders` and `returns`) and two shared
-dimension tables (`customers` and `dates`). Because each dimension table is
-included at its own root-level join path rather than scoped under a single
-fact, their dimensions are available as common join keys for both fact
-subqueries.
-
-When you query measures from both facts — such as `orders_count`,
-`orders_total_amount`, `returns_count`, and `returns_total_refund` — grouped
-by common dimensions like `name`, `city`, and `date`, Cube detects the
-multiple roots and triggers a multi-fact query.
-
-## Join path requirements
-
-To ensure correct join paths within a multi-fact view, follow these rules:
-
-- **Within each root fact table**, any join paths to related cubes (e.g.,
- `orders.line_items`) should be listed explicitly in the view. This removes
- ambiguity about which tables are involved in each fact's subquery.
-- **Dimension tables that join to other, less granular dimension tables**
- (e.g., `customers` joining to `regions`) should also declare those join
- paths explicitly in the view if those dimensions are needed.
-- **Between root fact tables and root dimension tables**, one-hop joins must
- be defined at the cube level (as shown in the `orders` and `returns` cubes
- above, each declaring a direct join to `customers` and `dates`). This
- allows the multi-fact view to unambiguously resolve how each fact reaches
- each common dimension table.
-
-In the example above, both `orders` and `returns` declare direct joins to
-`customers` and `dates`. This means the view can build separate subqueries
-where each fact independently joins to the same dimension tables — without
-relying on transitive or implicit join paths.
-
-## How multi-fact queries work
-
-Cube analyzes the join hints for each measure and groups them by their
-**join key** — the set of tables involved in the join path from the root to
-the measure's cube. Measures that share the same join key are placed in the
-same group; measures with different join keys form separate groups. When there
-are **two or more groups**, the query is classified as multi-fact.
-
-The query is then executed in the following stages:
-
-### 1. Separate aggregating subqueries
-
-For each group of measures, Cube builds an independent aggregating subquery.
-Each subquery joins only the tables needed for that group's measures, applies
-all relevant filters and segments, and aggregates the results by the common
-dimensions.
-
-For example, given a query for `orders_count`, `orders_total_amount`,
-`returns_count`, and `returns_total_refund` grouped by `name`, `city`, and
-`date`:
-
-- **Subquery 1** (orders group): joins `orders` to `customers` and `dates`,
- computes `COUNT(*)` and `SUM(amount)`, grouped by `customers.name`,
- `customers.city`, and `dates.date`.
-- **Subquery 2** (returns group): joins `returns` to `customers` and `dates`,
- computes `COUNT(*)` and `SUM(refund_amount)`, grouped by `customers.name`,
- `customers.city`, and `dates.date`.
-
-### 2. Join on common dimensions
-
-The results of the subqueries are joined with `FULL JOIN` semantics on all
-common dimension columns — in this case, `name`, `city`, and `date`. This
-ensures that all rows from both fact tables are represented, even when a
-customer has orders but no returns, or vice versa. The actual SQL
-implementation may vary depending on database capabilities.
-
-### 3. Final result
-
-The final `SELECT` pulls measures from their respective subqueries and
-dimensions from the joined result. Rows with data in only one fact table
-will show `NULL` for measures from the other.
-
-For the `customer_overview` view, the result looks like:
-
-| name | city | date | orders_count | orders_total_amount | returns_count | returns_total_refund |
-| --- | --- | --- | --- | --- | --- | --- |
-| Alice | New York | 2025-01-15 | 2 | 200.00 | 0 | NULL |
-| Alice | New York | 2025-02-10 | 2 | 225.00 | 1 | 100.00 |
-| Bob | Seattle | 2025-01-20 | 3 | 550.00 | 2 | 130.00 |
-| Charlie | New York | 2025-02-05 | 0 | NULL | 2 | 100.00 |
-| Diana | Boston | 2025-03-01 | 1 | 400.00 | 0 | NULL |
-
-Notice that Charlie has no orders and Diana has no returns — both are still
-included in the results with `NULL` values for the missing fact table.
-
-## More than two fact tables
-
-Multi-fact queries are not limited to two root fact tables. If a view includes
-three or more fact tables, each one gets its own aggregating subquery, and all
-results are joined together on the common dimensions.
-
-For instance, adding a `reviews` cube as a third root fact in the view and
-querying `orders_count`, `returns_count`, and `reviews_count` grouped by
-`name`, `city`, and `date` produces three separate subqueries, all joined on
-those common dimensions.
-
-## All facts must share the same common dimensions
-
-Every root fact table in a multi-fact view must be joinable to the **same set
-of common dimension tables**. The subquery results are joined on these common
-dimensions, so if a fact table cannot reach one of the dimension tables, the
-join will fail.
-
-If a fact table does not naturally have a foreign key for one of the common
-dimension tables, you can create a **synthetic join** by selecting `NULL` for
-the missing foreign key in the cube's `sql` definition:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: refunds
- sql: >
- SELECT *, NULL AS customer_id FROM refunds
- joins:
- - name: customers
- relationship: many_to_one
- sql: "{refunds}.customer_id = {customers.id}"
- - name: dates
- relationship: many_to_one
- sql: "DATE_TRUNC('day', {refunds}.created_at) = {dates.date}"
-
- dimensions:
- - name: id
- type: number
- sql: id
- primary_key: true
-
- measures:
- - name: count
- type: count
- - name: total_amount
- type: sum
- sql: amount
-```
-
-```javascript title="JavaScript"
-cube(`refunds`, {
- sql: `SELECT *, NULL AS customer_id FROM refunds`,
-
- joins: {
- customers: {
- relationship: `many_to_one`,
- sql: `${refunds}.customer_id = ${customers.id}`
- },
-
- dates: {
- relationship: `many_to_one`,
- sql: `DATE_TRUNC('day', ${refunds}.created_at) = ${dates.date}`
- }
- },
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- }
- },
-
- measures: {
- count: {
- type: `count`
- },
-
- total_amount: {
- sql: `amount`,
- type: `sum`
- }
- }
-})
-```
-
-
-
-In this example, the `refunds` table has no `customer_id` column. By selecting
-`NULL AS customer_id` in the cube's SQL, the join to `customers` is
-syntactically valid. The `customer_id` will always be `NULL`, so refund rows
-will never match a specific customer, but the subquery can still participate
-in the multi-fact join on the full set of common dimensions.
-
-## Filters in multi-fact queries
-
-Filters on **common dimensions** (like `name`, `city`, or `date`) are applied to every
-subquery, ensuring consistent filtering across all fact tables.
-
-Filters on **fact-specific dimensions** (like `orders.status`) are applied only
-to the subquery for that specific fact table. Other fact table subqueries remain
-unaffected.
-
-**Measure filters** (e.g., `orders_count > 1`) are applied as `HAVING`
-conditions after the subqueries are joined, filtering the combined result set.
-
-## Segments in multi-fact queries
-
-[Segments](/reference/data-modeling/segments) that belong to a specific fact table are applied only
-to that fact table's subquery. For example, applying an `orders.completed_orders`
-segment filters only the orders subquery while leaving returns unaffected.
-
-[link-tesseract]: https://cube.dev/blog/introducing-tesseract
diff --git a/docs-mintlify/docs/data-modeling/concepts/multi-stage-calculations.mdx b/docs-mintlify/docs/data-modeling/concepts/multi-stage-calculations.mdx
deleted file mode 100644
index 7207d669b8691..0000000000000
--- a/docs-mintlify/docs/data-modeling/concepts/multi-stage-calculations.mdx
+++ /dev/null
@@ -1,714 +0,0 @@
----
-title: Multi-stage calculations
-description: "Measures are usually calculated as aggregations over dimensions or arbitrary SQL expressions."
----
-
-[Measures][ref-measures] are usually calculated as aggregations over [dimensions][ref-dimensions]
-or arbitrary SQL expressions.
-
-_Multi-stage calculations_ enable data modeling of more sophisticated _multi-stage measures_.
-They are calculated in two or more stages and often involve manipulations on already
-aggregated data. Each stage results in one or more [common table expressions][link-cte]
-(CTEs) in the generated SQL query.
-
-
-
-Multi-stage calculations are powered by Tesseract, the [next-generation data modeling
-engine][link-tesseract]. Tesseract is currently in preview. Use the
-[`CUBEJS_TESSERACT_SQL_PLANNER`](/reference/configuration/environment-variables#cubejs_tesseract_sql_planner) environment variable to enable it.
-
-
-
-
-
-Multi-stage calculations are not currently accelerated by pre-aggregations.
-Please track [this issue](https://github.com/cube-js/cube/issues/8487).
-
-
-
-Common uses of multi-stage calculations:
-
-- [Rolling window](#rolling-window), e.g., cumulative counts or moving averages.
-- [Time-shift](#time-shift), e.g., year-over-year sales growth.
-- [Period-to-date](#period-to-date), e.g., year-to-date (YTD) analysis.
-- [Conditional measure](#conditional-measure), e.g., amount in a selected currency.
-
-**Some calculations use inner and outer aggregation stages.** The _inner_ stage computes
-a base measure at a specific granularity, and the _outer_ stage aggregates those results
-according to the query's dimensions:
-
-- [Fixed dimension](#fixed-dimension), e.g., percent of total — use the [`group_by`][ref-group-by]
-parameter to group by only the listed dimensions.
-- [Nested aggregate](#nested-aggregate), e.g., average of per-customer averages — use the
-[`add_group_by`][ref-add-group-by] parameter to group by query dimensions plus listed.
-- [Ranking](#ranking), e.g., ranking products by revenue — use the [`reduce_by`][ref-reduce-by]
-parameter to group by query dimensions minus listed.
-
-## Rolling window
-
-Rolling window calculations are used to calculate metrics over a moving window of time.
-Use the [`rolling_window` parameter][ref-rolling-window] of a measure to define
-a rolling window.
-
-### Stages
-
-Here's how the rolling window calculation is performed:
-
-- **Date range.** First, the date range for the query is determined.
-If there's a time dimension with a date range filter in the query, it's used.
-Otherwise, the date range is determined by selecting the minimum and maximum
-values for the time dimension.
-
-
-
-Tesseract enables rolling window calculations without the date range for the time dimension.
-If Tesseract is not used, the date range must be provided. Otherwise, the query would
-fail with the following error: `Time series queries without dateRange aren't supported`.
-
-
-
-- **Time windows.** Then, the series of time windows is calculated. The size of the
-window is defined by the time dimension granularity and the `trailing` and
-`leading` parameters.
-- **Measure.** Finally, the measure is calculated for each window.
-
-### Example
-
-Data model:
-
-```yaml
-
-cubes:
- - name: orders
- sql: |
- SELECT 1 AS id, '2025-01-01'::TIMESTAMP AS time UNION ALL
- SELECT 2 AS id, '2025-01-11'::TIMESTAMP AS time UNION ALL
- SELECT 3 AS id, '2025-01-21'::TIMESTAMP AS time UNION ALL
- SELECT 4 AS id, '2025-01-31'::TIMESTAMP AS time UNION ALL
- SELECT 5 AS id, '2025-02-01'::TIMESTAMP AS time UNION ALL
- SELECT 6 AS id, '2025-02-11'::TIMESTAMP AS time UNION ALL
- SELECT 7 AS id, '2025-02-21'::TIMESTAMP AS time UNION ALL
- SELECT 8 AS id, '2025-03-01'::TIMESTAMP AS time UNION ALL
- SELECT 9 AS id, '2025-03-11'::TIMESTAMP AS time UNION ALL
- SELECT 10 AS id, '2025-03-21'::TIMESTAMP AS time UNION ALL
- SELECT 11 AS id, '2025-03-31'::TIMESTAMP AS time UNION ALL
- SELECT 12 AS id, '2025-04-01'::TIMESTAMP AS time
-
- dimensions:
- - name: time
- sql: time
- type: time
-
- measures:
- - name: rolling_count_month
- sql: id
- type: count
- rolling_window:
- trailing: unbounded
-```
-
-Query and result:
-
-
-  -
-
-## Time shift
-
-A _time-shift measure_ calculates the value of another measure at a different point in
-time. This is achieved by _shifting_ the time dimension from the query in the necessary
-direction during the calculation. Time-shifts are configured using the [`time_shift`
-parameter][ref-ref-time-shift] of a measure.
-
-Typically, this is used to compare the current value of a measure with its prior value,
-such as the same time last year. For example, if you have the `revenue` measure, you can
-calculate its value for the same time last year:
-
-```yaml
-- name: revenue_prior_year
- multi_stage: true
- sql: "{revenue}"
- type: number
- time_shift:
- - interval: 1 year
- type: prior
-```
-
-You can use time-shift measures with [calendar cubes][ref-calendar-cubes] to customize
-how time-shifting works, e.g., to shift the time dimension to the prior date in a retail
-calendar.
-
-### Example
-
-Data model:
-
-```yaml
-cubes:
- - name: prior_date
- sql: |
- SELECT '2023-04-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-05-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-06-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-07-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-08-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-09-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-10-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-11-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-12-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-01-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-02-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-03-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-04-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-05-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-06-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-07-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-08-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-09-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-10-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-11-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-12-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-01-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-02-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-03-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-04-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-05-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-06-01'::TIMESTAMP AS time, 1000 AS revenue
-
- dimensions:
- - name: time
- sql: time
- type: time
-
- measures:
- - name: revenue
- sql: revenue
- type: sum
-
- - name: revenue_ytd
- sql: revenue
- type: sum
- rolling_window:
- type: to_date
- granularity: year
-
- - name: revenue_prior_year
- multi_stage: true
- sql: "{revenue}"
- type: number
- time_shift:
- - time_dimension: time
- interval: 1 year
- type: prior
-
- - name: revenue_prior_year_ytd
- multi_stage: true
- sql: "{revenue_ytd}"
- type: number
- time_shift:
- - time_dimension: time
- interval: 1 year
- type: prior
-```
-
-Queries and results:
-
-
-
-
-
-## Time shift
-
-A _time-shift measure_ calculates the value of another measure at a different point in
-time. This is achieved by _shifting_ the time dimension from the query in the necessary
-direction during the calculation. Time-shifts are configured using the [`time_shift`
-parameter][ref-ref-time-shift] of a measure.
-
-Typically, this is used to compare the current value of a measure with its prior value,
-such as the same time last year. For example, if you have the `revenue` measure, you can
-calculate its value for the same time last year:
-
-```yaml
-- name: revenue_prior_year
- multi_stage: true
- sql: "{revenue}"
- type: number
- time_shift:
- - interval: 1 year
- type: prior
-```
-
-You can use time-shift measures with [calendar cubes][ref-calendar-cubes] to customize
-how time-shifting works, e.g., to shift the time dimension to the prior date in a retail
-calendar.
-
-### Example
-
-Data model:
-
-```yaml
-cubes:
- - name: prior_date
- sql: |
- SELECT '2023-04-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-05-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-06-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-07-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-08-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-09-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-10-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-11-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-12-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-01-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-02-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-03-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-04-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-05-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-06-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-07-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-08-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-09-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-10-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-11-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-12-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-01-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-02-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-03-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-04-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-05-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-06-01'::TIMESTAMP AS time, 1000 AS revenue
-
- dimensions:
- - name: time
- sql: time
- type: time
-
- measures:
- - name: revenue
- sql: revenue
- type: sum
-
- - name: revenue_ytd
- sql: revenue
- type: sum
- rolling_window:
- type: to_date
- granularity: year
-
- - name: revenue_prior_year
- multi_stage: true
- sql: "{revenue}"
- type: number
- time_shift:
- - time_dimension: time
- interval: 1 year
- type: prior
-
- - name: revenue_prior_year_ytd
- multi_stage: true
- sql: "{revenue_ytd}"
- type: number
- time_shift:
- - time_dimension: time
- interval: 1 year
- type: prior
-```
-
-Queries and results:
-
-
-  -
-
-
-
-
-
-
-  -
-
-## Period-to-date
-
-Period-to-date calculations can be used to analyze data over different time periods:
-
-- Year-to-date (YTD) analysis.
-- Quarter-to-date (QTD) analysis.
-- Month-to-date (MTD) analysis.
-
-```yaml
-- name: revenue_ytd
- sql: revenue
- type: sum
- rolling_window:
- type: to_date
- granularity: year
-
-- name: revenue_qtd
- sql: revenue
- type: sum
- rolling_window:
- type: to_date
- granularity: quarter
-
-- name: revenue_mtd
- sql: revenue
- type: sum
- rolling_window:
- type: to_date
- granularity: month
-```
-
-### Example
-
-Data model:
-
-```yaml
-cubes:
- - name: prior_date
- sql: |
- SELECT '2023-04-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-05-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-06-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-07-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-08-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-09-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-10-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-11-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-12-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-01-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-02-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-03-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-04-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-05-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-06-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-07-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-08-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-09-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-10-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-11-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-12-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-01-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-02-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-03-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-04-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-05-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-06-01'::TIMESTAMP AS time, 1000 AS revenue
-
- dimensions:
- - name: time
- sql: time
- type: time
-
- measures:
- - name: revenue_ytd
- sql: revenue
- type: sum
- rolling_window:
- type: to_date
- granularity: year
-
- - name: revenue_qtd
- sql: revenue
- type: sum
- rolling_window:
- type: to_date
- granularity: quarter
-
- - name: revenue_mtd
- sql: revenue
- type: sum
- rolling_window:
- type: to_date
- granularity: month
-```
-
-Query and result:
-
-
-
-
-
-## Period-to-date
-
-Period-to-date calculations can be used to analyze data over different time periods:
-
-- Year-to-date (YTD) analysis.
-- Quarter-to-date (QTD) analysis.
-- Month-to-date (MTD) analysis.
-
-```yaml
-- name: revenue_ytd
- sql: revenue
- type: sum
- rolling_window:
- type: to_date
- granularity: year
-
-- name: revenue_qtd
- sql: revenue
- type: sum
- rolling_window:
- type: to_date
- granularity: quarter
-
-- name: revenue_mtd
- sql: revenue
- type: sum
- rolling_window:
- type: to_date
- granularity: month
-```
-
-### Example
-
-Data model:
-
-```yaml
-cubes:
- - name: prior_date
- sql: |
- SELECT '2023-04-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-05-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-06-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-07-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-08-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-09-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-10-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-11-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2023-12-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-01-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-02-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-03-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-04-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-05-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-06-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-07-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-08-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-09-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-10-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-11-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2024-12-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-01-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-02-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-03-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-04-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-05-01'::TIMESTAMP AS time, 1000 AS revenue UNION ALL
- SELECT '2025-06-01'::TIMESTAMP AS time, 1000 AS revenue
-
- dimensions:
- - name: time
- sql: time
- type: time
-
- measures:
- - name: revenue_ytd
- sql: revenue
- type: sum
- rolling_window:
- type: to_date
- granularity: year
-
- - name: revenue_qtd
- sql: revenue
- type: sum
- rolling_window:
- type: to_date
- granularity: quarter
-
- - name: revenue_mtd
- sql: revenue
- type: sum
- rolling_window:
- type: to_date
- granularity: month
-```
-
-Query and result:
-
-
-  -
-
-## Conditional measure
-
-Conditional measure calculations can be used to create measures that depend on the value
-of a dimension. Such measures are defined using the [`case` parameter][ref-case-measures]
-and used together with [`switch` dimensions][ref-switch-dimensions].
-
-```yaml
-- name: amount_in_currency
- multi_stage: true
- case:
- switch: "{CUBE.currency}"
- when:
- - value: EUR
- sql: "{CUBE.amount_eur}"
- - value: GBP
- sql: "{CUBE.amount_gbp}"
- else:
- sql: "{CUBE.amount_usd}"
- type: number
-```
-
-### Example
-
-Data model:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- sql: |
- SELECT 1 AS id, 100 AS amount_usd UNION ALL
- SELECT 2 AS id, 200 AS amount_usd UNION ALL
- SELECT 3 AS id, 300 AS amount_usd UNION ALL
- SELECT 4 AS id, 400 AS amount_usd UNION ALL
- SELECT 5 AS id, 500 AS amount_usd
-
- dimensions:
- - name: currency
- type: switch
- values:
- - USD
- - EUR
- - GBP
-
- measures:
- - name: amount_usd
- sql: amount_usd
- type: sum
-
- - name: amount_eur
- sql: "{amount_usd} * 0.9"
- type: number
-
- - name: amount_gbp
- sql: "{amount_usd} * 0.8"
- type: number
-
- - name: amount_in_currency
- multi_stage: true
- case:
- switch: "{currency}"
- when:
- - value: EUR
- sql: "{amount_eur}"
- - value: GBP
- sql: "{amount_gbp}"
- else:
- sql: "{amount_usd}"
- type: number
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- sql: `
- SELECT 1 AS id, 100 AS amount_usd UNION ALL
- SELECT 2 AS id, 200 AS amount_usd UNION ALL
- SELECT 3 AS id, 300 AS amount_usd UNION ALL
- SELECT 4 AS id, 400 AS amount_usd UNION ALL
- SELECT 5 AS id, 500 AS amount_usd
- `,
-
- dimensions: {
- currency: {
- type: `switch`,
- values: [`USD`, `EUR`, `GBP`]
- }
- },
-
- measures: {
- amount_usd: {
- sql: `amount_usd`,
- type: `sum`
- },
-
- amount_eur: {
- sql: `${amount_usd} * 0.9`,
- type: `number`
- },
-
- amount_gbp: {
- sql: `${amount_usd} * 0.8`,
- type: `number`
- },
-
- amount_in_currency: {
- multi_stage: true,
- case: {
- switch: `${currency}`,
- when: [
- { value: `EUR`, sql: `${amount_eur}` },
- { value: `GBP`, sql: `${amount_gbp}` }
- ],
- else: { sql: `${amount_usd}` }
- },
- type: `number`
- }
- }
-})
-```
-
-
-
-Query and result:
-
-
-
-
-
-## Conditional measure
-
-Conditional measure calculations can be used to create measures that depend on the value
-of a dimension. Such measures are defined using the [`case` parameter][ref-case-measures]
-and used together with [`switch` dimensions][ref-switch-dimensions].
-
-```yaml
-- name: amount_in_currency
- multi_stage: true
- case:
- switch: "{CUBE.currency}"
- when:
- - value: EUR
- sql: "{CUBE.amount_eur}"
- - value: GBP
- sql: "{CUBE.amount_gbp}"
- else:
- sql: "{CUBE.amount_usd}"
- type: number
-```
-
-### Example
-
-Data model:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- sql: |
- SELECT 1 AS id, 100 AS amount_usd UNION ALL
- SELECT 2 AS id, 200 AS amount_usd UNION ALL
- SELECT 3 AS id, 300 AS amount_usd UNION ALL
- SELECT 4 AS id, 400 AS amount_usd UNION ALL
- SELECT 5 AS id, 500 AS amount_usd
-
- dimensions:
- - name: currency
- type: switch
- values:
- - USD
- - EUR
- - GBP
-
- measures:
- - name: amount_usd
- sql: amount_usd
- type: sum
-
- - name: amount_eur
- sql: "{amount_usd} * 0.9"
- type: number
-
- - name: amount_gbp
- sql: "{amount_usd} * 0.8"
- type: number
-
- - name: amount_in_currency
- multi_stage: true
- case:
- switch: "{currency}"
- when:
- - value: EUR
- sql: "{amount_eur}"
- - value: GBP
- sql: "{amount_gbp}"
- else:
- sql: "{amount_usd}"
- type: number
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- sql: `
- SELECT 1 AS id, 100 AS amount_usd UNION ALL
- SELECT 2 AS id, 200 AS amount_usd UNION ALL
- SELECT 3 AS id, 300 AS amount_usd UNION ALL
- SELECT 4 AS id, 400 AS amount_usd UNION ALL
- SELECT 5 AS id, 500 AS amount_usd
- `,
-
- dimensions: {
- currency: {
- type: `switch`,
- values: [`USD`, `EUR`, `GBP`]
- }
- },
-
- measures: {
- amount_usd: {
- sql: `amount_usd`,
- type: `sum`
- },
-
- amount_eur: {
- sql: `${amount_usd} * 0.9`,
- type: `number`
- },
-
- amount_gbp: {
- sql: `${amount_usd} * 0.8`,
- type: `number`
- },
-
- amount_in_currency: {
- multi_stage: true,
- case: {
- switch: `${currency}`,
- when: [
- { value: `EUR`, sql: `${amount_eur}` },
- { value: `GBP`, sql: `${amount_gbp}` }
- ],
- else: { sql: `${amount_usd}` }
- },
- type: `number`
- }
- }
-})
-```
-
-
-
-Query and result:
-
-
-  -
-
-## Fixed dimension
-
-Fixed dimension calculations can be used to perform fixed comparisons, e.g., to compare
-individual items to a broader dataset. Use the [`group_by` parameter][ref-group-by]
-of a multi-stage measure to specify dimensions for the inner aggregation stage.
-
-For example, comparing revenue sales to the overall average:
-
-```yaml
-- name: revenue
- sql: revenue
- format: currency
- type: sum
-
-- name: occupied_sq_feet
- sql: occupied_sq_feet
- type: sum
-
-- name: occupied_sq_feet_per_city
- multi_stage: true
- sql: "{occupied_sq_feet}"
- type: sum
- group_by:
- - city
- - state
-
-- name: revenue_per_city_sq_feet
- multi_stage: true
- sql: "{revenue} / NULLIF({occupied_sq_feet_per_city}, 0)"
- type: number
-```
-
-Percent of total calculations:
-
-```yaml
-- name: revenue
- sql: revenue
- format: currency
- type: sum
-
-- name: country_revenue
- multi_stage: true
- sql: "{revenue}"
- type: sum
- group_by:
- - country
-
-- name: country_revenue_percentage
- multi_stage: true
- sql: "{revenue} / NULLIF({country_revenue}, 0)"
- type: number
-```
-
-### Example
-
-Data model:
-
-```yaml
-cubes:
- - name: percent_of_total
- sql: |
- SELECT 1 AS id, 1000 AS revenue, 'A' AS product, 'USA' AS country UNION ALL
- SELECT 2 AS id, 2000 AS revenue, 'B' AS product, 'USA' AS country UNION ALL
- SELECT 3 AS id, 3000 AS revenue, 'A' AS product, 'Austria' AS country UNION ALL
- SELECT 4 AS id, 4000 AS revenue, 'B' AS product, 'Austria' AS country UNION ALL
- SELECT 5 AS id, 5000 AS revenue, 'A' AS product, 'Netherlands' AS country UNION ALL
- SELECT 6 AS id, 6000 AS revenue, 'B' AS product, 'Netherlands' AS country
-
- dimensions:
- - name: product
- sql: product
- type: string
-
- - name: country
- sql: country
- type: string
-
- measures:
- - name: revenue
- sql: revenue
- format: currency
- type: sum
-
- - name: country_revenue
- multi_stage: true
- sql: "{revenue}"
- format: currency
- type: sum
- group_by:
- - country
-
- - name: country_revenue_percentage
- multi_stage: true
- sql: "{revenue} / NULLIF({country_revenue}, 0)"
- type: number
-```
-
-Query and result:
-
-
-
-
-
-## Fixed dimension
-
-Fixed dimension calculations can be used to perform fixed comparisons, e.g., to compare
-individual items to a broader dataset. Use the [`group_by` parameter][ref-group-by]
-of a multi-stage measure to specify dimensions for the inner aggregation stage.
-
-For example, comparing revenue sales to the overall average:
-
-```yaml
-- name: revenue
- sql: revenue
- format: currency
- type: sum
-
-- name: occupied_sq_feet
- sql: occupied_sq_feet
- type: sum
-
-- name: occupied_sq_feet_per_city
- multi_stage: true
- sql: "{occupied_sq_feet}"
- type: sum
- group_by:
- - city
- - state
-
-- name: revenue_per_city_sq_feet
- multi_stage: true
- sql: "{revenue} / NULLIF({occupied_sq_feet_per_city}, 0)"
- type: number
-```
-
-Percent of total calculations:
-
-```yaml
-- name: revenue
- sql: revenue
- format: currency
- type: sum
-
-- name: country_revenue
- multi_stage: true
- sql: "{revenue}"
- type: sum
- group_by:
- - country
-
-- name: country_revenue_percentage
- multi_stage: true
- sql: "{revenue} / NULLIF({country_revenue}, 0)"
- type: number
-```
-
-### Example
-
-Data model:
-
-```yaml
-cubes:
- - name: percent_of_total
- sql: |
- SELECT 1 AS id, 1000 AS revenue, 'A' AS product, 'USA' AS country UNION ALL
- SELECT 2 AS id, 2000 AS revenue, 'B' AS product, 'USA' AS country UNION ALL
- SELECT 3 AS id, 3000 AS revenue, 'A' AS product, 'Austria' AS country UNION ALL
- SELECT 4 AS id, 4000 AS revenue, 'B' AS product, 'Austria' AS country UNION ALL
- SELECT 5 AS id, 5000 AS revenue, 'A' AS product, 'Netherlands' AS country UNION ALL
- SELECT 6 AS id, 6000 AS revenue, 'B' AS product, 'Netherlands' AS country
-
- dimensions:
- - name: product
- sql: product
- type: string
-
- - name: country
- sql: country
- type: string
-
- measures:
- - name: revenue
- sql: revenue
- format: currency
- type: sum
-
- - name: country_revenue
- multi_stage: true
- sql: "{revenue}"
- format: currency
- type: sum
- group_by:
- - country
-
- - name: country_revenue_percentage
- multi_stage: true
- sql: "{revenue} / NULLIF({country_revenue}, 0)"
- type: number
-```
-
-Query and result:
-
-
-  -
-
-## Nested aggregate
-
-Nested aggregate calculations are used to compute an aggregate of an aggregate, e.g.,
-to calculate the average of per-customer averages or to count how many customers exceed
-a threshold. Use the [`add_group_by` parameter][ref-add-group-by] of a multi-stage
-measure to specify dimensions for the inner aggregation stage.
-
-For example, calculating the average order value per customer, then averaging across
-customers:
-
-```yaml
-- name: avg_order_value
- sql: amount
- type: avg
-
-- name: avg_customer_order_value
- multi_stage: true
- sql: "{avg_order_value}"
- type: avg
- add_group_by:
- - customer_id
-```
-
-Counting customers with total spending above a threshold:
-
-```yaml
-- name: total_amount
- sql: amount
- type: sum
-
-- name: high_value_customer_count
- multi_stage: true
- sql: "CASE WHEN {total_amount} > 1000 THEN 1 END"
- type: count
- add_group_by:
- - customer_id
-```
-
-### Example
-
-Data model:
-
-```yaml
-cubes:
- - name: orders
- sql: |
- SELECT 1 AS id, 100 AS amount, 1 AS customer_id, 'USA' AS country UNION ALL
- SELECT 2 AS id, 150 AS amount, 1 AS customer_id, 'USA' AS country UNION ALL
- SELECT 3 AS id, 200 AS amount, 2 AS customer_id, 'USA' AS country UNION ALL
- SELECT 4 AS id, 300 AS amount, 2 AS customer_id, 'USA' AS country UNION ALL
- SELECT 5 AS id, 400 AS amount, 2 AS customer_id, 'USA' AS country UNION ALL
- SELECT 6 AS id, 500 AS amount, 3 AS customer_id, 'Germany' AS country UNION ALL
- SELECT 7 AS id, 600 AS amount, 3 AS customer_id, 'Germany' AS country UNION ALL
- SELECT 8 AS id, 250 AS amount, 4 AS customer_id, 'Germany' AS country
-
- dimensions:
- - name: customer_id
- sql: customer_id
- type: number
-
- - name: country
- sql: country
- type: string
-
- measures:
- - name: avg_order_value
- sql: amount
- type: avg
-
- - name: avg_customer_order_value
- multi_stage: true
- sql: "{avg_order_value}"
- type: avg
- add_group_by:
- - customer_id
-```
-
-When querying `avg_customer_order_value` grouped by `country`, Cube computes the average
-order value per customer first (inner stage), then averages those values per country
-(outer stage). This gives equal weight to each customer regardless of order count.
-
-## Ranking
-
-Ranking calculations can be used to get valuable insights, especially when analyzing
-data across various dimensions. Use the [`reduce_by` parameter][ref-reduce-by] of a
-multi-stage measure to specify dimensions to exclude from the inner aggregation stage.
-
-```yaml
-- name: product_rank
- multi_stage: true
- order_by:
- - sql: "{revenue}"
- dir: asc
- reduce_by:
- - product
- type: rank
-```
-
-You can reduce by one or more dimensions.
-
-### Example
-
-Data model:
-
-```yaml
-cubes:
- - name: ranking
- sql: |
- SELECT 1 AS id, 1000 AS revenue, 'A' AS product, 'USA' AS country UNION ALL
- SELECT 2 AS id, 2000 AS revenue, 'B' AS product, 'USA' AS country UNION ALL
- SELECT 3 AS id, 3000 AS revenue, 'A' AS product, 'Austria' AS country UNION ALL
- SELECT 4 AS id, 4000 AS revenue, 'B' AS product, 'Austria' AS country UNION ALL
- SELECT 5 AS id, 5000 AS revenue, 'A' AS product, 'Netherlands' AS country UNION ALL
- SELECT 6 AS id, 6000 AS revenue, 'B' AS product, 'Netherlands' AS country
-
- dimensions:
- - name: product
- sql: product
- type: string
-
- - name: country
- sql: country
- type: string
-
- measures:
- - name: revenue
- sql: revenue
- format: currency
- type: sum
-
- - name: product_rank
- multi_stage: true
- order_by:
- - sql: "{revenue}"
- dir: asc
- reduce_by:
- - product
- type: rank
-```
-
-Query and result:
-
-
-
-
-
-## Nested aggregate
-
-Nested aggregate calculations are used to compute an aggregate of an aggregate, e.g.,
-to calculate the average of per-customer averages or to count how many customers exceed
-a threshold. Use the [`add_group_by` parameter][ref-add-group-by] of a multi-stage
-measure to specify dimensions for the inner aggregation stage.
-
-For example, calculating the average order value per customer, then averaging across
-customers:
-
-```yaml
-- name: avg_order_value
- sql: amount
- type: avg
-
-- name: avg_customer_order_value
- multi_stage: true
- sql: "{avg_order_value}"
- type: avg
- add_group_by:
- - customer_id
-```
-
-Counting customers with total spending above a threshold:
-
-```yaml
-- name: total_amount
- sql: amount
- type: sum
-
-- name: high_value_customer_count
- multi_stage: true
- sql: "CASE WHEN {total_amount} > 1000 THEN 1 END"
- type: count
- add_group_by:
- - customer_id
-```
-
-### Example
-
-Data model:
-
-```yaml
-cubes:
- - name: orders
- sql: |
- SELECT 1 AS id, 100 AS amount, 1 AS customer_id, 'USA' AS country UNION ALL
- SELECT 2 AS id, 150 AS amount, 1 AS customer_id, 'USA' AS country UNION ALL
- SELECT 3 AS id, 200 AS amount, 2 AS customer_id, 'USA' AS country UNION ALL
- SELECT 4 AS id, 300 AS amount, 2 AS customer_id, 'USA' AS country UNION ALL
- SELECT 5 AS id, 400 AS amount, 2 AS customer_id, 'USA' AS country UNION ALL
- SELECT 6 AS id, 500 AS amount, 3 AS customer_id, 'Germany' AS country UNION ALL
- SELECT 7 AS id, 600 AS amount, 3 AS customer_id, 'Germany' AS country UNION ALL
- SELECT 8 AS id, 250 AS amount, 4 AS customer_id, 'Germany' AS country
-
- dimensions:
- - name: customer_id
- sql: customer_id
- type: number
-
- - name: country
- sql: country
- type: string
-
- measures:
- - name: avg_order_value
- sql: amount
- type: avg
-
- - name: avg_customer_order_value
- multi_stage: true
- sql: "{avg_order_value}"
- type: avg
- add_group_by:
- - customer_id
-```
-
-When querying `avg_customer_order_value` grouped by `country`, Cube computes the average
-order value per customer first (inner stage), then averages those values per country
-(outer stage). This gives equal weight to each customer regardless of order count.
-
-## Ranking
-
-Ranking calculations can be used to get valuable insights, especially when analyzing
-data across various dimensions. Use the [`reduce_by` parameter][ref-reduce-by] of a
-multi-stage measure to specify dimensions to exclude from the inner aggregation stage.
-
-```yaml
-- name: product_rank
- multi_stage: true
- order_by:
- - sql: "{revenue}"
- dir: asc
- reduce_by:
- - product
- type: rank
-```
-
-You can reduce by one or more dimensions.
-
-### Example
-
-Data model:
-
-```yaml
-cubes:
- - name: ranking
- sql: |
- SELECT 1 AS id, 1000 AS revenue, 'A' AS product, 'USA' AS country UNION ALL
- SELECT 2 AS id, 2000 AS revenue, 'B' AS product, 'USA' AS country UNION ALL
- SELECT 3 AS id, 3000 AS revenue, 'A' AS product, 'Austria' AS country UNION ALL
- SELECT 4 AS id, 4000 AS revenue, 'B' AS product, 'Austria' AS country UNION ALL
- SELECT 5 AS id, 5000 AS revenue, 'A' AS product, 'Netherlands' AS country UNION ALL
- SELECT 6 AS id, 6000 AS revenue, 'B' AS product, 'Netherlands' AS country
-
- dimensions:
- - name: product
- sql: product
- type: string
-
- - name: country
- sql: country
- type: string
-
- measures:
- - name: revenue
- sql: revenue
- format: currency
- type: sum
-
- - name: product_rank
- multi_stage: true
- order_by:
- - sql: "{revenue}"
- dir: asc
- reduce_by:
- - product
- type: rank
-```
-
-Query and result:
-
-
-  -
-
-
-[link-tesseract]: https://cube.dev/blog/introducing-next-generation-data-modeling-engine
-[ref-measures]: /docs/data-modeling/concepts#measures
-[ref-dimensions]: /docs/data-modeling/concepts#dimensions
-[ref-rolling-window]: /reference/data-modeling/measures#rolling_window
-[link-cte]: https://en.wikipedia.org/wiki/Hierarchical_and_recursive_queries_in_SQL#Common_table_expression
-[ref-ref-time-shift]: /reference/data-modeling/measures#time_shift
-[ref-calendar-cubes]: /docs/data-modeling/concepts/calendar-cubes
-[ref-case-measures]: /reference/data-modeling/measures#case
-[ref-switch-dimensions]: /reference/data-modeling/dimensions#type
-[ref-group-by]: /reference/data-modeling/measures#group_by
-[ref-reduce-by]: /reference/data-modeling/measures#reduce_by
-[ref-add-group-by]: /reference/data-modeling/measures#add_group_by
\ No newline at end of file
diff --git a/docs-mintlify/docs/data-modeling/concepts/syntax.mdx b/docs-mintlify/docs/data-modeling/concepts/syntax.mdx
index b184059a560be..2765b621d0d93 100644
--- a/docs-mintlify/docs/data-modeling/concepts/syntax.mdx
+++ b/docs-mintlify/docs/data-modeling/concepts/syntax.mdx
@@ -981,25 +981,25 @@ string values in time dimensions.
[ref-context-variables]: /reference/data-modeling/context-variables
[ref-config-model-path]: /reference/configuration/config#schemapath
[ref-config-repository-factory]: /reference/configuration/config#repositoryfactory
-[ref-subquery]: /docs/data-modeling/concepts/calculated-members#subquery-dimensions
+[ref-subquery]: /docs/data-modeling/dimensions#subquery-dimensions
[wiki-snake-case]: https://en.wikipedia.org/wiki/Snake_case
[wiki-yaml]: https://en.wikipedia.org/wiki/YAML
[link-snowflake-listagg]: https://docs.snowflake.com/en/sql-reference/functions/listagg
[link-bigquery-stringagg]: https://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators#string_agg
[link-sql-udf]: https://en.wikipedia.org/wiki/User-defined_function#Databases
[ref-time-dimension]: /reference/data-modeling/dimensions#type
-[ref-default-granularities]: /docs/data-modeling/concepts#time-dimensions
+[ref-default-granularities]: /docs/data-modeling/dimensions#time-dimensions
[ref-custom-granularities]: /reference/data-modeling/dimensions#granularities
[ref-style-guide]: /recipes/data-modeling/style-guide
-[ref-polymorphism]: /docs/data-modeling/concepts/polymorphic-cubes
+[ref-polymorphism]: /recipes/data-modeling/polymorphic-cubes
[ref-data-blending]: /docs/data-modeling/concepts/data-blending
[link-js-template-literals]: https://developer.mozilla.org/en-US/docs/Learn_web_development/Core/Scripting/Strings#embedding_javascript
[link-python-reserved-words]: https://docs.python.org/3/reference/lexical_analysis.html#keywords
[ref-dax-api-date-hierarchies]: /reference/dax-api#date-hierarchies
-[ref-time-dimension]: /docs/data-modeling/concepts#time-dimensions
+[ref-time-dimension]: /docs/data-modeling/dimensions#time-dimensions
[ref-recipe-string-time-dimensions]: /recipes/data-modeling/string-time-dimensions
-[ref-views]: /docs/data-modeling/concepts#views
-[ref-preaggs]: /docs/data-modeling/concepts#pre-aggregations
-[ref-join-paths]: /docs/data-modeling/concepts/working-with-joins#join-paths
-[ref-calculated-members]: /docs/data-modeling/concepts/calculated-members
-[ref-diamond-subgraphs]: /docs/data-modeling/concepts/working-with-joins#diamond-subgraphs
\ No newline at end of file
+[ref-views]: /docs/data-modeling/views
+[ref-preaggs]: /reference/data-modeling/pre-aggregations
+[ref-join-paths]: /docs/data-modeling/joins#join-paths
+[ref-calculated-members]: /docs/data-modeling/measures#calculated-measures
+[ref-diamond-subgraphs]: /docs/data-modeling/joins#diamond-subgraphs
\ No newline at end of file
diff --git a/docs-mintlify/docs/data-modeling/concepts/working-with-joins.mdx b/docs-mintlify/docs/data-modeling/concepts/working-with-joins.mdx
deleted file mode 100644
index afc8e2283f203..0000000000000
--- a/docs-mintlify/docs/data-modeling/concepts/working-with-joins.mdx
+++ /dev/null
@@ -1,1945 +0,0 @@
----
-title: Joins between cubes
-description: "Joins create relationships between cubes in the data model."
----
-
-They allow to build complex [queries][ref-queries] that involve members from multiple
-cubes. They also allow to [reference][ref-references] members from other cubes in
-[calculated members][ref-calculated-members], [views][ref-views], and
-[pre-aggregations][ref-preaggs].
-
-When defining joins, it's important to understand [join types](#join-types) and the
-[direction of joins](#direction-of-joins) as well as how [join paths](#join-paths) and
-[join hints](#join-hints) are used to work with the joined cubes.
-
-## Join types
-
-Cube supports three [types of join relationships][ref-schema-ref-joins-relationship]
-often found in SQL databases: `one_to_one`, `one_to_many`, and `many_to_one`.
-
-For example, let's take two cubes, `customers` and `orders`:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: customers
- # ...
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: company
- sql: company
- type: string
-
- - name: orders
- # ...
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: customer_id
- sql: customer_id
- type: number
-```
-
-```javascript title="JavaScript"
-cube(`customers`, {
- // ...
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- company: {
- sql: `company`,
- type: `string`
- }
- }
-})
-
-cube(`orders`, {
- // ...
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- customer_id: {
- sql: `customer_id`,
- type: `number`
- }
- }
-})
-```
-
-
-
-We could add a join to the `customers` cube:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: customers
- # ...
-
- joins:
- - name: orders
- relationship: one_to_many
- sql: "{CUBE}.id = {orders.customer_id}"
-```
-
-```javascript title="JavaScript"
-cube(`customers`, {
- // ...
-
- joins: {
- orders: {
- relationship: `one_to_many`,
- sql: `${CUBE}.id = ${orders.customer_id}`
- }
- }
-})
-```
-
-
-
-The join above means a customer has many orders. Let's send the following JSON
-query:
-
-```json
-{
- "dimensions": ["orders.status", "customers.company"],
- "measures": ["orders.count"],
- "timeDimensions": [
- {
- "dimension": "orders.created_at"
- }
- ],
- "order": { "customers.company": "asc" }
-}
-```
-
-The query above will generate the following SQL:
-
-```sql
-SELECT
- "orders".status "orders__status",
- "customers".company "customers__company",
- count("orders".id) "orders__count"
-FROM
- public.customers AS "customers"
- LEFT JOIN public.orders AS "orders"
- ON "customers".id = "orders".customer_id
-GROUP BY 1, 2
-ORDER BY 2 ASC
-LIMIT 10000
-```
-
-However, if we have guest checkouts, that would mean we would have orders with
-no matching customer. Looking back at the `one_to_many` relationship and its'
-resulting SQL, any guest checkouts would be excluded from the results. To remedy
-this, we'll remove the join from the `customers` cube and instead define a join
-with a `many_to_one` relationship on the `orders` cube:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- # ...
-
- joins:
- - name: customers
- relationship: many_to_one
- sql: "{CUBE}.customer_id = {customers.id}"
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- // ...
-
- joins: {
- customers: {
- relationship: `many_to_one`,
- sql: `${CUBE}.customer_id = ${customers.id}`
- }
- }
-})
-```
-
-
-
-In the above data model, our `orders` cube defines the relationship between
-itself and the `customer` cube. The same JSON query now results in the following
-SQL query:
-
-```sql
-SELECT
- "orders".status "orders__status",
- "customers".company "customers__company",
- count("orders".id) "orders__count"
-FROM
- public.orders AS "orders"
- LEFT JOIN public.customers AS "customers"
- ON "orders".customer_id = "customers".id
-GROUP BY 1, 2
-ORDER BY 2 ASC
-LIMIT 10000
-```
-
-As we can see, the base table in the query is `orders`, and `customers` is in
-the `LEFT JOIN` clause; this means any orders without a customer will also be
-retrieved.
-
-### Many-to-many joins
-
-A many-to-many relationship occurs when multiple records in a cube are
-associated with multiple records in another cube.
-
-For example, let's say we have two cubes, `topics` and `posts`, pointing to the
-`topics` and `posts` tables in our database, respectively. A `post` can have
-more than one `topic`, and a `topic` may have more than one `post`.
-
-In a database, you would most likely have an associative table (also known as a
-junction table or cross-reference table). In our example, this table name might
-be `post_topics`.
-
-The diagram below shows the tables `posts`, `topics`, `post_topics`, and their
-relationships.
-
-
-
-
-
-
-[link-tesseract]: https://cube.dev/blog/introducing-next-generation-data-modeling-engine
-[ref-measures]: /docs/data-modeling/concepts#measures
-[ref-dimensions]: /docs/data-modeling/concepts#dimensions
-[ref-rolling-window]: /reference/data-modeling/measures#rolling_window
-[link-cte]: https://en.wikipedia.org/wiki/Hierarchical_and_recursive_queries_in_SQL#Common_table_expression
-[ref-ref-time-shift]: /reference/data-modeling/measures#time_shift
-[ref-calendar-cubes]: /docs/data-modeling/concepts/calendar-cubes
-[ref-case-measures]: /reference/data-modeling/measures#case
-[ref-switch-dimensions]: /reference/data-modeling/dimensions#type
-[ref-group-by]: /reference/data-modeling/measures#group_by
-[ref-reduce-by]: /reference/data-modeling/measures#reduce_by
-[ref-add-group-by]: /reference/data-modeling/measures#add_group_by
\ No newline at end of file
diff --git a/docs-mintlify/docs/data-modeling/concepts/syntax.mdx b/docs-mintlify/docs/data-modeling/concepts/syntax.mdx
index b184059a560be..2765b621d0d93 100644
--- a/docs-mintlify/docs/data-modeling/concepts/syntax.mdx
+++ b/docs-mintlify/docs/data-modeling/concepts/syntax.mdx
@@ -981,25 +981,25 @@ string values in time dimensions.
[ref-context-variables]: /reference/data-modeling/context-variables
[ref-config-model-path]: /reference/configuration/config#schemapath
[ref-config-repository-factory]: /reference/configuration/config#repositoryfactory
-[ref-subquery]: /docs/data-modeling/concepts/calculated-members#subquery-dimensions
+[ref-subquery]: /docs/data-modeling/dimensions#subquery-dimensions
[wiki-snake-case]: https://en.wikipedia.org/wiki/Snake_case
[wiki-yaml]: https://en.wikipedia.org/wiki/YAML
[link-snowflake-listagg]: https://docs.snowflake.com/en/sql-reference/functions/listagg
[link-bigquery-stringagg]: https://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators#string_agg
[link-sql-udf]: https://en.wikipedia.org/wiki/User-defined_function#Databases
[ref-time-dimension]: /reference/data-modeling/dimensions#type
-[ref-default-granularities]: /docs/data-modeling/concepts#time-dimensions
+[ref-default-granularities]: /docs/data-modeling/dimensions#time-dimensions
[ref-custom-granularities]: /reference/data-modeling/dimensions#granularities
[ref-style-guide]: /recipes/data-modeling/style-guide
-[ref-polymorphism]: /docs/data-modeling/concepts/polymorphic-cubes
+[ref-polymorphism]: /recipes/data-modeling/polymorphic-cubes
[ref-data-blending]: /docs/data-modeling/concepts/data-blending
[link-js-template-literals]: https://developer.mozilla.org/en-US/docs/Learn_web_development/Core/Scripting/Strings#embedding_javascript
[link-python-reserved-words]: https://docs.python.org/3/reference/lexical_analysis.html#keywords
[ref-dax-api-date-hierarchies]: /reference/dax-api#date-hierarchies
-[ref-time-dimension]: /docs/data-modeling/concepts#time-dimensions
+[ref-time-dimension]: /docs/data-modeling/dimensions#time-dimensions
[ref-recipe-string-time-dimensions]: /recipes/data-modeling/string-time-dimensions
-[ref-views]: /docs/data-modeling/concepts#views
-[ref-preaggs]: /docs/data-modeling/concepts#pre-aggregations
-[ref-join-paths]: /docs/data-modeling/concepts/working-with-joins#join-paths
-[ref-calculated-members]: /docs/data-modeling/concepts/calculated-members
-[ref-diamond-subgraphs]: /docs/data-modeling/concepts/working-with-joins#diamond-subgraphs
\ No newline at end of file
+[ref-views]: /docs/data-modeling/views
+[ref-preaggs]: /reference/data-modeling/pre-aggregations
+[ref-join-paths]: /docs/data-modeling/joins#join-paths
+[ref-calculated-members]: /docs/data-modeling/measures#calculated-measures
+[ref-diamond-subgraphs]: /docs/data-modeling/joins#diamond-subgraphs
\ No newline at end of file
diff --git a/docs-mintlify/docs/data-modeling/concepts/working-with-joins.mdx b/docs-mintlify/docs/data-modeling/concepts/working-with-joins.mdx
deleted file mode 100644
index afc8e2283f203..0000000000000
--- a/docs-mintlify/docs/data-modeling/concepts/working-with-joins.mdx
+++ /dev/null
@@ -1,1945 +0,0 @@
----
-title: Joins between cubes
-description: "Joins create relationships between cubes in the data model."
----
-
-They allow to build complex [queries][ref-queries] that involve members from multiple
-cubes. They also allow to [reference][ref-references] members from other cubes in
-[calculated members][ref-calculated-members], [views][ref-views], and
-[pre-aggregations][ref-preaggs].
-
-When defining joins, it's important to understand [join types](#join-types) and the
-[direction of joins](#direction-of-joins) as well as how [join paths](#join-paths) and
-[join hints](#join-hints) are used to work with the joined cubes.
-
-## Join types
-
-Cube supports three [types of join relationships][ref-schema-ref-joins-relationship]
-often found in SQL databases: `one_to_one`, `one_to_many`, and `many_to_one`.
-
-For example, let's take two cubes, `customers` and `orders`:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: customers
- # ...
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: company
- sql: company
- type: string
-
- - name: orders
- # ...
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: customer_id
- sql: customer_id
- type: number
-```
-
-```javascript title="JavaScript"
-cube(`customers`, {
- // ...
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- company: {
- sql: `company`,
- type: `string`
- }
- }
-})
-
-cube(`orders`, {
- // ...
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- customer_id: {
- sql: `customer_id`,
- type: `number`
- }
- }
-})
-```
-
-
-
-We could add a join to the `customers` cube:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: customers
- # ...
-
- joins:
- - name: orders
- relationship: one_to_many
- sql: "{CUBE}.id = {orders.customer_id}"
-```
-
-```javascript title="JavaScript"
-cube(`customers`, {
- // ...
-
- joins: {
- orders: {
- relationship: `one_to_many`,
- sql: `${CUBE}.id = ${orders.customer_id}`
- }
- }
-})
-```
-
-
-
-The join above means a customer has many orders. Let's send the following JSON
-query:
-
-```json
-{
- "dimensions": ["orders.status", "customers.company"],
- "measures": ["orders.count"],
- "timeDimensions": [
- {
- "dimension": "orders.created_at"
- }
- ],
- "order": { "customers.company": "asc" }
-}
-```
-
-The query above will generate the following SQL:
-
-```sql
-SELECT
- "orders".status "orders__status",
- "customers".company "customers__company",
- count("orders".id) "orders__count"
-FROM
- public.customers AS "customers"
- LEFT JOIN public.orders AS "orders"
- ON "customers".id = "orders".customer_id
-GROUP BY 1, 2
-ORDER BY 2 ASC
-LIMIT 10000
-```
-
-However, if we have guest checkouts, that would mean we would have orders with
-no matching customer. Looking back at the `one_to_many` relationship and its'
-resulting SQL, any guest checkouts would be excluded from the results. To remedy
-this, we'll remove the join from the `customers` cube and instead define a join
-with a `many_to_one` relationship on the `orders` cube:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- # ...
-
- joins:
- - name: customers
- relationship: many_to_one
- sql: "{CUBE}.customer_id = {customers.id}"
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- // ...
-
- joins: {
- customers: {
- relationship: `many_to_one`,
- sql: `${CUBE}.customer_id = ${customers.id}`
- }
- }
-})
-```
-
-
-
-In the above data model, our `orders` cube defines the relationship between
-itself and the `customer` cube. The same JSON query now results in the following
-SQL query:
-
-```sql
-SELECT
- "orders".status "orders__status",
- "customers".company "customers__company",
- count("orders".id) "orders__count"
-FROM
- public.orders AS "orders"
- LEFT JOIN public.customers AS "customers"
- ON "orders".customer_id = "customers".id
-GROUP BY 1, 2
-ORDER BY 2 ASC
-LIMIT 10000
-```
-
-As we can see, the base table in the query is `orders`, and `customers` is in
-the `LEFT JOIN` clause; this means any orders without a customer will also be
-retrieved.
-
-### Many-to-many joins
-
-A many-to-many relationship occurs when multiple records in a cube are
-associated with multiple records in another cube.
-
-For example, let's say we have two cubes, `topics` and `posts`, pointing to the
-`topics` and `posts` tables in our database, respectively. A `post` can have
-more than one `topic`, and a `topic` may have more than one `post`.
-
-In a database, you would most likely have an associative table (also known as a
-junction table or cross-reference table). In our example, this table name might
-be `post_topics`.
-
-The diagram below shows the tables `posts`, `topics`, `post_topics`, and their
-relationships.
-
-
-  -
-
-In the same way the `post_topics` table was specifically created to handle this
-association in the database, we need to create an associative cube
-`post_topics`, and declare the relationships from it to `topics` cube and from
-`posts` to `post_topics`.
-
-
-
-```yaml title="YAML"
-cubes:
- - name: posts
- sql_table: posts
-
- joins:
- - name: post_topics
- relationship: one_to_many
- sql: "{CUBE}.id = {post_topics.post_id}"
-
- - name: topics
- sql_table: topics
-
- dimensions:
- - name: post_id
- sql: id
- type: string
- primary_key: true
-
- - name: post_topics
- sql_table: post_topics
-
- joins:
- - name: topic
- relationship: many_to_one
- sql: "{CUBE}.topic_id = {topics.id}"
-
- dimensions:
- - name: post_id
- sql: post_id
- type: string
-```
-
-```javascript title="JavaScript"
-cube(`posts`, {
- sql_table: `posts`,
-
- joins: {
- post_topics: {
- relationship: `one_to_many`,
- sql: `${CUBE}.id = ${post_topics.post_id}`
- }
- }
-})
-
-cube(`topics`, {
- sql_table: `topics`,
-
- dimensions: {
- post_id: {
- sql: `id`,
- type: `string`,
- primary_key: true
- }
- }
-})
-
-cube(`post_topics`, {
- sql_table: `post_topics`,
-
- joins: {
- topic: {
- relationship: `many_to_one`,
- sql: `${CUBE}.topic_id = ${topics.id}`
- }
- },
-
- dimensions: {
- post_id: {
- sql: `post_id`,
- type: `string`
- }
- }
-})
-```
-
-
-
-
-
-The following example uses the `many_to_one` relationship on the `post_topics`
-cube; this causes the direction of joins to be `posts → post_topics → topics`.
-Read more about the [direction of joins](#direction-of-joins).
-
-
-
-In scenarios where a table doesn't define a primary key, one can be generated
-using SQL:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: post_topics
- # ...
-
- dimensions:
- - name: id
- sql: "CONCAT({CUBE}.post_id, {CUBE}.topic_id)"
- type: number
- primary_key: true
-```
-
-```javascript title="JavaScript"
-cube(`post_topics`, {
- // ...
-
- dimensions: {
- id: {
- sql: `CONCAT(${CUBE}.post_id, ${CUBE}.topic_id)`,
- type: `number`,
- primary_key: true
- }
- }
-})
-```
-
-
-
-**Virtual associative cubes.**
-Sometimes there is no associative table in the database, when in reality, there
-is a many-to-many relationship. In this case, the solution is to extract some
-data from existing tables and create a virtual (not backed by a real table in
-the database) associative cube.
-
-Let’s consider the following example. We have tables `emails` and
-`transactions`. The goal is to calculate the amount of transactions per
-campaign. Both `emails` and `transactions` have a `campaign_id` column. We don’t
-have a campaigns table, but data about campaigns is part of the `emails` table.
-
-Let’s take a look at the `emails` cube first:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: emails
- sql_table: emails
-
- measures:
- - name: count
- type: count
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: campaign_name
- sql: campaign_name
- type: string
-
- - name: campaign_id
- sql: campaign_id
- type: number
-```
-
-```javascript title="JavaScript"
-cube(`emails`, {
- sql_table: `emails`,
-
- measures: {
- count: {
- type: `count`
- }
- },
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- campaign_name: {
- sql: `campaign_name`,
- type: `string`
- },
-
- campaign_id: {
- sql: `campaign_id`,
- type: `number`
- }
- }
-})
-```
-
-
-
-We can extract campaigns data into a virtual `campaigns` cube:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: campaigns
- sql: |
- SELECT
- campaign_id,
- campaign_name,
- customer_name,
- MIN(created_at) AS started_at
- FROM emails GROUP BY 1, 2, 3
-
- measures:
- - name: count
- type: count
-
- dimensions:
- - name: id
- sql: campaign_id
- type: string
- primary_key: true
-
- - name: name
- sql: campaign_name
- type: string
-```
-
-```javascript title="JavaScript"
-cube(`campaigns`, {
- sql: `
- SELECT
- campaign_id,
- campaign_name,
- customer_name,
- MIN(created_at) AS started_at
- FROM emails
- GROUP BY 1, 2, 3
- `,
-
- measures: {
- count: {
- type: `count`
- }
- },
-
- dimensions: {
- id: {
- sql: `campaign_id`,
- type: `string`,
- primary_key: true
- },
-
- name: {
- sql: `campaign_name`,
- type: `string`
- }
- }
-})
-```
-
-
-
-The following diagram shows our data model with the `Campaigns` cube:
-
-
-
-
-
-In the same way the `post_topics` table was specifically created to handle this
-association in the database, we need to create an associative cube
-`post_topics`, and declare the relationships from it to `topics` cube and from
-`posts` to `post_topics`.
-
-
-
-```yaml title="YAML"
-cubes:
- - name: posts
- sql_table: posts
-
- joins:
- - name: post_topics
- relationship: one_to_many
- sql: "{CUBE}.id = {post_topics.post_id}"
-
- - name: topics
- sql_table: topics
-
- dimensions:
- - name: post_id
- sql: id
- type: string
- primary_key: true
-
- - name: post_topics
- sql_table: post_topics
-
- joins:
- - name: topic
- relationship: many_to_one
- sql: "{CUBE}.topic_id = {topics.id}"
-
- dimensions:
- - name: post_id
- sql: post_id
- type: string
-```
-
-```javascript title="JavaScript"
-cube(`posts`, {
- sql_table: `posts`,
-
- joins: {
- post_topics: {
- relationship: `one_to_many`,
- sql: `${CUBE}.id = ${post_topics.post_id}`
- }
- }
-})
-
-cube(`topics`, {
- sql_table: `topics`,
-
- dimensions: {
- post_id: {
- sql: `id`,
- type: `string`,
- primary_key: true
- }
- }
-})
-
-cube(`post_topics`, {
- sql_table: `post_topics`,
-
- joins: {
- topic: {
- relationship: `many_to_one`,
- sql: `${CUBE}.topic_id = ${topics.id}`
- }
- },
-
- dimensions: {
- post_id: {
- sql: `post_id`,
- type: `string`
- }
- }
-})
-```
-
-
-
-
-
-The following example uses the `many_to_one` relationship on the `post_topics`
-cube; this causes the direction of joins to be `posts → post_topics → topics`.
-Read more about the [direction of joins](#direction-of-joins).
-
-
-
-In scenarios where a table doesn't define a primary key, one can be generated
-using SQL:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: post_topics
- # ...
-
- dimensions:
- - name: id
- sql: "CONCAT({CUBE}.post_id, {CUBE}.topic_id)"
- type: number
- primary_key: true
-```
-
-```javascript title="JavaScript"
-cube(`post_topics`, {
- // ...
-
- dimensions: {
- id: {
- sql: `CONCAT(${CUBE}.post_id, ${CUBE}.topic_id)`,
- type: `number`,
- primary_key: true
- }
- }
-})
-```
-
-
-
-**Virtual associative cubes.**
-Sometimes there is no associative table in the database, when in reality, there
-is a many-to-many relationship. In this case, the solution is to extract some
-data from existing tables and create a virtual (not backed by a real table in
-the database) associative cube.
-
-Let’s consider the following example. We have tables `emails` and
-`transactions`. The goal is to calculate the amount of transactions per
-campaign. Both `emails` and `transactions` have a `campaign_id` column. We don’t
-have a campaigns table, but data about campaigns is part of the `emails` table.
-
-Let’s take a look at the `emails` cube first:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: emails
- sql_table: emails
-
- measures:
- - name: count
- type: count
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: campaign_name
- sql: campaign_name
- type: string
-
- - name: campaign_id
- sql: campaign_id
- type: number
-```
-
-```javascript title="JavaScript"
-cube(`emails`, {
- sql_table: `emails`,
-
- measures: {
- count: {
- type: `count`
- }
- },
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- campaign_name: {
- sql: `campaign_name`,
- type: `string`
- },
-
- campaign_id: {
- sql: `campaign_id`,
- type: `number`
- }
- }
-})
-```
-
-
-
-We can extract campaigns data into a virtual `campaigns` cube:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: campaigns
- sql: |
- SELECT
- campaign_id,
- campaign_name,
- customer_name,
- MIN(created_at) AS started_at
- FROM emails GROUP BY 1, 2, 3
-
- measures:
- - name: count
- type: count
-
- dimensions:
- - name: id
- sql: campaign_id
- type: string
- primary_key: true
-
- - name: name
- sql: campaign_name
- type: string
-```
-
-```javascript title="JavaScript"
-cube(`campaigns`, {
- sql: `
- SELECT
- campaign_id,
- campaign_name,
- customer_name,
- MIN(created_at) AS started_at
- FROM emails
- GROUP BY 1, 2, 3
- `,
-
- measures: {
- count: {
- type: `count`
- }
- },
-
- dimensions: {
- id: {
- sql: `campaign_id`,
- type: `string`,
- primary_key: true
- },
-
- name: {
- sql: `campaign_name`,
- type: `string`
- }
- }
-})
-```
-
-
-
-The following diagram shows our data model with the `Campaigns` cube:
-
-
-  -
-
-The last piece is to finally declare a many-to-many relationship. This should be
-done by declaring a [`one_to_many`
-relationship][ref-schema-ref-joins-relationship] on the associative cube,
-`campaigns` in our case.
-
-
-
-```yaml title="YAML"
-cubes:
- - name: emails
- sql_table: emails
-
- joins:
- - name: campaigns
- relationship: many_to_one
- sql: |
- {CUBE}.campaign_id = {campaigns.id} AND {CUBE}.customer_name =
- {campaigns.customer_name}
-
- measures:
- - name: count
- type: count
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: campaign_name
- sql: campaign_name
- type: string
-
- - name: campaign_id
- sql: campaign_id
- type: number
-
- - name: campaigns
-
- joins:
- - name: transactions
- relationship: one_to_many
- sql: |
- {CUBE}.customer_name = {transactions.customer_name} AND
- {CUBE}.campaign_id = {transactions.campaign_id}
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: customer_name
- sql: customer_name
- type: string
-```
-
-```javascript title="JavaScript"
-cube(`emails`, {
- sql_table: `emails`,
-
- joins: {
- campaigns: {
- relationship: `many_to_one`,
- sql: `${CUBE}.campaign_id = ${campaigns.id}
- AND ${CUBE}.customer_name = ${campaigns.customer_name}`
- }
- },
-
- measures: {
- count: {
- type: `count`
- }
- },
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- campaign_name: {
- sql: `campaign_name`,
- type: `string`
- },
-
- campaign_id: {
- sql: `campaign_id`,
- type: `number`
- }
- }
-})
-
-cube(`campaigns`, {
- joins: {
- transactions: {
- relationship: `one_to_many`,
- sql: `${CUBE}.customer_name = ${transactions.customer_name}
- AND ${CUBE}.campaign_id = ${transactions.campaign_id}`
- }
- },
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- customer_name: {
- sql: `customer_name`,
- type: `string`
- }
- }
-})
-```
-
-
-
-## Join tree
-
-When Cube analyzes a [query][ref-queries], it builds a _join tree_ that connects all
-cubes involved in the query in compliance with the [direction of joins](#direction-of-joins).
-If the join tree cannot be built, the query will fail to execute. The presence of
-[bidirectional joins](#bidirectional-joins) or [diamond subgraphs](#diamond-subgraphs)
-can complicate the join tree structure.
-
-### Direction of joins
-
-**All joins in Cube's data model are _directed_.** They flow from the source cube (the one
-where the join is defined) to the target cube (the one referenced in the join).
-
-Cube will respect the join graph when generating SQL queries. It means that _source_
-cubes will be on the left side of `JOIN` clauses and _target_ cubes will be on the right
-side of `JOIN` clauses. Consider the following data model, consisting of cubes `left`
-and `right`:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: left
- sql: |
- SELECT 1 AS id, 11 AS value UNION ALL
- SELECT 2 AS id, 12 AS value UNION ALL
- SELECT 3 AS id, 13 AS value
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: value
- sql: value
- type: number
-
- joins:
- - name: right
- sql: "{left.id} = {right.id}"
- relationship: one_to_one
-
- - name: right
- sql: |
- SELECT 1 AS id, 101 AS value UNION ALL
- SELECT 2 AS id, 102 AS value UNION ALL
- SELECT 3 AS id, 103 AS value
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: value
- sql: value
- type: number
-
- # joins:
- # - name: left
- # sql: "{left.id} = {right.id}"
- # relationship: one_to_one
-```
-
-```javascript title="JavaScript"
-cube(`left`, {
- sql: `
- SELECT 1 AS id, 11 AS value UNION ALL
- SELECT 2 AS id, 12 AS value UNION ALL
- SELECT 3 AS id, 13 AS value
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- value: {
- sql: `value`,
- type: `number`
- }
- },
-
- joins: {
- right: {
- sql: `${left.id} = ${right.id}`,
- relationship: `one_to_one`
- }
- }
-})
-
-cube(`right`, {
- sql: `
- SELECT 1 AS id, 101 AS value UNION ALL
- SELECT 2 AS id, 102 AS value UNION ALL
- SELECT 3 AS id, 103 AS value
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- value: {
- sql: `value`,
- type: `number`
- }
- }
-
- // joins: {
- // left: {
- // sql: `${left.id} = ${right.id}`,
- // relationship: `one_to_one`
- // }
- // }
-})
-```
-
-
-
-It defines a join that is directed from `left` to `right`. If you query for `left.value`
-and `right.value`, Cube will generate the following SQL query. As you can see, `left` is
-on the left side of the `JOIN` clause, and `right` is on the right side:
-
-```sql
-SELECT
- "left".value "left__value",
- "right".value "right__value"
-FROM (
- SELECT 1 AS id, 11 AS value UNION ALL
- SELECT 2 AS id, 12 AS value UNION ALL
- SELECT 3 AS id, 13 AS value
-) AS "left"
-LEFT JOIN (
- SELECT 1 AS id, 101 AS value UNION ALL
- SELECT 2 AS id, 102 AS value UNION ALL
- SELECT 3 AS id, 103 AS value
-) AS "right" ON "left".id = "right".id
-GROUP BY 1, 2
-```
-
-If you comment out the join definition in the `left` cube and uncomment the join
-definition in the `right` cube, Cube will generate the following SQL for the same query:
-
-```sql
-SELECT
- "left".value "left__value",
- "right".value "right__value"
-FROM (
- SELECT 1 AS id, 101 AS value UNION ALL
- SELECT 2 AS id, 102 AS value UNION ALL
- SELECT 3 AS id, 103 AS value
-) AS "right"
-LEFT JOIN (
- SELECT 1 AS id, 11 AS value UNION ALL
- SELECT 2 AS id, 12 AS value UNION ALL
- SELECT 3 AS id, 13 AS value
-) AS "left" ON "left".id = "right".id
-GROUP BY 1, 2
-```
-
-As you can see, the direction of joins greatly influences the generated SQL and,
-conseqently, the final result set.
-
-### Bidirectional joins
-
-**As a rule of thumb, it's not recommended to define _bidirectional joins_** in the data
-model (i.e., having both cubes define a join to each other) by default. However, it can
-still be useful for some valid analytical use cases.
-
-Consider the following data model with `orders` and `customers` for an e-commerce that
-has both registered and guest customers (they have `NULL` as `customer_id`):
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- sql: |
- SELECT 1 AS id, 1001 AS customer_id, 123 AS revenue UNION ALL
- SELECT 2 AS id, 1001 AS customer_id, 234 AS revenue UNION ALL
- SELECT 3 AS id, 1002 AS customer_id, 345 AS revenue UNION ALL
- SELECT 4 AS id, NULL AS customer_id, 456 AS revenue
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: customer_id
- sql: customer_id
- type: number
-
- measures:
- - name: order_count
- type: count
-
- - name: total_revenue
- sql: revenue
- type: sum
-
- joins:
- - name: customers
- sql: "{orders.customer_id} = {customers.id}"
- relationship: many_to_one
-
- - name: customers
- sql: |
- SELECT 1001 AS id, 'Alice' AS name UNION ALL
- SELECT 1002 AS id, 'Bob' AS name UNION ALL
- SELECT 1003 AS id, 'Eve' AS name
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: name
- sql: name
- type: string
-
- measures:
- - name: customer_count
- type: count
-
- # joins:
- # - name: orders
- # sql: "{orders.customer_id} = {customers.id}"
- # relationship: one_to_many
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- sql: `
- SELECT 1 AS id, 1001 AS customer_id, 123 AS revenue UNION ALL
- SELECT 2 AS id, 1001 AS customer_id, 234 AS revenue UNION ALL
- SELECT 3 AS id, 1002 AS customer_id, 345 AS revenue UNION ALL
- SELECT 4 AS id, NULL AS customer_id, 456 AS revenue
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- customer_id: {
- sql: `customer_id`,
- type: `number`
- }
- },
-
- measures: {
- order_count: {
- type: `count`
- },
-
- total_revenue: {
- sql: `revenue`,
- type: `sum`
- }
- },
-
- joins: {
- customers: {
- sql: `${orders.customer_id} = ${customers.id}`,
- relationship: `many_to_one`
- }
- }
-})
-
-cube(`customers`, {
- sql: `
- SELECT 1001 AS id, 'Alice' AS name UNION ALL
- SELECT 1002 AS id, 'Bob' AS name UNION ALL
- SELECT 1003 AS id, 'Eve' AS name
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- name: {
- sql: `name`,
- type: `string`
- }
- },
-
- measures: {
- customer_count: {
- type: `count`
- }
- }
-
- // joins: {
- // orders: {
- // sql: `${orders.customer_id} = ${customers.id}`,
- // relationship: `one_to_many`
- // }
- // }
-})
-```
-
-
-
-Querying `customers.name` and `orders.order_count` will produce the following result:
-
-
-
-
-
-The last piece is to finally declare a many-to-many relationship. This should be
-done by declaring a [`one_to_many`
-relationship][ref-schema-ref-joins-relationship] on the associative cube,
-`campaigns` in our case.
-
-
-
-```yaml title="YAML"
-cubes:
- - name: emails
- sql_table: emails
-
- joins:
- - name: campaigns
- relationship: many_to_one
- sql: |
- {CUBE}.campaign_id = {campaigns.id} AND {CUBE}.customer_name =
- {campaigns.customer_name}
-
- measures:
- - name: count
- type: count
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: campaign_name
- sql: campaign_name
- type: string
-
- - name: campaign_id
- sql: campaign_id
- type: number
-
- - name: campaigns
-
- joins:
- - name: transactions
- relationship: one_to_many
- sql: |
- {CUBE}.customer_name = {transactions.customer_name} AND
- {CUBE}.campaign_id = {transactions.campaign_id}
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: customer_name
- sql: customer_name
- type: string
-```
-
-```javascript title="JavaScript"
-cube(`emails`, {
- sql_table: `emails`,
-
- joins: {
- campaigns: {
- relationship: `many_to_one`,
- sql: `${CUBE}.campaign_id = ${campaigns.id}
- AND ${CUBE}.customer_name = ${campaigns.customer_name}`
- }
- },
-
- measures: {
- count: {
- type: `count`
- }
- },
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- campaign_name: {
- sql: `campaign_name`,
- type: `string`
- },
-
- campaign_id: {
- sql: `campaign_id`,
- type: `number`
- }
- }
-})
-
-cube(`campaigns`, {
- joins: {
- transactions: {
- relationship: `one_to_many`,
- sql: `${CUBE}.customer_name = ${transactions.customer_name}
- AND ${CUBE}.campaign_id = ${transactions.campaign_id}`
- }
- },
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- customer_name: {
- sql: `customer_name`,
- type: `string`
- }
- }
-})
-```
-
-
-
-## Join tree
-
-When Cube analyzes a [query][ref-queries], it builds a _join tree_ that connects all
-cubes involved in the query in compliance with the [direction of joins](#direction-of-joins).
-If the join tree cannot be built, the query will fail to execute. The presence of
-[bidirectional joins](#bidirectional-joins) or [diamond subgraphs](#diamond-subgraphs)
-can complicate the join tree structure.
-
-### Direction of joins
-
-**All joins in Cube's data model are _directed_.** They flow from the source cube (the one
-where the join is defined) to the target cube (the one referenced in the join).
-
-Cube will respect the join graph when generating SQL queries. It means that _source_
-cubes will be on the left side of `JOIN` clauses and _target_ cubes will be on the right
-side of `JOIN` clauses. Consider the following data model, consisting of cubes `left`
-and `right`:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: left
- sql: |
- SELECT 1 AS id, 11 AS value UNION ALL
- SELECT 2 AS id, 12 AS value UNION ALL
- SELECT 3 AS id, 13 AS value
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: value
- sql: value
- type: number
-
- joins:
- - name: right
- sql: "{left.id} = {right.id}"
- relationship: one_to_one
-
- - name: right
- sql: |
- SELECT 1 AS id, 101 AS value UNION ALL
- SELECT 2 AS id, 102 AS value UNION ALL
- SELECT 3 AS id, 103 AS value
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: value
- sql: value
- type: number
-
- # joins:
- # - name: left
- # sql: "{left.id} = {right.id}"
- # relationship: one_to_one
-```
-
-```javascript title="JavaScript"
-cube(`left`, {
- sql: `
- SELECT 1 AS id, 11 AS value UNION ALL
- SELECT 2 AS id, 12 AS value UNION ALL
- SELECT 3 AS id, 13 AS value
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- value: {
- sql: `value`,
- type: `number`
- }
- },
-
- joins: {
- right: {
- sql: `${left.id} = ${right.id}`,
- relationship: `one_to_one`
- }
- }
-})
-
-cube(`right`, {
- sql: `
- SELECT 1 AS id, 101 AS value UNION ALL
- SELECT 2 AS id, 102 AS value UNION ALL
- SELECT 3 AS id, 103 AS value
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- value: {
- sql: `value`,
- type: `number`
- }
- }
-
- // joins: {
- // left: {
- // sql: `${left.id} = ${right.id}`,
- // relationship: `one_to_one`
- // }
- // }
-})
-```
-
-
-
-It defines a join that is directed from `left` to `right`. If you query for `left.value`
-and `right.value`, Cube will generate the following SQL query. As you can see, `left` is
-on the left side of the `JOIN` clause, and `right` is on the right side:
-
-```sql
-SELECT
- "left".value "left__value",
- "right".value "right__value"
-FROM (
- SELECT 1 AS id, 11 AS value UNION ALL
- SELECT 2 AS id, 12 AS value UNION ALL
- SELECT 3 AS id, 13 AS value
-) AS "left"
-LEFT JOIN (
- SELECT 1 AS id, 101 AS value UNION ALL
- SELECT 2 AS id, 102 AS value UNION ALL
- SELECT 3 AS id, 103 AS value
-) AS "right" ON "left".id = "right".id
-GROUP BY 1, 2
-```
-
-If you comment out the join definition in the `left` cube and uncomment the join
-definition in the `right` cube, Cube will generate the following SQL for the same query:
-
-```sql
-SELECT
- "left".value "left__value",
- "right".value "right__value"
-FROM (
- SELECT 1 AS id, 101 AS value UNION ALL
- SELECT 2 AS id, 102 AS value UNION ALL
- SELECT 3 AS id, 103 AS value
-) AS "right"
-LEFT JOIN (
- SELECT 1 AS id, 11 AS value UNION ALL
- SELECT 2 AS id, 12 AS value UNION ALL
- SELECT 3 AS id, 13 AS value
-) AS "left" ON "left".id = "right".id
-GROUP BY 1, 2
-```
-
-As you can see, the direction of joins greatly influences the generated SQL and,
-conseqently, the final result set.
-
-### Bidirectional joins
-
-**As a rule of thumb, it's not recommended to define _bidirectional joins_** in the data
-model (i.e., having both cubes define a join to each other) by default. However, it can
-still be useful for some valid analytical use cases.
-
-Consider the following data model with `orders` and `customers` for an e-commerce that
-has both registered and guest customers (they have `NULL` as `customer_id`):
-
-
-
-```yaml title="YAML"
-cubes:
- - name: orders
- sql: |
- SELECT 1 AS id, 1001 AS customer_id, 123 AS revenue UNION ALL
- SELECT 2 AS id, 1001 AS customer_id, 234 AS revenue UNION ALL
- SELECT 3 AS id, 1002 AS customer_id, 345 AS revenue UNION ALL
- SELECT 4 AS id, NULL AS customer_id, 456 AS revenue
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: customer_id
- sql: customer_id
- type: number
-
- measures:
- - name: order_count
- type: count
-
- - name: total_revenue
- sql: revenue
- type: sum
-
- joins:
- - name: customers
- sql: "{orders.customer_id} = {customers.id}"
- relationship: many_to_one
-
- - name: customers
- sql: |
- SELECT 1001 AS id, 'Alice' AS name UNION ALL
- SELECT 1002 AS id, 'Bob' AS name UNION ALL
- SELECT 1003 AS id, 'Eve' AS name
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: name
- sql: name
- type: string
-
- measures:
- - name: customer_count
- type: count
-
- # joins:
- # - name: orders
- # sql: "{orders.customer_id} = {customers.id}"
- # relationship: one_to_many
-```
-
-```javascript title="JavaScript"
-cube(`orders`, {
- sql: `
- SELECT 1 AS id, 1001 AS customer_id, 123 AS revenue UNION ALL
- SELECT 2 AS id, 1001 AS customer_id, 234 AS revenue UNION ALL
- SELECT 3 AS id, 1002 AS customer_id, 345 AS revenue UNION ALL
- SELECT 4 AS id, NULL AS customer_id, 456 AS revenue
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- customer_id: {
- sql: `customer_id`,
- type: `number`
- }
- },
-
- measures: {
- order_count: {
- type: `count`
- },
-
- total_revenue: {
- sql: `revenue`,
- type: `sum`
- }
- },
-
- joins: {
- customers: {
- sql: `${orders.customer_id} = ${customers.id}`,
- relationship: `many_to_one`
- }
- }
-})
-
-cube(`customers`, {
- sql: `
- SELECT 1001 AS id, 'Alice' AS name UNION ALL
- SELECT 1002 AS id, 'Bob' AS name UNION ALL
- SELECT 1003 AS id, 'Eve' AS name
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- name: {
- sql: `name`,
- type: `string`
- }
- },
-
- measures: {
- customer_count: {
- type: `count`
- }
- }
-
- // joins: {
- // orders: {
- // sql: `${orders.customer_id} = ${customers.id}`,
- // relationship: `one_to_many`
- // }
- // }
-})
-```
-
-
-
-Querying `customers.name` and `orders.order_count` will produce the following result:
-
-
- 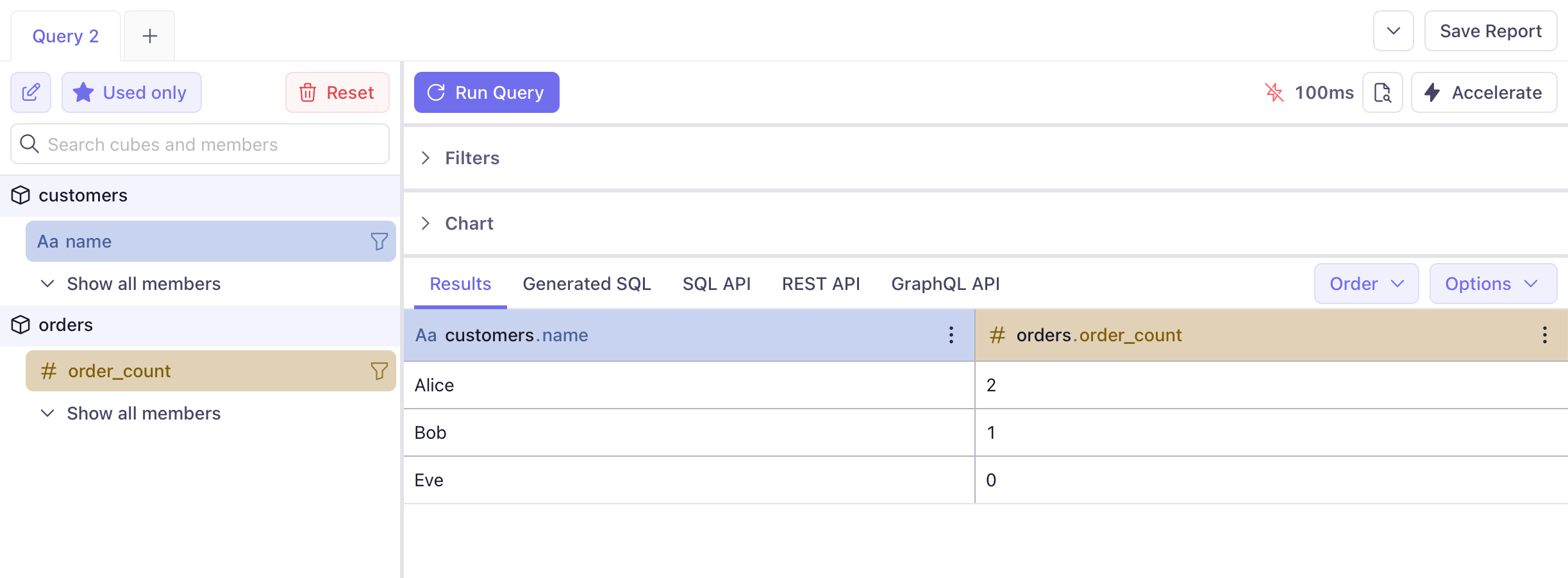 -
-
-As you can see, the result set only includes registered customers; we get no data for
-guest checkouts. Check the generated SQL query:
-
-```sql
-SELECT
- "customers".name "customers__name",
- count("orders".id) "orders__order_count"
-FROM (
- SELECT 1001 AS id, 'Alice' AS name UNION ALL
- SELECT 1002 AS id, 'Bob' AS name UNION ALL
- SELECT 1003 AS id, 'Eve' AS name
-) AS "customers"
-LEFT JOIN (
- SELECT 1 AS id, 1001 AS customer_id, 123 AS revenue UNION ALL
- SELECT 2 AS id, 1001 AS customer_id, 234 AS revenue UNION ALL
- SELECT 3 AS id, 1002 AS customer_id, 345 AS revenue UNION ALL
- SELECT 4 AS id, NULL AS customer_id, 456 AS revenue
-) AS "orders" ON "orders".customer_id = "customers".id
-GROUP BY 1
-```
-
-The `customers` cube is on the left side of the `JOIN` clause, since the direction of
-joins is from `customers` to `orders`. This means that the query will only return
-registered customers and all orders by guest customers will be excluded.
-
-Now, if you uncomment the join definition in the `orders` cube and comment out the
-join definition in the `customers` cube, running the same query will produce the following
-result:
-
-
-
-
-
-As you can see, the result set only includes registered customers; we get no data for
-guest checkouts. Check the generated SQL query:
-
-```sql
-SELECT
- "customers".name "customers__name",
- count("orders".id) "orders__order_count"
-FROM (
- SELECT 1001 AS id, 'Alice' AS name UNION ALL
- SELECT 1002 AS id, 'Bob' AS name UNION ALL
- SELECT 1003 AS id, 'Eve' AS name
-) AS "customers"
-LEFT JOIN (
- SELECT 1 AS id, 1001 AS customer_id, 123 AS revenue UNION ALL
- SELECT 2 AS id, 1001 AS customer_id, 234 AS revenue UNION ALL
- SELECT 3 AS id, 1002 AS customer_id, 345 AS revenue UNION ALL
- SELECT 4 AS id, NULL AS customer_id, 456 AS revenue
-) AS "orders" ON "orders".customer_id = "customers".id
-GROUP BY 1
-```
-
-The `customers` cube is on the left side of the `JOIN` clause, since the direction of
-joins is from `customers` to `orders`. This means that the query will only return
-registered customers and all orders by guest customers will be excluded.
-
-Now, if you uncomment the join definition in the `orders` cube and comment out the
-join definition in the `customers` cube, running the same query will produce the following
-result:
-
-
- 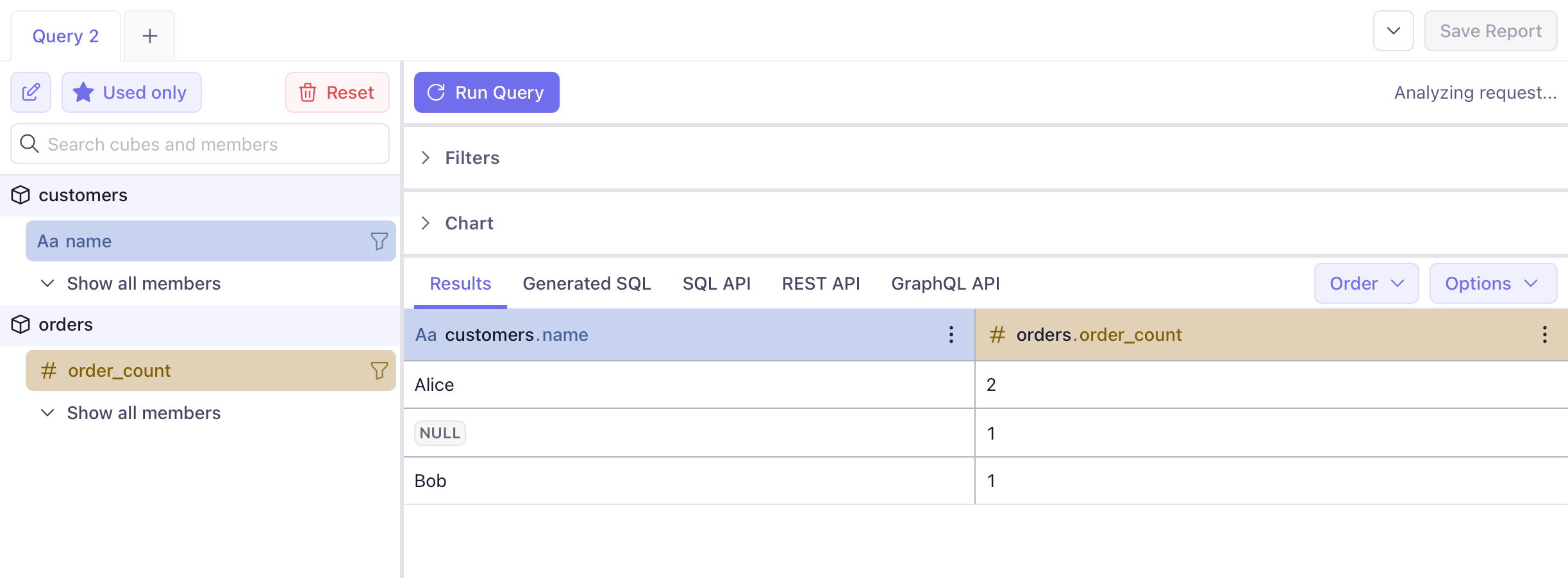 -
-
-As you can see, now the result set includes guest checkouts, but we have no data for
-registered customers who have not placed any orders (namely, `Eve`). Check the
-generated SQL query, which reveals why:
-
-```sql
-SELECT
- "customers".name "customers__name",
- count("orders".id) "orders__order_count"
-FROM (
- SELECT 1 AS id, 1001 AS customer_id, 123 AS revenue UNION ALL
- SELECT 2 AS id, 1001 AS customer_id, 234 AS revenue UNION ALL
- SELECT 3 AS id, 1002 AS customer_id, 345 AS revenue UNION ALL
- SELECT 4 AS id, NULL AS customer_id, 456 AS revenue
-) AS "orders"
-LEFT JOIN (
- SELECT 1001 AS id, 'Alice' AS name UNION ALL
- SELECT 1002 AS id, 'Bob' AS name UNION ALL
- SELECT 1003 AS id, 'Eve' AS name
-) AS "customers" ON "orders".customer_id = "customers".id
-GROUP BY 1
-```
-
-**Bidirectional joins often lead to the ambiguity in the data model** and can produce
-ambiguous results, as Cube may not know which direction to follow when generating SQL
-queries. You can remove the ambiguity by using [join paths](#join-paths) and [join
-hints](#join-hints).
-
-### Diamond subgraphs
-
-A _diamond subgraph_ is a specific type of join structure where there's more than one
-join path between two cubes, e.g., `users.schools.countries` and
-`users.employers.countries`. Join structures like `a.b.c` + `a.c` or `a.b.c.d` + `a.b.d`
-are also be considered diamond subgraphs for the purpose of this section.
-
-In the following example, four cubes are joined together as a _diamond_: `a` joins to `b`
-and `c`, and both `b` and `c` join to `d`:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: a
- sql: |
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: d_via_b
- sql: "{b.d.id}"
- type: number
-
- - name: d_via_c
- sql: "{c.d.id}"
- type: number
-
- joins:
- - name: b
- sql: "{a.id} = {b.id}"
- relationship: one_to_one
-
- - name: c
- sql: "{a.id} = {c.id}"
- relationship: one_to_one
-
- - name: b
- sql: |
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- joins:
- - name: d
- sql: "{b.id} = {d.id}"
- relationship: one_to_one
-
- - name: c
- sql: |
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- joins:
- - name: d
- sql: "{c.id} = {d.id}"
- relationship: one_to_one
-
- - name: d
- sql: |
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-```
-
-```javascript title="JavaScript"
-cube(`a`, {
- sql: `
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- d_via_b: {
- sql: `${b.d.id}`,
- type: `number`
- },
-
- d_via_c: {
- sql: `${c.d.id}`,
- type: `number`
- }
- },
-
- joins: {
- b: {
- sql: `${a.id} = ${b.id}`,
- relationship: `one_to_one`
- },
-
- c: {
- sql: `${a.id} = ${c.id}`,
- relationship: `one_to_one`
- }
- }
-})
-
-cube(`b`, {
- sql: `
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- }
- },
-
- joins: {
- d: {
- sql: `${b.id} = ${d.id}`,
- relationship: `one_to_one`
- }
- }
-})
-
-cube(`c`, {
- sql: `
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- }
- },
-
- joins: {
- d: {
- sql: `${c.id} = ${d.id}`,
- relationship: `one_to_one`
- }
- }
-})
-
-cube(`d`, {
- sql: `
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- }
- }
-})
-```
-
-
-
-When querying `a.d_via_b`, Cube will generate the following SQL query, joining through
-`b`:
-
-```sql
-SELECT
- "d".id "a__d_via_b"
-FROM (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "a"
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "b" ON "a".id = "b".id
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "d" ON "b".id = "d".id
-GROUP BY 1
-```
-
-However, when querying `a.d_via_c`, Cube will generate the following SQL query, joining
-through `c`:
-
-```sql
-SELECT
- "d".id "a__d_via_c"
-FROM (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "a"
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "c" ON "a".id = "c".id
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "d" ON "c".id = "d".id
-GROUP BY 1
-```
-
-
-
-Note that having both `a.d_via_b` and `a.d_via_c` in the same query will produce
-ambiguous results, as Cube will only use `d` to the generated SQL once:
-
-```sql
-SELECT
- "d".id "a__d_via_b",
- "d".id "a__d_via_c"
-FROM (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "a"
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "b" ON "a".id = "b".id
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "d" ON "b".id = "d".id
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "c" ON "a".id = "c".id
-GROUP BY 1, 2
-```
-
-
-
-Similar to bidirectional joins, **diamond subgraphs often lead to the ambiguity in the
-data model** and can produce ambiguous results, as Cube may not know which direction to
-follow when generating SQL queries. You can remove the ambiguity by using [join
-paths](#join-paths) and [join hints](#join-hints).
-
-## Join paths
-
-_Join paths_ serve as the recommended mechanism to remove the ambiguity of joins in the
-data model, including cases of [bidirectional joins](#bidirectional-joins) and [diamond
-subgraphs](#diamond-subgraphs).
-
-A join path is defined as a sequence of cube names, separated by dots, that will be
-followed in that specific order when resolving a cube or its member, e.g.,
-`users.locations.countries.flag_aspect_ratio`.
-
-### Calculated members
-
-When referencing a member of another cube in a [calculated member][ref-calculated-members],
-you can use a join path to specify the path to follow, as demonstrated in the [diamond
-subgraphs example](#diamond-subgraphs).
-
-### Views
-
-When referencing cubes in a [view][ref-views], you literally provide join paths via the
-[`join_path` parameter][ref-view-join-path]. The [bidirectional joins
-example](#bidirectional-joins) can be disambiguated with the following views:
-
-
-
-```yaml title="YAML"
-views:
- - name: total_revenue_per_customer
- cubes:
- - join_path: orders
- includes:
- - total_revenue
-
- - join_path: orders.customers
- includes:
- - name
-
- - name: customers_without_orders
- cubes:
- - join_path: customers
- includes:
- - name
-
- - join_path: customers.orders
- includes:
- - order_count
-```
-
-```javascript title="JavaScript"
-view(`total_revenue_per_customer`, {
- cubes: [
- {
- join_path: orders,
- includes: ['total_revenue']
- },
- {
- join_path: orders.customers,
- includes: ['name']
- }
- ]
-})
-
-view(`customers_without_orders`, {
- cubes: [
- {
- join_path: customers,
- includes: ['name']
- },
- {
- join_path: customers.orders,
- includes: ['order_count']
- }
- ]
-})
-```
-
-
-
-### Pre-aggregations
-
-When referencing members of another cubes in a [pre-aggregation][ref-preaggs], you can
-also use join paths, as shown in the following example:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: a
- sql: |
- SELECT 1 AS id, 1 AS b_id, 1 AS c_id UNION ALL
- SELECT 2 AS id, 2 AS b_id, 2 AS c_id
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: dimension1
- sql: "CONCAT({CUBE}.b_id, {CUBE}.b_id)"
- type: string
-
- measures:
- - name: measure1
- type: count
-
- joins:
- - name: b
- relationship: one_to_one
- sql: "{CUBE}.b_id = {b.id}"
-
- - name: c
- relationship: one_to_one
- sql: "{CUBE}.c_id = {c.id}"
-
- pre_aggregations:
- - name: a_and_c
- dimensions:
- - a.dimension1
- - a.b.c.dimension2
- measures:
- - a.measure1
- - a.b.c.measure2
-
- - name: b
- sql: |
- SELECT 1 AS id, 1 AS c_id UNION ALL
- SELECT 2 AS id, 2 AS c_id
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- joins:
- - name: c
- relationship: one_to_one
- sql: "{CUBE}.c_id = {c.id}"
-
- - name: c
- sql: |
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: dimension2
- sql: "{CUBE}.id * 3"
- type: string
-
- measures:
- - name: measure2
- sql: "{CUBE.dimension2}"
- type: sum
-```
-
-```javascript title="JavaScript"
-cube(`a`, {
- sql: `
- SELECT 1 AS id, 1 AS b_id, 1 AS c_id UNION ALL
- SELECT 2 AS id, 2 AS b_id, 2 AS c_id
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- dimension1: {
- sql: `CONCAT(${CUBE}.b_id, ${CUBE}.b_id)`,
- type: `string`
- }
- },
-
- measures: {
- measure1: {
- type: `count`
- }
- },
-
- joins: {
- b: {
- relationship: `one_to_one`,
- sql: `${CUBE}.b_id = ${b.id}`
- },
-
- c: {
- relationship: `one_to_one`,
- sql: `${CUBE}.c_id = ${c.id}`
- }
- },
-
- pre_aggregations: {
- a_and_c: {
- dimensions: [
- `a.dimension1`,
- `a.b.c.dimension2`
- ],
- measures: [
- `a.measure1`,
- `a.b.c.measure2`
- ]
- }
- }
-})
-
-cube(`b`, {
- sql: `
- SELECT 1 AS id, 1 AS c_id UNION ALL
- SELECT 2 AS id, 2 AS c_id
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- }
- },
-
- joins: {
- c: {
- relationship: `one_to_one`,
- sql: `${CUBE}.c_id = ${c.id}`
- }
- }
-})
-
-cube(`c`, {
- sql: `
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- dimension2: {
- sql: `${CUBE}.id * 3`,
- type: `string`
- }
- },
-
- measures: {
- measure2: {
- sql: `${CUBE.dimension2}`,
- type: `sum`
- }
- }
-})
-```
-
-
-
-When this pre-aggregation is built, Cube will generate and execute the following SQL
-query:
-
-```sql
-CREATE TABLE prod_pre_aggregations.a_a_and_c AS
-SELECT
- "c".id * 3 "c__dimension2",
- CONCAT("a".b_id, "a".b_id) "a__dimension1",
- sum("c".id * 3) "c__measure2",
- count("a".id) "a__measure1"
-FROM (
- SELECT 1 AS id, 1 AS b_id, 1 AS c_id UNION ALL
- SELECT 2 AS id, 2 AS b_id, 2 AS c_id
-) AS "a"
-LEFT JOIN (
- SELECT 1 AS id, 1 AS c_id UNION ALL
- SELECT 2 AS id, 2 AS c_id
-) AS "b" ON "a".b_id = "b".id
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id
-) AS "c" ON "b".c_id = "c".id
-GROUP BY 1, 2
-```
-
-As you can see, in this query, `a` is joined to `c` though `b` here, even though a
-direct join from `a` to `c` is also defined in the data model. However, Cube respects
-join paths from the pre-aggregation definition and uses them to generate the SQL query.
-
-## Join hints
-
-_Join hints_ serve as an auxiliary mechanism to remove the ambiguity of joins _at the
-query time_. When possible, use [join paths](#join-paths) in the data model instead.
-
-### SQL API
-
-In queries to the [SQL API][ref-sql-api], cubes can be [joined][ref-sql-api-joins] via
-the `CROSS JOIN` clause or via `__cubeJoinField`. In any case, Cube will analyze the
-query and follow provided join hints.
-
-Let's run the following query with the data model from the [diamond subgraphs
-example](#diamond-subgraphs):
-
-```sql
-SELECT
- a.id AS id,
- d.id AS d_via_b
-FROM a
-CROSS JOIN b
-CROSS JOIN d
-GROUP BY 1, 2
-```
-
-The following SQL query will be generated:
-
-```sql
-SELECT
- "a".id "a__id",
- "d".id "d__id"
-FROM (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "a"
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "b" ON "a".id = "b".id
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "d" ON "b".id = "d".id
-GROUP BY 1, 2
-```
-
-If the SQL API query contained `CROSS JOIN c` instead of `CROSS JOIN b`, then the
-generated SQL query would contain a join through `c` instead of `b`.
-
-### REST API
-
-In queries to the [REST API][ref-rest-api], join hints can be provided via the
-[`joinHints` parameter][ref-rest-api-join-hints].
-
-The SQL API query from the previous section can be rewritten as a REST API query
-with join hints as follows:
-
-```json
-{
- "dimensions": [
- "a.id",
- "d.id"
- ],
- "joinHints": [
- ["a", "b"],
- ["b", "d"]
- ]
-}
-```
-
-The same SQL query as in the previous section will be generated.
-
-Similarly, if the `joinHints` parameter contained `[["a", "c"], ["c", "d"]]` instead of
-`[["a", "b"], ["b", "d"]]`, then the generated SQL query would contain a join through
-`c` instead of `b`.
-
-## Troubleshooting
-
-### `Can't find join path`
-
-Sometimes, you might come across the following error message: `Can't find join path to
-join 'cube_a', 'cube_b'`.
-
-It indicates that a query failed because it includes members from cubes that can't be
-joined in order to generate a valid query to the upstream data source.
-Please check that you've defined necessary joins and that they have [correct
-directions](#transitive-join-pitfalls).
-
-Also, please consider using [views][ref-schema-ref-view] since they
-incapsulate join paths and completely remove the possibility of the error in question.
-You might also consider setting the [`public` parameter][ref-cube-public] to `false`
-on your cubes to hide them from end users.
-
-If you’re building a custom data application, you might use the [`meta` endpoint][ref-rest-meta]
-of the REST API. It groups cubes into `connectedComponents` to help select those ones
-that can be joined together.
-
-### `Primary key is required when join is defined`
-
-Sometimes, you might come across the following error message: `cube_a cube: primary key
-for 'cube_a' is required when join is defined in order to make aggregates work properly`.
-
-It indicates that you have a [cube][ref-cube] with joins and [pre-aggregations][ref-preaggs].
-However, that cube doesn't have a primary key.
-
-When generating SQL queries, Cube uses primary keys to avoid fanouts. A fanout happens
-when two tables are joined and a single value gets duplicated in the end result, meaning
-that some values can be double counted.
-
-Please define a [primary key][ref-primary-key] dimension in this cube to make joins and
-pre-aggregations work correctly.
-
-If your data doesn't have a natural primary key, e.g., `id`, you can define a composite
-primary key by concatenating most or all of the columns in the table. Example:
-
-```yml
-cubes:
- - name: cube_a
- # ...
-
- dimensions:
- - name: composite_key
- sql: CONCAT(column_a, '-', column_b, '-', column_c)
- type: string
- primary_key: true
-```
-
-### Transitive join pitfalls
-
-Let's consider an example where we have a many-to-many relationship between
-`users` and `companies` through the `companies_to_users` cube:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: users
- sql: |
- SELECT 1 AS id, 'Ali' AS name UNION ALL
- SELECT 2 AS id, 'Bob' AS name UNION ALL
- SELECT 3 AS id, 'Eve' AS name
-
- measures:
- - name: count
- type: count
-
- dimensions:
- - name: id
- sql: id
- type: string
- primary_key: true
-
- - name: companies
- sql: |
- SELECT 11 AS id, 'Acme Corporation' AS name UNION ALL
- SELECT 12 AS id, 'Stark Industries' AS name
-
- dimensions:
- - name: id
- sql: id
- type: string
- primary_key: true
-
- - name: name
- sql: name
- type: string
-
- - name: companies_to_users
- sql: |
- SELECT 11 AS company_id, 1 AS user_id UNION ALL
- SELECT 11 AS company_id, 2 AS user_id UNION ALL
- SELECT 12 AS company_id, 3 AS user_id
-
- joins:
- - name: users
- sql: "{CUBE}.user_id = {users.id}"
- relationship: one_to_many
-
- - name: companies
- sql: "{CUBE}.company_id = {companies.id}"
- relationship: one_to_many
-
- dimensions:
- - name: id
- # Joins require a primary key, so we'll create one on-the-fly
- sql: "CONCAT({CUBE}.user_id, ':', {CUBE}.company_id)"
- type: string
- primary_key: true
-```
-
-```javascript title="JavaScript"
-cube(`users`, {
- sql: `
- SELECT 1 AS id, 'Ali' AS name UNION ALL
- SELECT 2 AS id, 'Bob' AS name UNION ALL
- SELECT 3 AS id, 'Eve' AS name
- `,
-
- measures: {
- count: {
- type: `count`
- }
- },
-
- dimensions: {
- id: {
- sql: `id`,
- type: `string`,
- primary_key: true
- }
- }
-})
-
-cube(`companies`, {
- sql: `
- SELECT 11 AS id, 'Acme Corporation' AS name UNION ALL
- SELECT 12 AS id, 'Stark Industries' AS name
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `string`,
- primary_key: true
- },
-
- name: {
- sql: `name`,
- type: `string`
- }
- }
-})
-
-cube(`companies_to_users`, {
- sql: `
- SELECT 11 AS company_id, 1 AS user_id UNION ALL
- SELECT 11 AS company_id, 2 AS user_id UNION ALL
- SELECT 12 AS company_id, 3 AS user_id
- `,
-
- joins: {
- users: {
- sql: `${CUBE}.user_id = ${users.id}`,
- relationship: `one_to_many`
- },
-
- companies: {
- sql: `${CUBE}.company_id = ${companies.id}`,
- relationship: `one_to_many`
- }
- },
-
- dimensions: {
- id: {
- // Joins require a primary key, so we'll create one on-the-fly
- sql: `CONCAT(${CUBE}.user_id, ':', ${CUBE}.company_id)`,
- type: `string`,
- primary_key: true
- }
- }
-})
-```
-
-
-
-With this data model, querying `users.count` as a measure and `companies.name`
-as a dimension would yield the following error: `Can't find join path to join
-'users', 'companies'`.
-
-The root cause is that joins are [directed](#direction-of-joins) and there's no
-join path that goes *by join definitions in the data model* from `users` to
-`companies` or in the opposite direction.
-
-In [Visual Modeler][ref-visual-model], you can see that both `users` and `companies`
-are to the right of `companies_to_users`, meaning that there's no way to go
-from `users` to `companies` moving left to right or right to left:
-
-
-
-
-
-As you can see, now the result set includes guest checkouts, but we have no data for
-registered customers who have not placed any orders (namely, `Eve`). Check the
-generated SQL query, which reveals why:
-
-```sql
-SELECT
- "customers".name "customers__name",
- count("orders".id) "orders__order_count"
-FROM (
- SELECT 1 AS id, 1001 AS customer_id, 123 AS revenue UNION ALL
- SELECT 2 AS id, 1001 AS customer_id, 234 AS revenue UNION ALL
- SELECT 3 AS id, 1002 AS customer_id, 345 AS revenue UNION ALL
- SELECT 4 AS id, NULL AS customer_id, 456 AS revenue
-) AS "orders"
-LEFT JOIN (
- SELECT 1001 AS id, 'Alice' AS name UNION ALL
- SELECT 1002 AS id, 'Bob' AS name UNION ALL
- SELECT 1003 AS id, 'Eve' AS name
-) AS "customers" ON "orders".customer_id = "customers".id
-GROUP BY 1
-```
-
-**Bidirectional joins often lead to the ambiguity in the data model** and can produce
-ambiguous results, as Cube may not know which direction to follow when generating SQL
-queries. You can remove the ambiguity by using [join paths](#join-paths) and [join
-hints](#join-hints).
-
-### Diamond subgraphs
-
-A _diamond subgraph_ is a specific type of join structure where there's more than one
-join path between two cubes, e.g., `users.schools.countries` and
-`users.employers.countries`. Join structures like `a.b.c` + `a.c` or `a.b.c.d` + `a.b.d`
-are also be considered diamond subgraphs for the purpose of this section.
-
-In the following example, four cubes are joined together as a _diamond_: `a` joins to `b`
-and `c`, and both `b` and `c` join to `d`:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: a
- sql: |
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: d_via_b
- sql: "{b.d.id}"
- type: number
-
- - name: d_via_c
- sql: "{c.d.id}"
- type: number
-
- joins:
- - name: b
- sql: "{a.id} = {b.id}"
- relationship: one_to_one
-
- - name: c
- sql: "{a.id} = {c.id}"
- relationship: one_to_one
-
- - name: b
- sql: |
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- joins:
- - name: d
- sql: "{b.id} = {d.id}"
- relationship: one_to_one
-
- - name: c
- sql: |
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- joins:
- - name: d
- sql: "{c.id} = {d.id}"
- relationship: one_to_one
-
- - name: d
- sql: |
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-```
-
-```javascript title="JavaScript"
-cube(`a`, {
- sql: `
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- d_via_b: {
- sql: `${b.d.id}`,
- type: `number`
- },
-
- d_via_c: {
- sql: `${c.d.id}`,
- type: `number`
- }
- },
-
- joins: {
- b: {
- sql: `${a.id} = ${b.id}`,
- relationship: `one_to_one`
- },
-
- c: {
- sql: `${a.id} = ${c.id}`,
- relationship: `one_to_one`
- }
- }
-})
-
-cube(`b`, {
- sql: `
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- }
- },
-
- joins: {
- d: {
- sql: `${b.id} = ${d.id}`,
- relationship: `one_to_one`
- }
- }
-})
-
-cube(`c`, {
- sql: `
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- }
- },
-
- joins: {
- d: {
- sql: `${c.id} = ${d.id}`,
- relationship: `one_to_one`
- }
- }
-})
-
-cube(`d`, {
- sql: `
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- }
- }
-})
-```
-
-
-
-When querying `a.d_via_b`, Cube will generate the following SQL query, joining through
-`b`:
-
-```sql
-SELECT
- "d".id "a__d_via_b"
-FROM (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "a"
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "b" ON "a".id = "b".id
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "d" ON "b".id = "d".id
-GROUP BY 1
-```
-
-However, when querying `a.d_via_c`, Cube will generate the following SQL query, joining
-through `c`:
-
-```sql
-SELECT
- "d".id "a__d_via_c"
-FROM (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "a"
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "c" ON "a".id = "c".id
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "d" ON "c".id = "d".id
-GROUP BY 1
-```
-
-
-
-Note that having both `a.d_via_b` and `a.d_via_c` in the same query will produce
-ambiguous results, as Cube will only use `d` to the generated SQL once:
-
-```sql
-SELECT
- "d".id "a__d_via_b",
- "d".id "a__d_via_c"
-FROM (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "a"
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "b" ON "a".id = "b".id
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "d" ON "b".id = "d".id
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "c" ON "a".id = "c".id
-GROUP BY 1, 2
-```
-
-
-
-Similar to bidirectional joins, **diamond subgraphs often lead to the ambiguity in the
-data model** and can produce ambiguous results, as Cube may not know which direction to
-follow when generating SQL queries. You can remove the ambiguity by using [join
-paths](#join-paths) and [join hints](#join-hints).
-
-## Join paths
-
-_Join paths_ serve as the recommended mechanism to remove the ambiguity of joins in the
-data model, including cases of [bidirectional joins](#bidirectional-joins) and [diamond
-subgraphs](#diamond-subgraphs).
-
-A join path is defined as a sequence of cube names, separated by dots, that will be
-followed in that specific order when resolving a cube or its member, e.g.,
-`users.locations.countries.flag_aspect_ratio`.
-
-### Calculated members
-
-When referencing a member of another cube in a [calculated member][ref-calculated-members],
-you can use a join path to specify the path to follow, as demonstrated in the [diamond
-subgraphs example](#diamond-subgraphs).
-
-### Views
-
-When referencing cubes in a [view][ref-views], you literally provide join paths via the
-[`join_path` parameter][ref-view-join-path]. The [bidirectional joins
-example](#bidirectional-joins) can be disambiguated with the following views:
-
-
-
-```yaml title="YAML"
-views:
- - name: total_revenue_per_customer
- cubes:
- - join_path: orders
- includes:
- - total_revenue
-
- - join_path: orders.customers
- includes:
- - name
-
- - name: customers_without_orders
- cubes:
- - join_path: customers
- includes:
- - name
-
- - join_path: customers.orders
- includes:
- - order_count
-```
-
-```javascript title="JavaScript"
-view(`total_revenue_per_customer`, {
- cubes: [
- {
- join_path: orders,
- includes: ['total_revenue']
- },
- {
- join_path: orders.customers,
- includes: ['name']
- }
- ]
-})
-
-view(`customers_without_orders`, {
- cubes: [
- {
- join_path: customers,
- includes: ['name']
- },
- {
- join_path: customers.orders,
- includes: ['order_count']
- }
- ]
-})
-```
-
-
-
-### Pre-aggregations
-
-When referencing members of another cubes in a [pre-aggregation][ref-preaggs], you can
-also use join paths, as shown in the following example:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: a
- sql: |
- SELECT 1 AS id, 1 AS b_id, 1 AS c_id UNION ALL
- SELECT 2 AS id, 2 AS b_id, 2 AS c_id
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: dimension1
- sql: "CONCAT({CUBE}.b_id, {CUBE}.b_id)"
- type: string
-
- measures:
- - name: measure1
- type: count
-
- joins:
- - name: b
- relationship: one_to_one
- sql: "{CUBE}.b_id = {b.id}"
-
- - name: c
- relationship: one_to_one
- sql: "{CUBE}.c_id = {c.id}"
-
- pre_aggregations:
- - name: a_and_c
- dimensions:
- - a.dimension1
- - a.b.c.dimension2
- measures:
- - a.measure1
- - a.b.c.measure2
-
- - name: b
- sql: |
- SELECT 1 AS id, 1 AS c_id UNION ALL
- SELECT 2 AS id, 2 AS c_id
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- joins:
- - name: c
- relationship: one_to_one
- sql: "{CUBE}.c_id = {c.id}"
-
- - name: c
- sql: |
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id
-
- dimensions:
- - name: id
- sql: id
- type: number
- primary_key: true
-
- - name: dimension2
- sql: "{CUBE}.id * 3"
- type: string
-
- measures:
- - name: measure2
- sql: "{CUBE.dimension2}"
- type: sum
-```
-
-```javascript title="JavaScript"
-cube(`a`, {
- sql: `
- SELECT 1 AS id, 1 AS b_id, 1 AS c_id UNION ALL
- SELECT 2 AS id, 2 AS b_id, 2 AS c_id
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- dimension1: {
- sql: `CONCAT(${CUBE}.b_id, ${CUBE}.b_id)`,
- type: `string`
- }
- },
-
- measures: {
- measure1: {
- type: `count`
- }
- },
-
- joins: {
- b: {
- relationship: `one_to_one`,
- sql: `${CUBE}.b_id = ${b.id}`
- },
-
- c: {
- relationship: `one_to_one`,
- sql: `${CUBE}.c_id = ${c.id}`
- }
- },
-
- pre_aggregations: {
- a_and_c: {
- dimensions: [
- `a.dimension1`,
- `a.b.c.dimension2`
- ],
- measures: [
- `a.measure1`,
- `a.b.c.measure2`
- ]
- }
- }
-})
-
-cube(`b`, {
- sql: `
- SELECT 1 AS id, 1 AS c_id UNION ALL
- SELECT 2 AS id, 2 AS c_id
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- }
- },
-
- joins: {
- c: {
- relationship: `one_to_one`,
- sql: `${CUBE}.c_id = ${c.id}`
- }
- }
-})
-
-cube(`c`, {
- sql: `
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `number`,
- primary_key: true
- },
-
- dimension2: {
- sql: `${CUBE}.id * 3`,
- type: `string`
- }
- },
-
- measures: {
- measure2: {
- sql: `${CUBE.dimension2}`,
- type: `sum`
- }
- }
-})
-```
-
-
-
-When this pre-aggregation is built, Cube will generate and execute the following SQL
-query:
-
-```sql
-CREATE TABLE prod_pre_aggregations.a_a_and_c AS
-SELECT
- "c".id * 3 "c__dimension2",
- CONCAT("a".b_id, "a".b_id) "a__dimension1",
- sum("c".id * 3) "c__measure2",
- count("a".id) "a__measure1"
-FROM (
- SELECT 1 AS id, 1 AS b_id, 1 AS c_id UNION ALL
- SELECT 2 AS id, 2 AS b_id, 2 AS c_id
-) AS "a"
-LEFT JOIN (
- SELECT 1 AS id, 1 AS c_id UNION ALL
- SELECT 2 AS id, 2 AS c_id
-) AS "b" ON "a".b_id = "b".id
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id
-) AS "c" ON "b".c_id = "c".id
-GROUP BY 1, 2
-```
-
-As you can see, in this query, `a` is joined to `c` though `b` here, even though a
-direct join from `a` to `c` is also defined in the data model. However, Cube respects
-join paths from the pre-aggregation definition and uses them to generate the SQL query.
-
-## Join hints
-
-_Join hints_ serve as an auxiliary mechanism to remove the ambiguity of joins _at the
-query time_. When possible, use [join paths](#join-paths) in the data model instead.
-
-### SQL API
-
-In queries to the [SQL API][ref-sql-api], cubes can be [joined][ref-sql-api-joins] via
-the `CROSS JOIN` clause or via `__cubeJoinField`. In any case, Cube will analyze the
-query and follow provided join hints.
-
-Let's run the following query with the data model from the [diamond subgraphs
-example](#diamond-subgraphs):
-
-```sql
-SELECT
- a.id AS id,
- d.id AS d_via_b
-FROM a
-CROSS JOIN b
-CROSS JOIN d
-GROUP BY 1, 2
-```
-
-The following SQL query will be generated:
-
-```sql
-SELECT
- "a".id "a__id",
- "d".id "d__id"
-FROM (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "a"
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "b" ON "a".id = "b".id
-LEFT JOIN (
- SELECT 1 AS id UNION ALL
- SELECT 2 AS id UNION ALL
- SELECT 3 AS id
-) AS "d" ON "b".id = "d".id
-GROUP BY 1, 2
-```
-
-If the SQL API query contained `CROSS JOIN c` instead of `CROSS JOIN b`, then the
-generated SQL query would contain a join through `c` instead of `b`.
-
-### REST API
-
-In queries to the [REST API][ref-rest-api], join hints can be provided via the
-[`joinHints` parameter][ref-rest-api-join-hints].
-
-The SQL API query from the previous section can be rewritten as a REST API query
-with join hints as follows:
-
-```json
-{
- "dimensions": [
- "a.id",
- "d.id"
- ],
- "joinHints": [
- ["a", "b"],
- ["b", "d"]
- ]
-}
-```
-
-The same SQL query as in the previous section will be generated.
-
-Similarly, if the `joinHints` parameter contained `[["a", "c"], ["c", "d"]]` instead of
-`[["a", "b"], ["b", "d"]]`, then the generated SQL query would contain a join through
-`c` instead of `b`.
-
-## Troubleshooting
-
-### `Can't find join path`
-
-Sometimes, you might come across the following error message: `Can't find join path to
-join 'cube_a', 'cube_b'`.
-
-It indicates that a query failed because it includes members from cubes that can't be
-joined in order to generate a valid query to the upstream data source.
-Please check that you've defined necessary joins and that they have [correct
-directions](#transitive-join-pitfalls).
-
-Also, please consider using [views][ref-schema-ref-view] since they
-incapsulate join paths and completely remove the possibility of the error in question.
-You might also consider setting the [`public` parameter][ref-cube-public] to `false`
-on your cubes to hide them from end users.
-
-If you’re building a custom data application, you might use the [`meta` endpoint][ref-rest-meta]
-of the REST API. It groups cubes into `connectedComponents` to help select those ones
-that can be joined together.
-
-### `Primary key is required when join is defined`
-
-Sometimes, you might come across the following error message: `cube_a cube: primary key
-for 'cube_a' is required when join is defined in order to make aggregates work properly`.
-
-It indicates that you have a [cube][ref-cube] with joins and [pre-aggregations][ref-preaggs].
-However, that cube doesn't have a primary key.
-
-When generating SQL queries, Cube uses primary keys to avoid fanouts. A fanout happens
-when two tables are joined and a single value gets duplicated in the end result, meaning
-that some values can be double counted.
-
-Please define a [primary key][ref-primary-key] dimension in this cube to make joins and
-pre-aggregations work correctly.
-
-If your data doesn't have a natural primary key, e.g., `id`, you can define a composite
-primary key by concatenating most or all of the columns in the table. Example:
-
-```yml
-cubes:
- - name: cube_a
- # ...
-
- dimensions:
- - name: composite_key
- sql: CONCAT(column_a, '-', column_b, '-', column_c)
- type: string
- primary_key: true
-```
-
-### Transitive join pitfalls
-
-Let's consider an example where we have a many-to-many relationship between
-`users` and `companies` through the `companies_to_users` cube:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: users
- sql: |
- SELECT 1 AS id, 'Ali' AS name UNION ALL
- SELECT 2 AS id, 'Bob' AS name UNION ALL
- SELECT 3 AS id, 'Eve' AS name
-
- measures:
- - name: count
- type: count
-
- dimensions:
- - name: id
- sql: id
- type: string
- primary_key: true
-
- - name: companies
- sql: |
- SELECT 11 AS id, 'Acme Corporation' AS name UNION ALL
- SELECT 12 AS id, 'Stark Industries' AS name
-
- dimensions:
- - name: id
- sql: id
- type: string
- primary_key: true
-
- - name: name
- sql: name
- type: string
-
- - name: companies_to_users
- sql: |
- SELECT 11 AS company_id, 1 AS user_id UNION ALL
- SELECT 11 AS company_id, 2 AS user_id UNION ALL
- SELECT 12 AS company_id, 3 AS user_id
-
- joins:
- - name: users
- sql: "{CUBE}.user_id = {users.id}"
- relationship: one_to_many
-
- - name: companies
- sql: "{CUBE}.company_id = {companies.id}"
- relationship: one_to_many
-
- dimensions:
- - name: id
- # Joins require a primary key, so we'll create one on-the-fly
- sql: "CONCAT({CUBE}.user_id, ':', {CUBE}.company_id)"
- type: string
- primary_key: true
-```
-
-```javascript title="JavaScript"
-cube(`users`, {
- sql: `
- SELECT 1 AS id, 'Ali' AS name UNION ALL
- SELECT 2 AS id, 'Bob' AS name UNION ALL
- SELECT 3 AS id, 'Eve' AS name
- `,
-
- measures: {
- count: {
- type: `count`
- }
- },
-
- dimensions: {
- id: {
- sql: `id`,
- type: `string`,
- primary_key: true
- }
- }
-})
-
-cube(`companies`, {
- sql: `
- SELECT 11 AS id, 'Acme Corporation' AS name UNION ALL
- SELECT 12 AS id, 'Stark Industries' AS name
- `,
-
- dimensions: {
- id: {
- sql: `id`,
- type: `string`,
- primary_key: true
- },
-
- name: {
- sql: `name`,
- type: `string`
- }
- }
-})
-
-cube(`companies_to_users`, {
- sql: `
- SELECT 11 AS company_id, 1 AS user_id UNION ALL
- SELECT 11 AS company_id, 2 AS user_id UNION ALL
- SELECT 12 AS company_id, 3 AS user_id
- `,
-
- joins: {
- users: {
- sql: `${CUBE}.user_id = ${users.id}`,
- relationship: `one_to_many`
- },
-
- companies: {
- sql: `${CUBE}.company_id = ${companies.id}`,
- relationship: `one_to_many`
- }
- },
-
- dimensions: {
- id: {
- // Joins require a primary key, so we'll create one on-the-fly
- sql: `CONCAT(${CUBE}.user_id, ':', ${CUBE}.company_id)`,
- type: `string`,
- primary_key: true
- }
- }
-})
-```
-
-
-
-With this data model, querying `users.count` as a measure and `companies.name`
-as a dimension would yield the following error: `Can't find join path to join
-'users', 'companies'`.
-
-The root cause is that joins are [directed](#direction-of-joins) and there's no
-join path that goes *by join definitions in the data model* from `users` to
-`companies` or in the opposite direction.
-
-In [Visual Modeler][ref-visual-model], you can see that both `users` and `companies`
-are to the right of `companies_to_users`, meaning that there's no way to go
-from `users` to `companies` moving left to right or right to left:
-
-
- 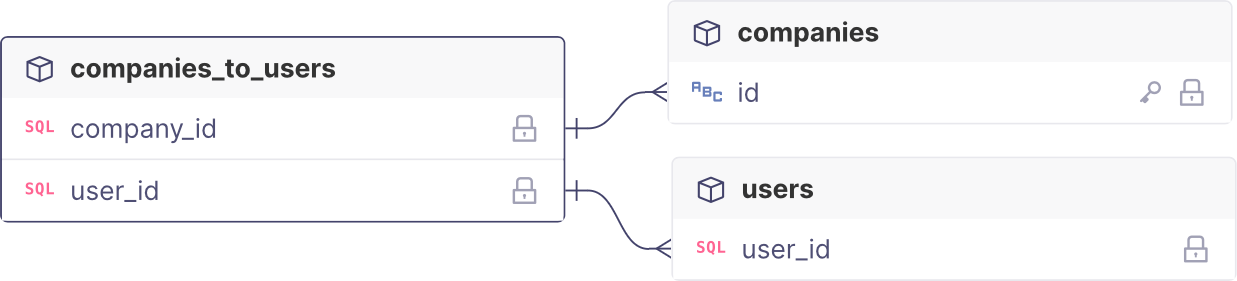 -
-
-One possible solution is to move one of two joins from the `companies_to_users`
-cube to either `users` or `companies` cube. Please note that it would affect
-the query semantics and thus the final result:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: users
-
- joins:
- - name: companies_to_users
- sql: "{CUBE}.id = {companies_to_users}.user_id"
- relationship: one_to_many
-
- # ...
-
- - name: companies_to_users
-
- joins:
- # - name: users
- # sql: "{CUBE}.user_id = {users.id}"
- # relationship: one_to_many
-
- - name: companies
- sql: "{CUBE}.company_id = {companies.id}"
- relationship: one_to_many
-
- # ...
-```
-
-```javascript title="JavaScript"
-cube(`users`, {
- joins: {
- companies_to_users: {
- sql: `${CUBE}.id = ${companies_to_users}.user_id`,
- relationship: `one_to_many`
- }
- }
-
- // ...
-})
-
-cube(`companies_to_users`, {
- joins: {
- // users: {
- // sql: `${CUBE}.user_id = ${users.id}`,
- // relationship: `one_to_many`
- // },
-
- companies: {
- sql: `${CUBE}.company_id = ${companies.id}`,
- relationship: `one_to_many`
- }
- }
-
- // ...
-})
-```
-
-
-
-Now there's a join path that goes *by join definitions in the data model* from
-`users` to `companies_to_users` to `companies`. [Visual Modeler][ref-visual-model]
-also shows that you can reach `companies` from `cubes` by going left to right.
-
-
-
-
-
-One possible solution is to move one of two joins from the `companies_to_users`
-cube to either `users` or `companies` cube. Please note that it would affect
-the query semantics and thus the final result:
-
-
-
-```yaml title="YAML"
-cubes:
- - name: users
-
- joins:
- - name: companies_to_users
- sql: "{CUBE}.id = {companies_to_users}.user_id"
- relationship: one_to_many
-
- # ...
-
- - name: companies_to_users
-
- joins:
- # - name: users
- # sql: "{CUBE}.user_id = {users.id}"
- # relationship: one_to_many
-
- - name: companies
- sql: "{CUBE}.company_id = {companies.id}"
- relationship: one_to_many
-
- # ...
-```
-
-```javascript title="JavaScript"
-cube(`users`, {
- joins: {
- companies_to_users: {
- sql: `${CUBE}.id = ${companies_to_users}.user_id`,
- relationship: `one_to_many`
- }
- }
-
- // ...
-})
-
-cube(`companies_to_users`, {
- joins: {
- // users: {
- // sql: `${CUBE}.user_id = ${users.id}`,
- // relationship: `one_to_many`
- // },
-
- companies: {
- sql: `${CUBE}.company_id = ${companies.id}`,
- relationship: `one_to_many`
- }
- }
-
- // ...
-})
-```
-
-
-
-Now there's a join path that goes *by join definitions in the data model* from
-`users` to `companies_to_users` to `companies`. [Visual Modeler][ref-visual-model]
-also shows that you can reach `companies` from `cubes` by going left to right.
-
-
-  -
-
-
-[ref-schema-ref-view]: /reference/data-modeling/view
-[ref-schema-ref-joins-relationship]: /reference/data-modeling/joins#relationship
-[ref-visual-model]: /docs/data-modeling/visual-modeler
-[ref-cube]: /reference/data-modeling/cube
-[ref-cube-public]: /reference/data-modeling/cube#public
-[ref-rest-meta]: /reference/rest-api/reference#base_pathv1meta
-[ref-preaggs]: /docs/data-modeling/concepts#pre-aggregations
-[ref-primary-key]: /reference/data-modeling/dimensions#primary_key
-[ref-data-model]: /docs/data-modeling/concepts
-[ref-queries]: /reference/queries
-[ref-references]: /docs/data-modeling/syntax#cubecolumn-cubemember
-[ref-calculated-members]: /docs/data-modeling/concepts/calculated-members
-[ref-views]: /docs/data-modeling/concepts#views
-[ref-view-join-path]: /reference/data-modeling/view#join_path
-[ref-preaggs]: /docs/data-modeling/concepts#pre-aggregations
-[ref-rest-api]: /reference/rest-api
-[ref-sql-api]: /reference/sql-api
-[ref-sql-api-joins]: /reference/sql-api/joins
-[ref-rest-api-join-hints]: /reference/rest-api/query-format#query-properties
\ No newline at end of file
diff --git a/docs-mintlify/docs/data-modeling/cubes.mdx b/docs-mintlify/docs/data-modeling/cubes.mdx
new file mode 100644
index 0000000000000..45bc867e87835
--- /dev/null
+++ b/docs-mintlify/docs/data-modeling/cubes.mdx
@@ -0,0 +1,395 @@
+---
+title: Cubes
+description: Cubes represent the tables in your database. Each cube maps to a table or query in your data source and contains measures, dimensions, joins, and pre-aggregations.
+---
+
+Cubes represent the tables in your database. Each cube maps to a single
+table in your [data source][ref-data-sources] and contains the business
+logic — [measures][ref-measures], [dimensions][ref-dimensions],
+[joins][ref-joins], and [pre-aggregations][ref-pre-aggs] — that defines
+how that data can be queried.
+
+
+
+See the [cube reference][ref-cube-reference] for the full list of
+parameters and configuration options.
+
+
+
+## Defining a cube
+
+A cube points to a table in your data source using `sql_table`:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`
+})
+```
+
+
+
+You can also use the `sql` property for more complex queries:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql: |
+ SELECT *
+ FROM orders, line_items
+ WHERE orders.id = line_items.order_id
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql: `
+ SELECT *
+ FROM orders, line_items
+ WHERE orders.id = line_items.order_id
+ `
+})
+```
+
+
+
+
+
+If you're using dbt, see [this recipe][ref-cube-with-dbt] to streamline
+defining cubes on top of dbt models.
+
+
+
+## Cube members
+
+Each cube contains definitions for its members: dimensions, measures,
+and segments.
+
+### Dimensions
+
+[Dimensions][ref-dimensions] represent the properties of a single data
+point — the attributes you group by and filter on, such as `status`,
+`city`, or `created_at`:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: status
+ sql: status
+ type: string
+
+ - name: created_at
+ sql: created_at
+ type: time
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`,
+
+ dimensions: {
+ id: {
+ sql: `id`,
+ type: `number`,
+ primary_key: true
+ },
+
+ status: {
+ sql: `status`,
+ type: `string`
+ },
+
+ created_at: {
+ sql: `created_at`,
+ type: `time`
+ }
+ }
+})
+```
+
+
+
+Time dimensions enable grouping by granularity (year, quarter, month,
+week, day, hour, minute, second) and are essential for
+[partitioned pre-aggregations][ref-partition-preaggs].
+
+### Measures
+
+[Measures][ref-measures] represent aggregated values over a set of data
+points — counts, sums, averages, and custom calculations:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ # ...
+
+ measures:
+ - name: count
+ type: count
+
+ - name: total_amount
+ sql: amount
+ type: sum
+
+ - name: average_amount
+ sql: amount
+ type: avg
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ // ...
+
+ measures: {
+ count: {
+ type: `count`
+ },
+
+ total_amount: {
+ sql: `amount`,
+ type: `sum`
+ },
+
+ average_amount: {
+ sql: `amount`,
+ type: `avg`
+ }
+ }
+})
+```
+
+
+
+Measures can reference other measures to create
+[calculated measures][ref-calculated-measures], and you can apply
+[filters][ref-measure-filters] to create filtered aggregations like
+"count of completed orders."
+
+### Segments
+
+[Segments][ref-segments] are predefined filters on a cube. They allow
+you to define commonly used filter logic once and reuse it across
+queries:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ # ...
+
+ segments:
+ - name: completed
+ sql: "{CUBE}.status = 'completed'"
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ // ...
+
+ segments: {
+ completed: {
+ sql: `${CUBE}.status = 'completed'`
+ }
+ }
+})
+```
+
+
+
+## Joins
+
+[Joins][ref-joins] define relationships between cubes, forming the data
+graph that Cube uses to generate multi-table SQL queries:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+
+ joins:
+ - name: users
+ relationship: many_to_one
+ sql: "{CUBE}.user_id = {users.id}"
+
+ - name: line_items
+ relationship: one_to_many
+ sql: "{CUBE}.id = {line_items.order_id}"
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`,
+
+ joins: {
+ users: {
+ relationship: `many_to_one`,
+ sql: `${CUBE}.user_id = ${users.id}`
+ },
+
+ line_items: {
+ relationship: `one_to_many`,
+ sql: `${CUBE}.id = ${line_items.order_id}`
+ }
+ }
+})
+```
+
+
+
+Cube supports `one_to_one`, `many_to_one`, and `one_to_many` relationship
+types. See [working with joins][ref-working-with-joins] for advanced
+patterns like cross-database joins and join direction control.
+
+## Pre-aggregations
+
+[Pre-aggregations][ref-pre-aggs] are materialized summaries of cube data
+that dramatically speed up query execution. Cube automatically matches
+incoming queries to the best available pre-aggregation:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ # ...
+
+ pre_aggregations:
+ - name: main
+ measures:
+ - count
+ - total_amount
+ dimensions:
+ - status
+ time_dimension: created_at
+ granularity: day
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ // ...
+
+ pre_aggregations: {
+ main: {
+ measures: [count, total_amount],
+ dimensions: [status],
+ time_dimension: created_at,
+ granularity: `day`
+ }
+ }
+})
+```
+
+
+
+Pre-aggregations support [partitioning][ref-partition-preaggs] by time
+and [incremental refreshes][ref-incremental-preaggs] to keep materialized
+data up-to-date efficiently.
+
+## Designing effective cubes
+
+### One cube per entity
+
+Map each cube to a single business entity — `orders`, `users`,
+`products`, `line_items`. Use [joins](#joins) to connect them rather than
+creating wide cubes with data from multiple tables.
+
+### Keep naming consistent
+
+Use clear, consistent naming for members. Dimensions should describe
+attributes (`status`, `city`, `created_at`), and measures should describe
+aggregations (`count`, `total_revenue`, `average_order_value`). Add
+[`description`][ref-cube-description] and [`title`][ref-cube-title] for
+user-friendly display.
+
+### Control visibility
+
+Use [`public`][ref-cube-public] to hide cubes that should not be
+directly queried by end-users. In most data models, cubes are internal
+building blocks and [views][ref-views] are the public interface:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: base_orders
+ public: false
+ sql_table: orders
+
+ # ...
+```
+
+```javascript title="JavaScript"
+cube(`base_orders`, {
+ public: false,
+ sql_table: `orders`,
+
+ // ...
+})
+```
+
+
+
+### Scale with extension and polymorphism
+
+When cubes share common members, use [`extends`][ref-extending-cubes] to
+avoid duplication. For data models with many similar entities,
+[polymorphic cubes][ref-polymorphic-cubes] let you define a base cube
+and specialize it per entity.
+
+## Next steps
+
+- See the [cube reference][ref-cube-reference] for the full list of
+ parameters
+- Learn about [views][ref-views] to expose cubes to end-users
+- Explore [calculated measures][ref-calculated-measures] for derived metrics
+- Use the [Semantic Model IDE][ref-ide] to develop cubes interactively
+
+[wiki-view-sql]: https://en.wikipedia.org/wiki/View_(SQL)
+[ref-data-sources]: /admin/connect-to-data
+[ref-cube-reference]: /reference/data-modeling/cube
+[ref-cube-description]: /reference/data-modeling/cube#description
+[ref-cube-title]: /reference/data-modeling/cube#title
+[ref-cube-public]: /reference/data-modeling/cube#public
+[ref-measures]: /reference/data-modeling/measures
+[ref-dimensions]: /reference/data-modeling/dimensions
+[ref-segments]: /reference/data-modeling/segments
+[ref-joins]: /reference/data-modeling/joins
+[ref-pre-aggs]: /reference/data-modeling/pre-aggregations
+[ref-views]: /docs/data-modeling/views
+[ref-extending-cubes]: /docs/data-modeling/extending-cubes
+[ref-polymorphic-cubes]: /recipes/data-modeling/polymorphic-cubes
+[ref-dynamic-models]: /docs/data-modeling/dynamic
+[ref-calculated-measures]: /docs/data-modeling/measures#calculated-measures
+[ref-measure-filters]: /reference/data-modeling/measures#filters
+[ref-working-with-joins]: /docs/data-modeling/joins
+[ref-partition-preaggs]: /docs/pre-aggregations/matching-pre-aggregations#partitioning
+[ref-incremental-preaggs]: /reference/data-modeling/pre-aggregations#incremental
+[ref-cube-with-dbt]: /reference/data-modeling/cube-dbt
+[ref-explore]: /analytics/explore
+[ref-workbooks]: /analytics/workbooks
+[ref-rest-api]: /reference/core-data-apis/rest-api
+[ref-sql-api]: /reference/core-data-apis/sql-api
+[ref-ide]: /docs/data-modeling/data-model-ide
diff --git a/docs-mintlify/docs/data-modeling/dimensions.mdx b/docs-mintlify/docs/data-modeling/dimensions.mdx
new file mode 100644
index 0000000000000..08e3d1ec1f613
--- /dev/null
+++ b/docs-mintlify/docs/data-modeling/dimensions.mdx
@@ -0,0 +1,432 @@
+---
+title: Dimensions
+description: Dimensions are attributes that describe individual rows of data — the fields you group by and filter on, such as status, city, or created_at.
+---
+
+Dimensions represent attributes of individual rows in your data. They are
+the fields you group by and filter on — things like `status`, `city`,
+`product_name`, or `created_at`. Each dimension maps to a column or SQL
+expression in your data source.
+
+
+
+See the [dimensions reference][ref-dimensions-ref] for the full list of
+parameters and configuration options.
+
+
+
+## Defining dimensions
+
+A dimension specifies the SQL expression and its type:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: status
+ sql: status
+ type: string
+
+ - name: created_at
+ sql: created_at
+ type: time
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`,
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true },
+ status: { sql: `status`, type: `string` },
+ created_at: { sql: `created_at`, type: `time` }
+ }
+})
+```
+
+
+
+### Dimension types
+
+| Data type in SQL | Dimension type in Cube |
+| --- | --- |
+| `timestamp`, `date`, `time` | [`time`][ref-type] |
+| `text`, `varchar` | [`string`][ref-type] |
+| `integer`, `bigint`, `decimal` | [`number`][ref-type] |
+| `boolean` | [`boolean`][ref-type] |
+
+### Primary keys
+
+Every cube that participates in [joins][ref-joins] should define a
+[`primary_key`][ref-primary-key] dimension. Cube uses primary keys to avoid
+fanouts — when rows get duplicated during joins and aggregates are
+over-counted. Composite primary keys can be created by concatenating columns:
+
+```yaml
+dimensions:
+ - name: composite_key
+ sql: "CONCAT({CUBE}.order_id, '-', {CUBE}.product_id)"
+ type: string
+ primary_key: true
+```
+
+## Time dimensions
+
+Time dimensions are dimensions of the [`time` type][ref-type]. They enable
+grouping by time granularity (year, quarter, month, week, day, hour, minute,
+second) and are essential for time-series analysis.
+
+```yaml
+dimensions:
+ - name: created_at
+ sql: created_at
+ type: time
+```
+
+When queried, you can group by any built-in granularity without defining
+additional dimensions.
+
+### Custom granularities
+
+You can define [custom granularities][ref-granularities] for time dimensions
+when the built-in ones don't fit — for example, weeks starting on Sunday
+or fiscal years:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ # ...
+
+ dimensions:
+ - name: created_at
+ sql: created_at
+ type: time
+ granularities:
+ - name: sunday_week
+ interval: 1 week
+ offset: -1 day
+
+ - name: fiscal_year
+ interval: 1 year
+ offset: 1 month
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ // ...
+
+ dimensions: {
+ created_at: {
+ sql: `created_at`,
+ type: `time`,
+ granularities: {
+ sunday_week: { interval: `1 week`, offset: `-1 day` },
+ fiscal_year: { interval: `1 year`, offset: `1 month` }
+ }
+ }
+ }
+})
+```
+
+
+
+Time dimensions are essential for performance features like
+[partitioned pre-aggregations][ref-partition-preaggs] and
+[incremental refreshes][ref-incremental-preaggs].
+
+
+
+See the following recipes:
+- For a [custom granularity][ref-custom-granularity-recipe] example.
+- For a [custom calendar][ref-custom-calendar-recipe] example.
+
+
+
+## Proxy dimensions
+
+Proxy dimensions reference dimensions from the same cube or other cubes,
+providing a way to reuse existing definitions and reduce code duplication.
+
+### Within the same cube
+
+Reference existing dimensions to build derived ones without duplicating SQL:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: users
+ sql_table: users
+
+ dimensions:
+ - name: initials
+ sql: "SUBSTR(first_name, 1, 1)"
+ type: string
+
+ - name: last_name
+ sql: "UPPER(last_name)"
+ type: string
+
+ - name: full_name
+ sql: "{initials} || '. ' || {last_name}"
+ type: string
+```
+
+```javascript title="JavaScript"
+cube(`users`, {
+ sql_table: `users`,
+
+ dimensions: {
+ initials: { sql: `SUBSTR(first_name, 1, 1)`, type: `string` },
+ last_name: { sql: `UPPER(last_name)`, type: `string` },
+ full_name: { sql: `${initials} || '. ' || ${last_name}`, type: `string` }
+ }
+})
+```
+
+
+
+### From other cubes
+
+If cubes are [joined][ref-joins], you can bring a dimension from one cube
+into another. Cube generates the necessary joins automatically:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+
+ joins:
+ - name: users
+ sql: "{CUBE}.user_id = {users.id}"
+ relationship: many_to_one
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: user_name
+ sql: "{users.name}"
+ type: string
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`,
+
+ joins: {
+ users: {
+ sql: `${CUBE}.user_id = ${users.id}`,
+ relationship: `many_to_one`
+ }
+ },
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true },
+ user_name: { sql: `${users.name}`, type: `string` }
+ }
+})
+```
+
+
+
+### Time dimension granularity references
+
+When referencing a time dimension, you can specify a granularity to create
+a proxy dimension at that specific granularity — including
+[custom granularities](#custom-granularities):
+
+```yaml
+dimensions:
+ - name: created_at
+ sql: created_at
+ type: time
+ granularities:
+ - name: sunday_week
+ interval: 1 week
+ offset: -1 day
+
+ - name: created_at_year
+ sql: "{created_at.year}"
+ type: time
+
+ - name: created_at_sunday_week
+ sql: "{created_at.sunday_week}"
+ type: time
+```
+
+## Subquery dimensions
+
+Subquery dimensions reference [measures][ref-measures-page] from other cubes,
+effectively turning an aggregate into a per-row value. This enables nested
+aggregations — for example, calculating the average of per-customer order counts.
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+
+ joins:
+ - name: users
+ sql: "{users}.id = {CUBE}.user_id"
+ relationship: many_to_one
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ measures:
+ - name: count
+ type: count
+
+ - name: users
+ sql_table: users
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: name
+ sql: name
+ type: string
+
+ - name: order_count
+ sql: "{orders.count}"
+ type: number
+ sub_query: true
+
+ measures:
+ - name: avg_order_count
+ sql: "{order_count}"
+ type: avg
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`,
+
+ joins: {
+ users: {
+ sql: `${users}.id = ${CUBE}.user_id`,
+ relationship: `many_to_one`
+ }
+ },
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true }
+ },
+
+ measures: {
+ count: { type: `count` }
+ }
+})
+
+cube(`users`, {
+ sql_table: `users`,
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true },
+ name: { sql: `name`, type: `string` },
+
+ order_count: {
+ sql: `${orders.count}`,
+ type: `number`,
+ sub_query: true
+ }
+ },
+
+ measures: {
+ avg_order_count: {
+ sql: `${order_count}`,
+ type: `avg`
+ }
+ }
+})
+```
+
+
+
+The `order_count` subquery dimension computes the order count per user.
+The `avg_order_count` measure then averages those per-user values. Cube
+implements this as a correlated subquery via joins for optimal performance.
+
+
+
+See the following recipes:
+- How to calculate [nested aggregates][ref-nested-aggregates-recipe].
+- How to calculate [filtered aggregates][ref-filtered-aggregates-recipe].
+
+
+
+## Hierarchies
+
+Dimensions can be organized into [hierarchies][ref-hierarchies] to define
+drill-down paths (e.g., Country → State → City):
+
+```yaml
+cubes:
+ - name: users
+ # ...
+
+ dimensions:
+ - name: country
+ sql: country
+ type: string
+
+ - name: state
+ sql: state
+ type: string
+
+ - name: city
+ sql: city
+ type: string
+
+ hierarchies:
+ - name: location
+ levels:
+ - country
+ - state
+ - city
+```
+
+## Next steps
+
+- See the [dimensions reference][ref-dimensions-ref] for all parameters
+- Learn about [measures][ref-measures-page] for aggregated calculations
+- Explore [custom granularities][ref-granularities] for fiscal calendars
+ and non-standard time periods
+
+[ref-dimensions-ref]: /reference/data-modeling/dimensions
+[ref-measures-page]: /docs/data-modeling/measures
+[ref-joins]: /docs/data-modeling/joins
+[ref-type]: /reference/data-modeling/dimensions#type
+[ref-primary-key]: /reference/data-modeling/dimensions#primary_key
+[ref-granularities]: /reference/data-modeling/dimensions#granularities
+[ref-hierarchies]: /reference/data-modeling/hierarchies
+[ref-partition-preaggs]: /docs/pre-aggregations/matching-pre-aggregations#partitioning
+[ref-incremental-preaggs]: /reference/data-modeling/pre-aggregations#incremental
+[ref-custom-granularity-recipe]: /recipes/data-modeling/custom-granularity
+[ref-custom-calendar-recipe]: /recipes/data-modeling/custom-calendar
+[ref-nested-aggregates-recipe]: /recipes/data-modeling/nested-aggregates
+[ref-filtered-aggregates-recipe]: /recipes/data-modeling/filtered-aggregates
diff --git a/docs-mintlify/docs/data-modeling/concepts/code-reusability-extending-cubes.mdx b/docs-mintlify/docs/data-modeling/extending-cubes.mdx
similarity index 96%
rename from docs-mintlify/docs/data-modeling/concepts/code-reusability-extending-cubes.mdx
rename to docs-mintlify/docs/data-modeling/extending-cubes.mdx
index c3ac681f09ea2..fe1cdd83e1f86 100644
--- a/docs-mintlify/docs/data-modeling/concepts/code-reusability-extending-cubes.mdx
+++ b/docs-mintlify/docs/data-modeling/extending-cubes.mdx
@@ -1,6 +1,6 @@
---
-title: Extension
-description: Uses extends on cubes and views to inherit and merge members from a parent so shared measures, dimensions, and joins stay defined once.
+title: Extending cubes
+description: Use extends on cubes to inherit and merge members from a parent so shared measures, dimensions, and joins stay defined once.
---
The `extends` parameter, supported for [cubes][ref-cube-extends] and
diff --git a/docs-mintlify/docs/data-modeling/joins.mdx b/docs-mintlify/docs/data-modeling/joins.mdx
new file mode 100644
index 0000000000000..d26b06c3d881a
--- /dev/null
+++ b/docs-mintlify/docs/data-modeling/joins.mdx
@@ -0,0 +1,542 @@
+---
+title: Joins
+description: Joins define relationships between cubes, allowing Cube to automatically generate multi-table SQL queries when views combine data from multiple cubes.
+---
+
+Joins define how cubes connect to each other. When a [view][ref-views]
+includes members from multiple cubes, Cube uses these relationships to
+automatically generate SQL `JOIN` clauses — so end-users can explore data
+across tables without writing SQL.
+
+
+
+See the [joins reference][ref-schema-ref-joins-relationship] for the full
+list of parameters and configuration options.
+
+
+
+## Relationship types
+
+Cube supports three relationship types: `one_to_one`, `one_to_many`, and
+`many_to_one`. The relationship type determines which table becomes the left
+side of the `LEFT JOIN` in the generated SQL.
+
+Consider two cubes, `orders` and `customers`. An order belongs to one
+customer, but a customer can have many orders:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+
+ joins:
+ - name: customers
+ relationship: many_to_one
+ sql: "{CUBE}.customer_id = {customers.id}"
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: status
+ sql: status
+ type: string
+
+ measures:
+ - name: count
+ type: count
+
+ - name: customers
+ sql_table: customers
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: company
+ sql: company
+ type: string
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`,
+
+ joins: {
+ customers: {
+ relationship: `many_to_one`,
+ sql: `${CUBE}.customer_id = ${customers.id}`
+ }
+ },
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true },
+ status: { sql: `status`, type: `string` }
+ },
+
+ measures: {
+ count: { type: `count` }
+ }
+})
+
+cube(`customers`, {
+ sql_table: `customers`,
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true },
+ company: { sql: `company`, type: `string` }
+ }
+})
+```
+
+
+
+The `many_to_one` join on `orders` means: many orders belong to one customer.
+When a view includes members from both cubes, Cube generates SQL with `orders`
+on the left and `customers` on the right:
+
+```sql
+SELECT
+ "orders".status,
+ "customers".company,
+ COUNT("orders".id)
+FROM orders AS "orders"
+LEFT JOIN customers AS "customers"
+ ON "orders".customer_id = "customers".id
+GROUP BY 1, 2
+```
+
+Because `orders` is on the left side of the `LEFT JOIN`, all orders are
+preserved — including guest checkouts with no matching customer.
+
+
+
+As a rule of thumb, define joins on the **fact table** (e.g., `orders`)
+pointing toward the **dimension table** (e.g., `customers`) using
+`many_to_one`. This ensures the fact table is always the base of the query,
+preserving all its rows.
+
+
+
+### Many-to-many relationships
+
+A many-to-many relationship requires an associative (junction) table. For
+example, `posts` and `topics` are connected through a `post_topics` table:
+
+
+
+
+
+Model this with an associative cube, chaining the joins so they flow in one
+direction (`posts → post_topics → topics`):
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: posts
+ sql_table: posts
+
+ joins:
+ - name: post_topics
+ relationship: one_to_many
+ sql: "{CUBE}.id = {post_topics.post_id}"
+
+ - name: post_topics
+ sql_table: post_topics
+
+ joins:
+ - name: topics
+ relationship: many_to_one
+ sql: "{CUBE}.topic_id = {topics.id}"
+
+ dimensions:
+ - name: id
+ sql: "CONCAT({CUBE}.post_id, {CUBE}.topic_id)"
+ type: string
+ primary_key: true
+
+ - name: topics
+ sql_table: topics
+
+ dimensions:
+ - name: id
+ sql: id
+ type: string
+ primary_key: true
+
+ - name: name
+ sql: name
+ type: string
+```
+
+```javascript title="JavaScript"
+cube(`posts`, {
+ sql_table: `posts`,
+
+ joins: {
+ post_topics: {
+ relationship: `one_to_many`,
+ sql: `${CUBE}.id = ${post_topics.post_id}`
+ }
+ }
+})
+
+cube(`post_topics`, {
+ sql_table: `post_topics`,
+
+ joins: {
+ topics: {
+ relationship: `many_to_one`,
+ sql: `${CUBE}.topic_id = ${topics.id}`
+ }
+ },
+
+ dimensions: {
+ id: {
+ sql: `CONCAT(${CUBE}.post_id, ${CUBE}.topic_id)`,
+ type: `string`,
+ primary_key: true
+ }
+ }
+})
+
+cube(`topics`, {
+ sql_table: `topics`,
+
+ dimensions: {
+ id: { sql: `id`, type: `string`, primary_key: true },
+ name: { sql: `name`, type: `string` }
+ }
+})
+```
+
+
+
+A view can then expose this through the `join_path`:
+
+```yaml
+views:
+ - name: posts_with_topics
+ cubes:
+ - join_path: posts
+ includes:
+ - title
+ - count
+
+ - join_path: posts.post_topics.topics
+ prefix: true
+ includes:
+ - name
+```
+
+## Direction of joins
+
+**All joins are directed.** They flow from the source cube (where the join
+is defined) to the target cube (the one referenced). Cube places the source
+cube on the left side of the `LEFT JOIN` and the target on the right.
+
+This matters because the left table preserves all its rows, while the right
+table contributes matching rows or `NULL`. The direction you choose affects
+which records appear in the result set.
+
+For example, if `orders` defines a `many_to_one` join to `customers`:
+- `orders` is the base → all orders are preserved, even guest checkouts
+- `customers` without orders won't appear
+
+If instead `customers` defined a `one_to_many` join to `orders`:
+- `customers` is the base → all customers are preserved, even those without orders
+- Guest checkout orders (with no matching customer) won't appear
+
+### Using views to control direction
+
+Views let you control which join path is followed via the
+[`join_path`][ref-view-join-path] parameter. This is the recommended way to
+handle cases where you need different join directions for different use cases:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+
+ joins:
+ - name: customers
+ sql: "{CUBE}.customer_id = {customers.id}"
+ relationship: many_to_one
+
+ measures:
+ - name: count
+ type: count
+
+ - name: total_revenue
+ sql: revenue
+ type: sum
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: customers
+ sql_table: customers
+
+ joins:
+ - name: orders
+ sql: "{CUBE}.id = {orders.customer_id}"
+ relationship: one_to_many
+
+ measures:
+ - name: count
+ type: count
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: name
+ sql: name
+ type: string
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`,
+
+ joins: {
+ customers: {
+ sql: `${CUBE}.customer_id = ${customers.id}`,
+ relationship: `many_to_one`
+ }
+ },
+
+ measures: {
+ count: { type: `count` },
+ total_revenue: { sql: `revenue`, type: `sum` }
+ },
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true }
+ }
+})
+
+cube(`customers`, {
+ sql_table: `customers`,
+
+ joins: {
+ orders: {
+ sql: `${CUBE}.id = ${orders.customer_id}`,
+ relationship: `one_to_many`
+ }
+ },
+
+ measures: {
+ count: { type: `count` }
+ },
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true },
+ name: { sql: `name`, type: `string` }
+ }
+})
+```
+
+
+
+Now you can create two views for two different analytical needs:
+
+
+
+```yaml title="YAML"
+views:
+ - name: revenue_per_customer
+ description: All orders with customer details. Includes guest checkouts.
+ cubes:
+ - join_path: orders
+ includes:
+ - count
+ - total_revenue
+
+ - join_path: orders.customers
+ includes:
+ - name
+
+ - name: customer_activity
+ description: All customers with their order activity. Includes customers without orders.
+ cubes:
+ - join_path: customers
+ includes:
+ - name
+ - count
+
+ - join_path: customers.orders
+ prefix: true
+ includes:
+ - count
+ - total_revenue
+```
+
+```javascript title="JavaScript"
+view(`revenue_per_customer`, {
+ description: `All orders with customer details. Includes guest checkouts.`,
+ cubes: [
+ {
+ join_path: orders,
+ includes: [`count`, `total_revenue`]
+ },
+ {
+ join_path: orders.customers,
+ includes: [`name`]
+ }
+ ]
+})
+
+view(`customer_activity`, {
+ description: `All customers with their order activity. Includes customers without orders.`,
+ cubes: [
+ {
+ join_path: customers,
+ includes: [`name`, `count`]
+ },
+ {
+ join_path: customers.orders,
+ prefix: true,
+ includes: [`count`, `total_revenue`]
+ }
+ ]
+})
+```
+
+
+
+The `revenue_per_customer` view follows the `orders → customers` path, so all
+orders are preserved. The `customer_activity` view follows
+`customers → orders`, so all customers are preserved.
+
+## Diamond subgraphs
+
+A _diamond subgraph_ occurs when there's more than one join path between two
+cubes — for example, `users.schools.countries` and
+`users.employers.countries`. This can lead to ambiguous query generation.
+
+Views resolve this ambiguity by specifying the exact `join_path` for each
+included cube. For example, if cube `a` joins to both `b` and `c`, and both
+`b` and `c` join to `d`, a view can specify which path to follow:
+
+```yaml
+views:
+ - name: a_with_d_via_b
+ cubes:
+ - join_path: a
+ includes: "*"
+
+ - join_path: a.b.d
+ prefix: true
+ includes:
+ - value
+
+ - name: a_with_d_via_c
+ cubes:
+ - join_path: a
+ includes: "*"
+
+ - join_path: a.c.d
+ prefix: true
+ includes:
+ - value
+```
+
+Each view follows a specific, unambiguous path through the data graph.
+
+## Join paths in calculated members
+
+When referencing a member of another cube in a [calculated member][ref-calculated-members],
+you can use a join path to specify the exact route. This uses dot-separated
+cube names:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ # ...
+
+ dimensions:
+ - name: customer_country
+ sql: "{customers.country}"
+ type: string
+
+ - name: shipping_country
+ sql: "{shipping_addresses.country}"
+ type: string
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ // ...
+
+ dimensions: {
+ customer_country: {
+ sql: `${customers.country}`,
+ type: `string`
+ },
+
+ shipping_country: {
+ sql: `${shipping_addresses.country}`,
+ type: `string`
+ }
+ }
+})
+```
+
+
+
+## Troubleshooting
+
+### `Can't find join path`
+
+The error `Can't find join path to join 'cube_a', 'cube_b'` means the cubes
+included in a view or query can't be connected through the defined joins.
+
+Check that:
+- Joins are defined with the correct [direction](#direction-of-joins)
+- There is a continuous path from the source cube to the target cube
+- You're using the [`join_path`][ref-view-join-path] parameter in views to
+ specify the exact path
+
+### `Primary key is required when join is defined`
+
+Cube uses primary keys to avoid fanouts — when rows get duplicated during
+joins and aggregates are over-counted. Define a [primary key][ref-primary-key]
+dimension in every cube that participates in joins.
+
+If your data doesn't have a natural primary key, create a composite one:
+
+```yaml
+cubes:
+ - name: events
+ # ...
+
+ dimensions:
+ - name: composite_key
+ sql: CONCAT(column_a, '-', column_b, '-', column_c)
+ type: string
+ primary_key: true
+```
+
+[ref-schema-ref-joins-relationship]: /reference/data-modeling/joins
+[ref-views]: /docs/data-modeling/views
+[ref-view-join-path]: /reference/data-modeling/view#join_path
+[ref-calculated-members]: /docs/data-modeling/measures#calculated-measures
+[ref-primary-key]: /reference/data-modeling/dimensions#primary_key
+[ref-visual-model]: /docs/data-modeling/visual-modeler
diff --git a/docs-mintlify/docs/data-modeling/measures.mdx b/docs-mintlify/docs/data-modeling/measures.mdx
new file mode 100644
index 0000000000000..0a443613af3bb
--- /dev/null
+++ b/docs-mintlify/docs/data-modeling/measures.mdx
@@ -0,0 +1,434 @@
+---
+title: Measures
+description: Measures compute aggregated values across rows — counts, sums, averages, and more complex calculations like rolling windows, time shifts, and rankings.
+---
+
+While [dimensions][ref-dimensions-page] describe attributes of individual rows,
+measures compute values across rows — sums, counts, averages, and other
+aggregations. Measures can aggregate columns directly (like `sum of revenue`)
+or reference other measures to create compound metrics (like `revenue / count`).
+
+
+
+See the [measures reference][ref-measures-ref] for the full list of parameters
+and configuration options.
+
+
+
+## Defining measures
+
+A measure specifies the SQL expression to aggregate and the aggregation type:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+
+ measures:
+ - name: count
+ type: count
+
+ - name: total_amount
+ sql: amount
+ type: sum
+
+ - name: average_amount
+ sql: amount
+ type: avg
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`,
+
+ measures: {
+ count: { type: `count` },
+ total_amount: { sql: `amount`, type: `sum` },
+ average_amount: { sql: `amount`, type: `avg` }
+ }
+})
+```
+
+
+
+## Filtered measures
+
+You can apply [filters][ref-filters] to a measure to create conditional
+aggregations. Only rows matching the filter are included:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ # ...
+
+ measures:
+ - name: count
+ type: count
+
+ - name: completed_count
+ type: count
+ filters:
+ - sql: "{CUBE}.status = 'completed'"
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ // ...
+
+ measures: {
+ count: { type: `count` },
+
+ completed_count: {
+ type: `count`,
+ filters: [{ sql: `${CUBE}.status = 'completed'` }]
+ }
+ }
+})
+```
+
+
+
+When `completed_count` is queried, Cube generates SQL with a `CASE` expression:
+
+```sql
+SELECT
+ COUNT(CASE WHEN (orders.status = 'completed') THEN 1 END) AS completed_count
+FROM orders
+```
+
+## Calculated measures
+
+Calculated measures perform calculations on other measures using SQL functions
+and operators. They provide a way to decompose complex metrics (e.g., ratios
+or percents) into formulas involving simpler measures.
+
+### Referencing measures in the same cube
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ # ...
+
+ measures:
+ - name: count
+ type: count
+
+ - name: completed_count
+ type: count
+ filters:
+ - sql: "{CUBE}.status = 'completed'"
+
+ - name: completed_ratio
+ sql: "1.0 * {completed_count} / NULLIF({count}, 0)"
+ type: number
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ // ...
+
+ measures: {
+ count: { type: `count` },
+
+ completed_count: {
+ type: `count`,
+ filters: [{ sql: `${CUBE}.status = 'completed'` }]
+ },
+
+ completed_ratio: {
+ sql: `1.0 * ${completed_count} / NULLIF(${count}, 0)`,
+ type: `number`
+ }
+ }
+})
+```
+
+
+
+### Referencing measures from other cubes
+
+If cubes are [joined][ref-joins], you can reference measures across cubes.
+Cube generates the necessary joins automatically:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: users
+ # ...
+
+ joins:
+ - name: orders
+ sql: "{CUBE}.id = {orders}.user_id"
+ relationship: one_to_many
+
+ measures:
+ - name: count
+ type: count
+
+ - name: purchases_to_users_ratio
+ sql: "1.0 * {orders.purchases} / NULLIF({CUBE.count}, 0)"
+ type: number
+```
+
+```javascript title="JavaScript"
+cube(`users`, {
+ // ...
+
+ joins: {
+ orders: {
+ sql: `${CUBE}.id = ${orders}.user_id`,
+ relationship: `one_to_many`
+ }
+ },
+
+ measures: {
+ count: { type: `count` },
+
+ purchases_to_users_ratio: {
+ sql: `1.0 * ${orders.purchases} / NULLIF(${CUBE.count}, 0)`,
+ type: `number`
+ }
+ }
+})
+```
+
+
+
+## Multi-stage measures
+
+Multi-stage measures are calculated in two or more stages, enabling
+calculations on already-aggregated data. Each stage results in one or more
+CTEs in the generated SQL query.
+
+
+
+Multi-stage measures are powered by Tesseract, the [next-generation data
+modeling engine][link-tesseract]. Tesseract is currently in preview. Use the
+[`CUBEJS_TESSERACT_SQL_PLANNER`][ref-tesseract-env] environment variable to
+enable it.
+
+
+
+### Rolling windows
+
+Rolling window measures calculate metrics over a moving window of time, such
+as cumulative counts or moving averages. Use the
+[`rolling_window`][ref-rolling-window] parameter:
+
+```yaml
+measures:
+ - name: cumulative_count
+ type: count
+ rolling_window:
+ trailing: unbounded
+
+ - name: trailing_month_count
+ sql: id
+ type: count
+ rolling_window:
+ trailing: 1 month
+```
+
+### Period-to-date
+
+Period-to-date measures analyze data from the start of a period to the current
+date — year-to-date (YTD), quarter-to-date (QTD), or month-to-date (MTD):
+
+```yaml
+measures:
+ - name: revenue_ytd
+ sql: revenue
+ type: sum
+ rolling_window:
+ type: to_date
+ granularity: year
+
+ - name: revenue_qtd
+ sql: revenue
+ type: sum
+ rolling_window:
+ type: to_date
+ granularity: quarter
+```
+
+### Time shift
+
+Time-shift measures calculate the value of another measure at a different
+point in time, typically for period-over-period comparisons like
+year-over-year growth. Use the [`time_shift`][ref-time-shift] parameter:
+
+```yaml
+measures:
+ - name: revenue
+ sql: revenue
+ type: sum
+
+ - name: revenue_prior_year
+ multi_stage: true
+ sql: "{revenue}"
+ type: number
+ time_shift:
+ - interval: 1 year
+ type: prior
+```
+
+You can combine time shift with period-to-date for comparisons like
+"this year's YTD vs. last year's YTD":
+
+```yaml
+measures:
+ - name: revenue_ytd
+ sql: revenue
+ type: sum
+ rolling_window:
+ type: to_date
+ granularity: year
+
+ - name: revenue_prior_year_ytd
+ multi_stage: true
+ sql: "{revenue_ytd}"
+ type: number
+ time_shift:
+ - time_dimension: time
+ interval: 1 year
+ type: prior
+```
+
+Time-shift measures can also be used with [calendar cubes][ref-calendar-cubes]
+to customize how time-shifting works, e.g., to shift by retail calendar
+periods.
+
+### Percent of total (fixed dimension)
+
+Use the [`group_by`][ref-group-by] parameter to fix the inner aggregation to
+specific dimensions, enabling percent-of-total calculations:
+
+```yaml
+measures:
+ - name: revenue
+ sql: revenue
+ type: sum
+
+ - name: country_revenue
+ multi_stage: true
+ sql: "{revenue}"
+ type: sum
+ group_by:
+ - country
+
+ - name: country_revenue_percentage
+ multi_stage: true
+ sql: "{revenue} / NULLIF({country_revenue}, 0)"
+ type: number
+```
+
+### Nested aggregates
+
+Use the [`add_group_by`][ref-add-group-by] parameter to compute an aggregate
+of an aggregate, e.g., the average of per-customer averages:
+
+```yaml
+measures:
+ - name: avg_order_value
+ sql: amount
+ type: avg
+
+ - name: avg_customer_order_value
+ multi_stage: true
+ sql: "{avg_order_value}"
+ type: avg
+ add_group_by:
+ - customer_id
+```
+
+### Ranking
+
+Use the [`reduce_by`][ref-reduce-by] parameter to rank items within groups:
+
+```yaml
+measures:
+ - name: revenue
+ sql: revenue
+ type: sum
+
+ - name: product_rank
+ multi_stage: true
+ order_by:
+ - sql: "{revenue}"
+ dir: asc
+ reduce_by:
+ - product
+ type: rank
+```
+
+### Conditional measures
+
+Conditional measures depend on the value of a dimension, using the
+[`case`][ref-case] parameter with [`switch` dimensions][ref-switch-dim]:
+
+```yaml
+measures:
+ - name: amount_in_currency
+ multi_stage: true
+ case:
+ switch: "{CUBE.currency}"
+ when:
+ - value: EUR
+ sql: "{CUBE.amount_eur}"
+ - value: GBP
+ sql: "{CUBE.amount_gbp}"
+ else:
+ sql: "{CUBE.amount_usd}"
+ type: number
+```
+
+## Formatting
+
+Use the [`format`][ref-format] parameter to control how measures are displayed:
+
+```yaml
+measures:
+ - name: total_revenue
+ sql: revenue
+ type: sum
+ format: currency
+
+ - name: conversion_rate
+ sql: "1.0 * {completed_count} / NULLIF({count}, 0)"
+ type: number
+ format: percent
+```
+
+## Next steps
+
+- See the [measures reference][ref-measures-ref] for all parameters
+- Learn about [dimensions][ref-dimensions-page] for grouping and filtering
+- Explore [pre-aggregations][ref-pre-aggs] to accelerate measure queries
+- See the [period-over-period recipe][ref-pop-recipe] for advanced time
+ comparisons
+
+[ref-measures-ref]: /reference/data-modeling/measures
+[ref-dimensions-page]: /docs/data-modeling/dimensions
+[ref-joins]: /docs/data-modeling/joins
+[ref-pre-aggs]: /reference/data-modeling/pre-aggregations
+[ref-type]: /reference/data-modeling/measures#type
+[ref-filters]: /reference/data-modeling/measures#filters
+[ref-format]: /reference/data-modeling/measures#format
+[ref-rolling-window]: /reference/data-modeling/measures#rolling_window
+[ref-time-shift]: /reference/data-modeling/measures#time_shift
+[ref-group-by]: /reference/data-modeling/measures#group_by
+[ref-reduce-by]: /reference/data-modeling/measures#reduce_by
+[ref-add-group-by]: /reference/data-modeling/measures#add_group_by
+[ref-case]: /reference/data-modeling/measures#case
+[ref-switch-dim]: /reference/data-modeling/dimensions#type
+[ref-tesseract-env]: /reference/configuration/environment-variables#cubejs_tesseract_sql_planner
+[ref-calendar-cubes]: /docs/data-modeling/concepts/calendar-cubes
+[ref-pop-recipe]: /recipes/data-modeling/period-over-period
+[link-tesseract]: https://cube.dev/blog/introducing-next-generation-data-modeling-engine
diff --git a/docs-mintlify/docs/data-modeling/multi-fact-views.mdx b/docs-mintlify/docs/data-modeling/multi-fact-views.mdx
new file mode 100644
index 0000000000000..bd9634615ab87
--- /dev/null
+++ b/docs-mintlify/docs/data-modeling/multi-fact-views.mdx
@@ -0,0 +1,421 @@
+---
+title: Multi-fact views
+description: Analyze data across multiple fact tables that share common dimensions like time or customers, without row multiplication or manual workarounds.
+---
+
+In many data models, you have multiple fact tables that share common
+dimensions but have no direct relationship to each other. For example,
+an e-commerce company tracks both orders and returns:
+
+- **`orders`** — one row per order, with `customer_id` and `created_at`
+- **`returns`** — one row per return, with `customer_id` and `created_at`
+- **`customers`** — one row per customer
+- **`dates`** — a date spine
+
+Both `orders` and `returns` join to `customers` and `dates`, but they don't
+join to each other:
+
+```
+ customers
+ / \
+ orders returns
+ \ /
+ dates
+```
+
+You need a report showing `orders_count`, `total_revenue`, `returns_count`,
+and `total_refunds` grouped by customer and month. But joining `orders` and
+`returns` directly would produce a cross product — every order matched with
+every return for that customer and date — inflating all counts and sums.
+
+## How multi-fact views solve this
+
+In a regular [view][ref-views], there is a single **root cube** — the first
+cube listed in the view's `cubes` array. All joins flow from this root, and
+Cube uses it as the base table in the generated SQL.
+
+Multi-fact views work differently. When a view includes measures from
+**multiple fact tables**, Cube selects the root dynamically at query time
+based on which measures are requested. Each fact table gets its own
+aggregating subquery, and the results are joined on the shared dimensions.
+No fanout, no manual workarounds.
+
+
+
+Multi-fact views are powered by Tesseract, the [next-generation data modeling
+engine][link-tesseract]. Tesseract is currently in preview. Use the
+[`CUBEJS_TESSERACT_SQL_PLANNER`][ref-tesseract-env] environment variable to
+enable it.
+
+
+
+## How to model it
+
+### 1. Define the cubes
+
+Each fact table becomes a cube with explicit joins to the shared dimension
+tables:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: customers
+ sql_table: customers
+
+ dimensions:
+ - name: id
+ type: number
+ sql: id
+ primary_key: true
+ - name: name
+ type: string
+ sql: name
+ - name: city
+ type: string
+ sql: city
+
+ - name: dates
+ sql_table: dates
+
+ dimensions:
+ - name: date
+ type: time
+ sql: date
+ primary_key: true
+
+ - name: orders
+ sql_table: orders
+
+ joins:
+ - name: customers
+ relationship: many_to_one
+ sql: "{orders}.customer_id = {customers.id}"
+ - name: dates
+ relationship: many_to_one
+ sql: "DATE_TRUNC('day', {orders}.created_at) = {dates.date}"
+
+ dimensions:
+ - name: id
+ type: number
+ sql: id
+ primary_key: true
+ - name: status
+ type: string
+ sql: status
+
+ measures:
+ - name: count
+ type: count
+ - name: total_amount
+ type: sum
+ sql: amount
+
+ - name: returns
+ sql_table: returns
+
+ joins:
+ - name: customers
+ relationship: many_to_one
+ sql: "{returns}.customer_id = {customers.id}"
+ - name: dates
+ relationship: many_to_one
+ sql: "DATE_TRUNC('day', {returns}.created_at) = {dates.date}"
+
+ dimensions:
+ - name: id
+ type: number
+ sql: id
+ primary_key: true
+
+ measures:
+ - name: count
+ type: count
+ - name: total_refund
+ type: sum
+ sql: refund_amount
+```
+
+```javascript title="JavaScript"
+cube(`customers`, {
+ sql_table: `customers`,
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true },
+ name: { sql: `name`, type: `string` },
+ city: { sql: `city`, type: `string` }
+ }
+})
+
+cube(`dates`, {
+ sql_table: `dates`,
+
+ dimensions: {
+ date: { sql: `date`, type: `time`, primary_key: true }
+ }
+})
+
+cube(`orders`, {
+ sql_table: `orders`,
+
+ joins: {
+ customers: {
+ relationship: `many_to_one`,
+ sql: `${orders}.customer_id = ${customers.id}`
+ },
+ dates: {
+ relationship: `many_to_one`,
+ sql: `DATE_TRUNC('day', ${orders}.created_at) = ${dates.date}`
+ }
+ },
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true },
+ status: { sql: `status`, type: `string` }
+ },
+
+ measures: {
+ count: { type: `count` },
+ total_amount: { sql: `amount`, type: `sum` }
+ }
+})
+
+cube(`returns`, {
+ sql_table: `returns`,
+
+ joins: {
+ customers: {
+ relationship: `many_to_one`,
+ sql: `${returns}.customer_id = ${customers.id}`
+ },
+ dates: {
+ relationship: `many_to_one`,
+ sql: `DATE_TRUNC('day', ${returns}.created_at) = ${dates.date}`
+ }
+ },
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true }
+ },
+
+ measures: {
+ count: { type: `count` },
+ total_refund: { sql: `refund_amount`, type: `sum` }
+ }
+})
+```
+
+
+
+The critical detail: both `orders` and `returns` declare direct joins to
+`customers` and `dates`. This tells Cube that these dimension tables are shared
+between the two facts.
+
+### 2. Create a view
+
+The view brings both fact tables and the shared dimension tables together.
+Dimension tables are included at root-level join paths (not nested under a
+specific fact), which makes their dimensions common to both facts. Use
+`prefix` to disambiguate identically named members across fact cubes:
+
+
+
+```yaml title="YAML"
+views:
+ - name: customer_overview
+ cubes:
+ - join_path: orders
+ prefix: true
+ includes:
+ - count
+ - total_amount
+ - join_path: returns
+ prefix: true
+ includes:
+ - count
+ - total_refund
+ - join_path: customers
+ includes:
+ - name
+ - city
+ - join_path: dates
+ includes:
+ - date
+```
+
+```javascript title="JavaScript"
+view(`customer_overview`, {
+ cubes: [
+ {
+ join_path: orders,
+ prefix: true,
+ includes: [`count`, `total_amount`]
+ },
+ {
+ join_path: returns,
+ prefix: true,
+ includes: [`count`, `total_refund`]
+ },
+ {
+ join_path: customers,
+ includes: [`name`, `city`]
+ },
+ {
+ join_path: dates,
+ includes: [`date`]
+ }
+ ]
+})
+```
+
+
+
+When you query `orders_count`, `orders_total_amount`, `returns_count`, and
+`returns_total_refund` grouped by `name`, `city`, and `date`, Cube detects
+the two separate fact roots and automatically executes a multi-fact query.
+
+## What Cube does under the hood
+
+Cube executes the query in three stages:
+
+### 1. Separate aggregating subqueries
+
+Each fact table gets its own independent subquery that joins only the tables
+it needs, applies relevant filters, and aggregates by the common dimensions:
+
+- **Subquery 1** (orders): joins `orders` → `customers` and `orders` → `dates`,
+ computes `COUNT(*)` and `SUM(amount)`, grouped by `name`, `city`, `date`
+- **Subquery 2** (returns): joins `returns` → `customers` and `returns` → `dates`,
+ computes `COUNT(*)` and `SUM(refund_amount)`, grouped by `name`, `city`, `date`
+
+### 2. Join on common dimensions
+
+The subquery results are joined with `FULL JOIN` on all common dimension
+columns (`name`, `city`, `date`). This preserves rows that exist in only one
+fact table — a customer who placed orders but never returned anything still
+appears in the results.
+
+### 3. Final result
+
+The combined result shows measures from each fact table side by side:
+
+| name | city | date | orders_count | orders_total_amount | returns_count | returns_total_refund |
+| --- | --- | --- | --- | --- | --- | --- |
+| Alice | New York | 2025-01-15 | 2 | 200.00 | 0 | NULL |
+| Alice | New York | 2025-02-10 | 2 | 225.00 | 1 | 100.00 |
+| Bob | Seattle | 2025-01-20 | 3 | 550.00 | 2 | 130.00 |
+| Charlie | New York | 2025-02-05 | 0 | NULL | 2 | 100.00 |
+| Diana | Boston | 2025-03-01 | 1 | 400.00 | 0 | NULL |
+
+Charlie has no orders and Diana has no returns — both are still included
+with `NULL` values for the missing fact table.
+
+## Common patterns
+
+### Time as the shared dimension
+
+The most common multi-fact pattern uses time as the shared dimension.
+For example, you might have `page_views`, `signups`, and `purchases` that all
+have timestamps but no direct relationship. By joining each to a shared
+`dates` cube, you can analyze conversion funnels — page views vs. signups
+vs. purchases by day — without any row multiplication.
+
+### More than two fact tables
+
+Multi-fact queries are not limited to two fact tables. If a view includes
+three or more facts, each gets its own aggregating subquery, and all results
+are joined on the common dimensions.
+
+### Facts that don't share all dimensions
+
+Every root fact table must be joinable to the **same set of common dimension
+tables**. If a fact table doesn't naturally have a foreign key for one of the
+common dimensions, you can create a synthetic join:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: refunds
+ sql: >
+ SELECT *, NULL AS customer_id FROM refunds
+ joins:
+ - name: customers
+ relationship: many_to_one
+ sql: "{refunds}.customer_id = {customers.id}"
+ - name: dates
+ relationship: many_to_one
+ sql: "DATE_TRUNC('day', {refunds}.created_at) = {dates.date}"
+
+ dimensions:
+ - name: id
+ type: number
+ sql: id
+ primary_key: true
+
+ measures:
+ - name: count
+ type: count
+ - name: total_amount
+ type: sum
+ sql: amount
+```
+
+```javascript title="JavaScript"
+cube(`refunds`, {
+ sql: `SELECT *, NULL AS customer_id FROM refunds`,
+
+ joins: {
+ customers: {
+ relationship: `many_to_one`,
+ sql: `${refunds}.customer_id = ${customers.id}`
+ },
+ dates: {
+ relationship: `many_to_one`,
+ sql: `DATE_TRUNC('day', ${refunds}.created_at) = ${dates.date}`
+ }
+ },
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true }
+ },
+
+ measures: {
+ count: { type: `count` },
+ total_amount: { sql: `amount`, type: `sum` }
+ }
+})
+```
+
+
+
+The `NULL AS customer_id` makes the join syntactically valid. Refund rows
+won't match a specific customer, but the subquery can still participate in
+the multi-fact join on the full set of common dimensions.
+
+## Filters and segments
+
+**Common dimension filters** (like `city = 'New York'` or `date > '2025-01-01'`)
+are applied to every subquery, ensuring consistent filtering across all facts.
+
+**Fact-specific filters** (like `orders.status = 'completed'`) are applied only
+to that fact's subquery. Other fact subqueries remain unaffected.
+
+**Measure filters** (like `orders_count > 1`) are applied as `HAVING`
+conditions after the subqueries are joined.
+
+[Segments][ref-segments] that belong to a specific fact table are applied only
+to that fact's subquery.
+
+## Join path requirements
+
+- Each fact cube must declare **direct joins** to all shared dimension tables
+- Dimension tables should be included in the view at **root-level join paths**,
+ not nested under a specific fact (e.g., `customers`, not `orders.customers`)
+- Use `prefix` on fact cubes to disambiguate identically named members
+
+[ref-views]: /docs/data-modeling/views
+[ref-view-ref]: /reference/data-modeling/view
+[ref-segments]: /reference/data-modeling/segments
+[ref-tesseract-env]: /reference/configuration/environment-variables#cubejs_tesseract_sql_planner
+[link-tesseract]: https://cube.dev/blog/introducing-tesseract
diff --git a/docs-mintlify/docs/data-modeling/overview.mdx b/docs-mintlify/docs/data-modeling/overview.mdx
index 80da010e3109a..3fad11bf20061 100644
--- a/docs-mintlify/docs/data-modeling/overview.mdx
+++ b/docs-mintlify/docs/data-modeling/overview.mdx
@@ -3,23 +3,10 @@ title: Getting started
description: Build a reusable semantic layer that provides the shared context for AI agents, BI dashboards, and embedded analytics — turning warehouse tables into governed metrics and dimensions.
---
-The data model is used to transform raw data into meaningful business
-definitions and pre-aggregate data for optimal results. The data model is
-exposed through a [rich set of APIs][ref-apis] that allows end-users to
-run a wide variety of analytical queries without modifying the data model
-itself.
-
-
-
-You can explore a carefully crafted sample data model if you create a [demo
-deployment][ref-demo-deployment] in Cube Cloud.
-
-
-
Let’s use a users table with the following columns as an example:
| id | paying | city | company_name |
@@ -42,8 +29,8 @@ allows building well-organized and reusable SQL.
## 1. Creating a Cube
-In Cube, [cubes][ref-schema-cube] are used to organize entities and connections
-between entities. Usually one cube is created for each table in the database,
+In Cube, [cubes][ref-schema-cube] are used to organize tables and connections
+between tables. Usually one cube is created for each table in the database,
such as `users`, `orders`, `products`, etc. In the `sql_table` parameter of the
cube we define a base table for this cube. In our case, the base table is simply
our `users` table.
@@ -290,7 +277,7 @@ measure via an API, the following SQL will be generated:
```sql
SELECT
- 100.0 * COUNT(
+ 1.0 * COUNT(
CASE WHEN (users.paying = 'true') THEN users.id END
) / COUNT(users.id) AS paying_percentage
FROM users
@@ -349,7 +336,7 @@ model.
[ref-backend-query-format]: /reference/rest-api/query-format
[ref-demo-deployment]: /docs/deployment/cloud/deployments#demo-deployments
[ref-apis]: /reference
-[ref-calculated-measures]: /docs/data-modeling/concepts/calculated-members#calculated-measures
+[ref-calculated-measures]: /docs/data-modeling/measures#calculated-measures
[ref-views]: /reference/data-modeling/view
[ref-explore]: /analytics/explore
[ref-workbooks]: /analytics/workbooks
\ No newline at end of file
diff --git a/docs-mintlify/docs/data-modeling/views.mdx b/docs-mintlify/docs/data-modeling/views.mdx
new file mode 100644
index 0000000000000..30dbc77f86aa6
--- /dev/null
+++ b/docs-mintlify/docs/data-modeling/views.mdx
@@ -0,0 +1,449 @@
+---
+title: Views
+description: Views are curated datasets that sit on top of cubes and create a user-friendly facade of your data model for downstream consumers, AI agents, and embedded analytics.
+---
+
+Views sit on top of the data graph of [cubes][ref-cubes] and create a facade
+of your whole data model with which data consumers can interact. They bring
+together relevant measures, dimensions, and join paths into a logical
+structure that matches how business users think about their data.
+
+
+
+
+
+
+
+See the [view reference][ref-view-reference] for the full list of
+parameters and configuration options.
+
+
+
+## Why views matter
+
+Views are the primary interface between your data model and your users.
+While cubes model the raw relationships and logic in your warehouse, views
+reshape that model into business-friendly datasets for easier exploration.
+
+
+
+ Views shield end-users from complex database schemas, table
+ relationships, and raw SQL. Business users can pick fields from
+ a curated dataset in [Explore][ref-explore] or
+ [Workbooks][ref-workbooks] without needing to understand the joins
+ or cube structure underneath.
+
+ For example, an analyst could pick `product`, `total_amount`, and
+ `users_city` from an `orders` view without thinking about the underlying
+ join path from `base_orders` through `line_items` to `products`.
+
+
+
+ [AI agents][ref-ai-context] query your data model through views.
+ By curating which members are included and providing descriptive
+ metadata via `description` and `meta.ai_context`, you control the
+ context AI uses to generate accurate queries. Well-designed views
+ with clear naming and descriptions lead to significantly better
+ AI results.
+
+
+
+ Views give you fine-grained control over what users can see.
+ Each view can be scoped with [access policies][ref-access-policies]
+ to enforce row-level and member-level security. You can also set
+ `public: false` to hide internal views or use
+ [COMPILE_CONTEXT][ref-compile-context] for dynamic visibility
+ based on the security context.
+
+
+
+ In complex data models, the same pair of cubes might be reachable
+ through multiple join paths. Views eliminate this ambiguity by
+ specifying the exact `join_path` for each included cube, ensuring
+ queries always follow the intended path.
+
+
+
+ Views are a natural fit for [embedded analytics][ref-embedding].
+ Different customer tiers can get access to different views,
+ allowing you to tailor the analytics experience to your
+ monetization strategy without duplicating cubes.
+
+
+
+## How views work
+
+Views do **not** define their own members. Instead, they reference cubes by
+specific join paths and selectively include measures, dimensions, and
+segments from those cubes.
+
+
+
+```yaml title="YAML"
+views:
+ - name: orders
+
+ cubes:
+ - join_path: base_orders
+ includes:
+ - status
+ - created_date
+ - total_amount
+ - count
+ - average_order_value
+
+ - join_path: base_orders.line_items.products
+ includes:
+ - name: name
+ alias: product
+
+ - join_path: base_orders.users
+ prefix: true
+ includes: "*"
+ excludes:
+ - company
+```
+
+```javascript title="JavaScript"
+view(`orders`, {
+ cubes: [
+ {
+ join_path: base_orders,
+ includes: [
+ `status`,
+ `created_date`,
+ `total_amount`,
+ `count`,
+ `average_order_value`
+ ]
+ },
+ {
+ join_path: base_orders.line_items.products,
+ includes: [
+ {
+ name: `name`,
+ alias: `product`
+ }
+ ]
+ },
+ {
+ join_path: base_orders.users,
+ prefix: true,
+ includes: `*`,
+ excludes: [`company`]
+ }
+ ]
+})
+```
+
+
+
+In this example, the `orders` view pulls in members from three cubes
+along their join paths. End-users see a flat list of fields — `status`,
+`created_date`, `product`, `users_city`, etc. — without being exposed to
+the underlying cube structure.
+
+## Designing effective views
+
+### Build for your audience
+
+Design views around how your business users think about data, not around
+how your database is structured. Group related fields into views that align
+with departments or use cases — for example, `sales_overview`,
+`customer_360`, or `product_analytics`.
+
+
+
+A single cube can be included in multiple views. For example, a `users`
+cube might appear in both a `customer_360` view and a `sales_overview`
+view, with different fields exposed in each.
+
+
+
+### Favor focused views
+
+Smaller, focused views are easier to navigate and lead to better AI
+results. Rather than one massive view with hundreds of fields, create
+several purpose-built views:
+
+- Views are easier for business users to understand when they're
+ scoped to a specific domain
+- AI agents perform better with focused context
+- Simpler views translate to simpler SQL queries with fewer joins
+
+### Curate with metadata
+
+Help your users understand what a view is for and how to use it:
+
+- Set a clear [`description`][ref-view-description] to explain the
+ view's purpose
+- Use [`title`][ref-view-title] for user-friendly display names
+- Add [`meta.ai_context`][ref-ai-context] to guide AI agents
+- Organize fields into [`folders`][ref-view-folders] for logical
+ grouping
+
+
+
+```yaml title="YAML"
+views:
+ - name: sales_overview
+ description: >
+ Revenue and order metrics for the sales team.
+ Includes order status, product details, and customer segments.
+ meta:
+ ai_context: >
+ Use this view for questions about sales performance,
+ revenue trends, and order analysis. The total_revenue
+ measure includes only completed orders.
+
+ cubes:
+ - join_path: orders
+ includes:
+ - status
+ - total_revenue
+ - count
+ - created_date
+
+ - join_path: orders.customers
+ prefix: true
+ includes:
+ - segment
+ - region
+
+ folders:
+ - name: Order Metrics
+ includes:
+ - total_revenue
+ - count
+ - status
+
+ - name: Customer Info
+ includes:
+ - customers_segment
+ - customers_region
+```
+
+```javascript title="JavaScript"
+view(`sales_overview`, {
+ description: `Revenue and order metrics for the sales team.
+ Includes order status, product details, and customer segments.`,
+ meta: {
+ ai_context: `Use this view for questions about sales performance,
+ revenue trends, and order analysis. The total_revenue
+ measure includes only completed orders.`
+ },
+
+ cubes: [
+ {
+ join_path: orders,
+ includes: [
+ `status`,
+ `total_revenue`,
+ `count`,
+ `created_date`
+ ]
+ },
+ {
+ join_path: orders.customers,
+ prefix: true,
+ includes: [
+ `segment`,
+ `region`
+ ]
+ }
+ ],
+
+ folders: [
+ {
+ name: `Order Metrics`,
+ includes: [
+ `total_revenue`,
+ `count`,
+ `status`
+ ]
+ },
+ {
+ name: `Customer Info`,
+ includes: [
+ `customers_segment`,
+ `customers_region`
+ ]
+ }
+ ]
+})
+```
+
+
+
+### Keep shared logic in cubes
+
+Views are a curation layer. All business logic — SQL definitions, measure
+calculations, join relationships — should live in cubes. Views should only
+control which members are exposed, how they're named, and how they're
+organized. This keeps your model [DRY][wiki-dry] and makes maintenance
+straightforward.
+
+### Control visibility
+
+Not every view should be publicly accessible. Use [`public`][ref-view-public]
+to hide views that are meant for internal use or are still in development:
+
+
+
+```yaml title="YAML"
+views:
+ - name: internal_diagnostics
+ public: false
+
+ cubes:
+ - join_path: system_metrics
+ includes: "*"
+```
+
+```javascript title="JavaScript"
+view(`internal_diagnostics`, {
+ public: false,
+
+ cubes: [
+ {
+ join_path: system_metrics,
+ includes: `*`
+ }
+ ]
+})
+```
+
+
+
+For dynamic visibility based on user roles, use `COMPILE_CONTEXT`:
+
+
+
+```yaml title="YAML"
+views:
+ - name: arr
+ description: Annual Recurring Revenue
+ public: COMPILE_CONTEXT.security_context.is_finance
+
+ cubes:
+ - join_path: revenue
+ includes:
+ - arr
+ - date
+```
+
+```javascript title="JavaScript"
+view(`arr`, {
+ description: `Annual Recurring Revenue`,
+ public: COMPILE_CONTEXT.security_context.is_finance,
+
+ cubes: [
+ {
+ join_path: revenue,
+ includes: [`arr`, `date`]
+ }
+ ]
+})
+```
+
+
+
+## Organizing members with folders
+
+When a view includes many fields, [folders][ref-view-folders] help organize
+them into logical groups. Cube supports both flat and nested folder
+structures:
+
+
+
+```yaml title="YAML"
+views:
+ - name: customers
+
+ cubes:
+ - join_path: users
+ includes: "*"
+
+ - join_path: users.orders
+ prefix: true
+ includes:
+ - status
+ - price
+ - count
+
+ folders:
+ - name: Personal Details
+ includes:
+ - name
+ - gender
+ - created_at
+
+ - name: Order Analytics
+ includes:
+ - orders_status
+ - orders_price
+ - orders_count
+```
+
+```javascript title="JavaScript"
+view(`customers`, {
+ cubes: [
+ {
+ join_path: `users`,
+ includes: `*`
+ },
+ {
+ join_path: `users.orders`,
+ prefix: true,
+ includes: [`status`, `price`, `count`]
+ }
+ ],
+
+ folders: [
+ {
+ name: `Personal Details`,
+ includes: [`name`, `gender`, `created_at`]
+ },
+ {
+ name: `Order Analytics`,
+ includes: [
+ `orders_status`,
+ `orders_price`,
+ `orders_count`
+ ]
+ }
+ ]
+})
+```
+
+
+
+Folders are displayed in supported [visualization tools][ref-viz-tools].
+Check [APIs & Integrations][ref-apis-support] for details on folder
+support. For tools that don't support nested folders, the structure is
+automatically flattened.
+
+## Next steps
+
+- See the [view reference][ref-view-reference] for the full list of
+ parameters
+- Learn about [access policies][ref-access-policies] to govern view access
+- Explore [AI context][ref-ai-context] to improve AI query accuracy
+- Use the [Semantic Model IDE][ref-ide] to develop views interactively
+
+[ref-cubes]: /docs/data-modeling/cubes
+[ref-view-reference]: /reference/data-modeling/view
+[ref-view-description]: /reference/data-modeling/view#description
+[ref-view-title]: /reference/data-modeling/view#title
+[ref-view-public]: /reference/data-modeling/view#public
+[ref-view-folders]: /reference/data-modeling/view#folders
+[ref-access-policies]: /reference/data-modeling/data-access-policies
+[ref-ai-context]: /docs/data-modeling/ai-context
+[ref-compile-context]: /docs/data-modeling/access-control/context
+[ref-explore]: /analytics/explore
+[ref-workbooks]: /analytics/workbooks
+[ref-embedding]: /docs/embedding
+[ref-ide]: /docs/data-modeling/data-model-ide
+[ref-viz-tools]: /admin/connect-to-data/visualization-tools
+[ref-apis-support]: /reference#data-modeling
+[wiki-dry]: https://en.wikipedia.org/wiki/Don%27t_repeat_yourself
diff --git a/docs-mintlify/docs/getting-started/cloud/create-data-model.mdx b/docs-mintlify/docs/getting-started/cloud/create-data-model.mdx
index 59739c097d5b4..1c125c2de57a2 100644
--- a/docs-mintlify/docs/getting-started/cloud/create-data-model.mdx
+++ b/docs-mintlify/docs/getting-started/cloud/create-data-model.mdx
@@ -109,7 +109,7 @@ within the `measures` block.
```yaml
- name: completed_percentage
type: number
- sql: "(100.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
+ sql: "(1.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
format: percent
```
@@ -156,7 +156,7 @@ cubes:
- name: completed_percentage
type: number
- sql: "(100.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
+ sql: "(1.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
format: percent
```
diff --git a/docs-mintlify/docs/integrations/google-sheets.mdx b/docs-mintlify/docs/integrations/google-sheets.mdx
index 9ca9b7c7e858c..c655c22f361ba 100644
--- a/docs-mintlify/docs/integrations/google-sheets.mdx
+++ b/docs-mintlify/docs/integrations/google-sheets.mdx
@@ -122,7 +122,7 @@ in Cube Cloud.
[link-google-sheets]: https://workspace.google.com/products/sheets/
[link-marketplace-listing]: https://workspace.google.com/u/0/marketplace/app/cube_cloud_for_sheets/641460343379
[ref-playground]: /docs/workspace/playground
-[ref-views]: /docs/data-modeling/concepts#views
+[ref-views]: /docs/data-modeling/views
[ref-pre-aggs]: /docs/pre-aggregations/using-pre-aggregations
[ref-sql-api-enabled]: /reference/sql-api#cube-cloud
[ref-saved-reports]: /docs/workspace/saved-reports
\ No newline at end of file
diff --git a/docs-mintlify/docs/integrations/microsoft-excel.mdx b/docs-mintlify/docs/integrations/microsoft-excel.mdx
index 74b606280b751..06d04bed1ec21 100644
--- a/docs-mintlify/docs/integrations/microsoft-excel.mdx
+++ b/docs-mintlify/docs/integrations/microsoft-excel.mdx
@@ -130,7 +130,7 @@ in Cube Cloud.
[ref-excel]: /admin/connect-to-data/visualization-tools/excel
[link-pivottable]: https://support.microsoft.com/en-us/office/create-a-pivottable-to-analyze-worksheet-data-a9a84538-bfe9-40a9-a8e9-f99134456576
[ref-playground]: /docs/workspace/playground
-[ref-views]: /docs/data-modeling/concepts#views
+[ref-views]: /docs/data-modeling/views
[ref-pre-aggs]: /docs/pre-aggregations/using-pre-aggregations
[ref-sql-api-enabled]: /reference/sql-api#cube-cloud
[link-excel-addins]: https://support.microsoft.com/en-us/office/add-or-remove-add-ins-in-excel-0af570c4-5cf3-4fa9-9b88-403625a0b460
diff --git a/docs-mintlify/docs/pre-aggregations/matching-pre-aggregations.mdx b/docs-mintlify/docs/pre-aggregations/matching-pre-aggregations.mdx
index 21aa72aed11d0..10f3f99c03259 100644
--- a/docs-mintlify/docs/pre-aggregations/matching-pre-aggregations.mdx
+++ b/docs-mintlify/docs/pre-aggregations/matching-pre-aggregations.mdx
@@ -131,8 +131,8 @@ configuration option.
[ref-rollup-only-mode]: /docs/pre-aggregations/using-pre-aggregations#rollup-only-mode
[ref-schema-joins-rel]: /reference/data-modeling/joins#relationship
[wiki-gcd]: https://en.wikipedia.org/wiki/Greatest_common_divisor
-[ref-measure-additivity]: /docs/data-modeling/concepts#measure-additivity
-[ref-leaf-measures]: /docs/data-modeling/concepts#leaf-measures
+[ref-measure-additivity]: /reference/data-modeling/measures#type
+[ref-leaf-measures]: /reference/data-modeling/measures#type
[ref-calculated-measures]: /docs/data-modeling/overview#4-using-calculated-measures
[ref-non-strict-date-range-match]: /reference/data-modeling/pre-aggregations#allow_non_strict_date_range_match
[ref-non-additive-recipe]: /recipes/pre-aggregations/non-additivity
@@ -140,4 +140,4 @@ configuration option.
[ref-ungrouped-queries]: /reference/queries#ungrouped-query
[ref-primary-key]: /reference/data-modeling/dimensions#primary_key
[ref-custom-granularity]: /reference/data-modeling/dimensions#granularities
-[ref-views]: /docs/data-modeling/concepts#views
\ No newline at end of file
+[ref-views]: /docs/data-modeling/views
\ No newline at end of file
diff --git a/docs-mintlify/recipes/data-modeling/cohort-retention.mdx b/docs-mintlify/recipes/data-modeling/cohort-retention.mdx
index 4a66106a37678..28cfd4fd63db0 100644
--- a/docs-mintlify/recipes/data-modeling/cohort-retention.mdx
+++ b/docs-mintlify/recipes/data-modeling/cohort-retention.mdx
@@ -139,7 +139,7 @@ cubes:
- users.email
- name: percentage_of_active
- sql: "100.0 * {total_active_count} / NULLIF({total_count}, 0)"
+ sql: "1.0 * {total_active_count} / NULLIF({total_count}, 0)"
type: number
format: percent
drill_members:
@@ -168,7 +168,7 @@ cube(`monthly_retention`, {
},
percentage_of_active: {
- sql: `100.0 * ${total_active_count} / NULLIF(${total_count}, 0)`,
+ sql: `1.0 * ${total_active_count} / NULLIF(${total_count}, 0)`,
type: `number`,
format: `percent`,
drill_members: [
diff --git a/docs-mintlify/recipes/data-modeling/custom-calendar.mdx b/docs-mintlify/recipes/data-modeling/custom-calendar.mdx
index 83feec451415b..a20e18698025c 100644
--- a/docs-mintlify/recipes/data-modeling/custom-calendar.mdx
+++ b/docs-mintlify/recipes/data-modeling/custom-calendar.mdx
@@ -222,5 +222,5 @@ Querying this data modal would yield the following result:
[link-454-official-calendar]: https://2fb5c46100c1b71985e2-011e70369171d43105aff38e48482379.ssl.cf1.rackcdn.com/4-5-4%20calendar/3-Year-Calendar-5-27.pdf
[ref-custom-granularities]: /reference/data-modeling/dimensions#granularities
[ref-custom-granularities-recipe]: /recipes/data-modeling/custom-granularity
-[ref-proxy-dimensions]: /docs/data-modeling/concepts/calculated-members#proxy-dimensions
+[ref-proxy-dimensions]: /docs/data-modeling/dimensions#proxy-dimensions
[ref-jinja-macro]: /docs/data-modeling/dynamic/jinja#macros
\ No newline at end of file
diff --git a/docs-mintlify/recipes/data-modeling/custom-granularity.mdx b/docs-mintlify/recipes/data-modeling/custom-granularity.mdx
index c9a74389e63df..dd633ee76754b 100644
--- a/docs-mintlify/recipes/data-modeling/custom-granularity.mdx
+++ b/docs-mintlify/recipes/data-modeling/custom-granularity.mdx
@@ -162,8 +162,8 @@ Querying this data modal would yield the following result:
[ref-custom-granularities]: /reference/data-modeling/dimensions#granularities
-[ref-default-granularities]: /docs/data-modeling/concepts#time-dimensions
+[ref-default-granularities]: /docs/data-modeling/dimensions#time-dimensions
[wiki-fiscal-year]: https://en.wikipedia.org/wiki/Fiscal_year
[ref-playground]: /docs/workspace/playground
[ref-sql-api]: /reference/sql-api
-[ref-proxy-granularity]: /docs/data-modeling/concepts/calculated-members#time-dimension-granularity
\ No newline at end of file
+[ref-proxy-granularity]: /docs/data-modeling/dimensions#time-dimension-granularity-references
\ No newline at end of file
diff --git a/docs-mintlify/recipes/data-modeling/event-analytics.mdx b/docs-mintlify/recipes/data-modeling/event-analytics.mdx
index 29a9e075b08dd..ba49b209a4311 100644
--- a/docs-mintlify/recipes/data-modeling/event-analytics.mdx
+++ b/docs-mintlify/recipes/data-modeling/event-analytics.mdx
@@ -410,7 +410,7 @@ cube("events", {
To determine the end of the session, we’re going to use a [subquery
-dimension](/docs/data-modeling/concepts/calculated-members#subquery-dimensions).
+dimension](/docs/data-modeling/dimensions#subquery-dimensions).
@@ -739,7 +739,7 @@ cubes:
- - sql: "{is_bounced} = 'True'
- name: bounce_rate
- sql: "100.00 * {bounced_count} / NULLIF({count}, 0)"
+ sql: "1.0 * {bounced_count} / NULLIF({count}, 0)"
type: number
format: percent
```
@@ -770,7 +770,7 @@ cube("sessions", {
},
bounce_rate: {
- sql: `100.00 * ${bounced_count} / NULLIF(${count}, 0)`,
+ sql: `1.0 * ${bounced_count} / NULLIF(${count}, 0)`,
type: `number`,
format: `percent`
}
@@ -846,7 +846,7 @@ cube("sessions", {
repeat_percent: {
description: `Percent of Repeat Sessions`,
- sql: `100.00 * ${repeat_count} / NULLIF(${count}, 0)`,
+ sql: `1.0 * ${repeat_count} / NULLIF(${count}, 0)`,
type: `number`,
format: `percent`
}
@@ -875,7 +875,7 @@ cubes:
- name: repeat_percent
description: Percent of Repeat Sessions
- sql: "100.00 * {repeat_count} / NULLIF({count}, 0)"
+ sql: "1.0 * {repeat_count} / NULLIF({count}, 0)"
type: number
format: percent
diff --git a/docs-mintlify/recipes/data-modeling/filtered-aggregates.mdx b/docs-mintlify/recipes/data-modeling/filtered-aggregates.mdx
index 03953aed8a348..6bb121ae07774 100644
--- a/docs-mintlify/recipes/data-modeling/filtered-aggregates.mdx
+++ b/docs-mintlify/recipes/data-modeling/filtered-aggregates.mdx
@@ -200,4 +200,4 @@ will show the ratio of the sales goal that has been achieved:
-[ref-subquery-dimension]: /docs/data-modeling/concepts/calculated-members#subquery-dimensions
\ No newline at end of file
+[ref-subquery-dimension]: /docs/data-modeling/dimensions#subquery-dimensions
\ No newline at end of file
diff --git a/docs-mintlify/recipes/data-modeling/nested-aggregates.mdx b/docs-mintlify/recipes/data-modeling/nested-aggregates.mdx
index 2d9c1253be9da..9176d64da4797 100644
--- a/docs-mintlify/recipes/data-modeling/nested-aggregates.mdx
+++ b/docs-mintlify/recipes/data-modeling/nested-aggregates.mdx
@@ -146,4 +146,4 @@ We can verify that it's correct by adding one more dimension to the query:
[ref-measures]: /reference/data-modeling/measures
[ref-cube]: /reference/data-modeling/cube
-[ref-subquery-dimension]: /docs/data-modeling/concepts/calculated-members#subquery-dimensions
\ No newline at end of file
+[ref-subquery-dimension]: /docs/data-modeling/dimensions#subquery-dimensions
\ No newline at end of file
diff --git a/docs-mintlify/recipes/data-modeling/period-over-period.mdx b/docs-mintlify/recipes/data-modeling/period-over-period.mdx
index 7e0178f5219bb..56d77893b80d5 100644
--- a/docs-mintlify/recipes/data-modeling/period-over-period.mdx
+++ b/docs-mintlify/recipes/data-modeling/period-over-period.mdx
@@ -148,8 +148,8 @@ Here's the result:
-[ref-multi-stage]: /docs/data-modeling/concepts/multi-stage-calculations
+[ref-multi-stage]: /docs/data-modeling/measures#multi-stage-measures
[ref-calculated-measure]: /docs/data-modeling/overview#4-using-calculated-measures
[ref-time-dimension-granularity]: /reference/rest-api/query-format#time-dimensions-format
[link-tesseract]: https://cube.dev/blog/introducing-next-generation-data-modeling-engine
-[link-time-shift]: /docs/data-modeling/concepts/multi-stage-calculations#time-shift
\ No newline at end of file
+[link-time-shift]: /docs/data-modeling/measures#time-shift
\ No newline at end of file
diff --git a/docs-mintlify/docs/data-modeling/concepts/polymorphic-cubes.mdx b/docs-mintlify/recipes/data-modeling/polymorphic-cubes.mdx
similarity index 97%
rename from docs-mintlify/docs/data-modeling/concepts/polymorphic-cubes.mdx
rename to docs-mintlify/recipes/data-modeling/polymorphic-cubes.mdx
index 594212cb70bce..70c20a8af7e16 100644
--- a/docs-mintlify/docs/data-modeling/concepts/polymorphic-cubes.mdx
+++ b/docs-mintlify/recipes/data-modeling/polymorphic-cubes.mdx
@@ -166,5 +166,5 @@ cube(`lessons`, {
-[ref-schema-advanced-extend]: /docs/data-modeling/concepts/code-reusability-extending-cubes
+[ref-schema-advanced-extend]: /docs/data-modeling/extending-cubes
[ref-schema-ref-cubes-extends]: /reference/data-modeling/cube#extends
\ No newline at end of file
diff --git a/docs-mintlify/recipes/data-modeling/using-dynamic-measures.mdx b/docs-mintlify/recipes/data-modeling/using-dynamic-measures.mdx
index 75ed985dd8399..eb03f8404d149 100644
--- a/docs-mintlify/recipes/data-modeling/using-dynamic-measures.mdx
+++ b/docs-mintlify/recipes/data-modeling/using-dynamic-measures.mdx
@@ -41,7 +41,7 @@ const createPercentageMeasure = (status) => ({
sql: (CUBE) =>
`ROUND(${CUBE[`total_${status}_orders`]}::NUMERIC / ${
CUBE.total_orders
- }::NUMERIC * 100.0, 2)`
+ }::NUMERIC, 2)`
}
})
@@ -90,4 +90,4 @@ or run it with the `docker-compose up` command. You'll see the result, including
queried data, in the console.
-[ref-measures]: /docs/data-modeling/concepts#measures
\ No newline at end of file
+[ref-measures]: /docs/data-modeling/measures
\ No newline at end of file
diff --git a/docs-mintlify/recipes/data-modeling/xirr.mdx b/docs-mintlify/recipes/data-modeling/xirr.mdx
index 4528a7487e4be..40b25f9364cb8 100644
--- a/docs-mintlify/recipes/data-modeling/xirr.mdx
+++ b/docs-mintlify/recipes/data-modeling/xirr.mdx
@@ -199,4 +199,4 @@ All queries above would yield the same result:
[ref-query-wpp]: /reference/queries#query-with-post-processing
[ref-query-regular]: /reference/queries#regular-query
[link-tesseract]: https://cube.dev/blog/introducing-next-generation-data-modeling-engine
-[ref-multi-stage-calculations]: /docs/data-modeling/concepts/multi-stage-calculations
\ No newline at end of file
+[ref-multi-stage-calculations]: /docs/data-modeling/measures#multi-stage-measures
\ No newline at end of file
diff --git a/docs-mintlify/recipes/pre-aggregations/non-additivity.mdx b/docs-mintlify/recipes/pre-aggregations/non-additivity.mdx
index 2e475b603f557..a0fcf1920b14e 100644
--- a/docs-mintlify/recipes/pre-aggregations/non-additivity.mdx
+++ b/docs-mintlify/recipes/pre-aggregations/non-additivity.mdx
@@ -248,4 +248,4 @@ queried data, in the console.
[ref-percentile-recipe]: /recipes/data-modeling/percentiles
-[ref-calculated-measures]: /docs/data-modeling/concepts/calculated-members#calculated-measures
\ No newline at end of file
+[ref-calculated-measures]: /docs/data-modeling/measures#calculated-measures
\ No newline at end of file
diff --git a/docs-mintlify/reference/configuration/environment-variables.mdx b/docs-mintlify/reference/configuration/environment-variables.mdx
index 89224526bdb50..929a8a2cdb2ad 100644
--- a/docs-mintlify/reference/configuration/environment-variables.mdx
+++ b/docs-mintlify/reference/configuration/environment-variables.mdx
@@ -1898,7 +1898,7 @@ The port for a Cube deployment to listen to API connections on.
[mysql-server-tz-support]: https://dev.mysql.com/doc/refman/8.4/en/time-zone-support.html
[ref-schema-ref-preagg-allownonstrict]: /reference/data-modeling/pre-aggregations#allow_non_strict_date_range_match
[link-tesseract]: https://cube.dev/blog/introducing-next-generation-data-modeling-engine
-[ref-multi-stage-calculations]: /docs/data-modeling/concepts/multi-stage-calculations
+[ref-multi-stage-calculations]: /docs/data-modeling/measures#multi-stage-measures
[ref-folders]: /reference/data-modeling/view#folders
[ref-dataviz-tools]: /admin/connect-to-data/visualization-tools
[ref-context-to-app-id]: /reference/configuration/config#context_to_app_id
diff --git a/docs-mintlify/reference/core-data-apis/dax-api/index.mdx b/docs-mintlify/reference/core-data-apis/dax-api/index.mdx
index 24488b81ab11d..ea7f385ccb72c 100644
--- a/docs-mintlify/reference/core-data-apis/dax-api/index.mdx
+++ b/docs-mintlify/reference/core-data-apis/dax-api/index.mdx
@@ -78,8 +78,8 @@ The DAX API only exposes [views][ref-views], not cubes.
[link-dax]: https://learn.microsoft.com/en-us/dax/
[ref-sql-api]: /reference/sql-api
[ref-ref-dax-api]: /reference/dax-api/reference
-[ref-views]: /docs/data-modeling/concepts#views
-[ref-time-dimensions]: /docs/data-modeling/concepts#time-dimensions
+[ref-views]: /docs/data-modeling/views
+[ref-time-dimensions]: /docs/data-modeling/dimensions#time-dimensions
[ref-kerberos]: /docs/integrations/power-bi/kerberos
[ref-ntlm]: /docs/integrations/power-bi/ntlm
[ref-power-bi]: /admin/connect-to-data/visualization-tools/powerbi
\ No newline at end of file
diff --git a/docs-mintlify/reference/core-data-apis/mdx-api.mdx b/docs-mintlify/reference/core-data-apis/mdx-api.mdx
index 1920c2dcf04e1..644aae2934ede 100644
--- a/docs-mintlify/reference/core-data-apis/mdx-api.mdx
+++ b/docs-mintlify/reference/core-data-apis/mdx-api.mdx
@@ -226,7 +226,7 @@ Authentication and authorization work the same as for the [SQL API](/reference/s
[ref-cube-cloud-for-excel]: /docs/integrations/microsoft-excel
[ref-hierarchies]: /reference/data-modeling/hierarchies
[ref-folders]: /reference/data-modeling/view#folders
-[ref-views]: /docs/data-modeling/concepts#views
+[ref-views]: /docs/data-modeling/views
[ref-deployment]: /docs/deployment/cloud/deployments
[ref-pre-aggregations]: /docs/pre-aggregations/using-pre-aggregations
[ref-rollup-only-mode]: /docs/pre-aggregations/using-pre-aggregations#rollup-only-mode
diff --git a/docs-mintlify/reference/core-data-apis/rest-api/query-format.mdx b/docs-mintlify/reference/core-data-apis/rest-api/query-format.mdx
index 9d8e7520e66b8..652b51811b6a1 100644
--- a/docs-mintlify/reference/core-data-apis/rest-api/query-format.mdx
+++ b/docs-mintlify/reference/core-data-apis/rest-api/query-format.mdx
@@ -687,7 +687,7 @@ refer to its documentation for more examples.
[ref-total-query]: /reference/queries#total-query
[ref-ungrouped-query]: /reference/queries#ungrouped-query
[ref-default-order]: /reference/queries#order
-[ref-default-granularities]: /docs/data-modeling/concepts#time-dimensions
+[ref-default-granularities]: /docs/data-modeling/dimensions#time-dimensions
[ref-custom-granularities]: /reference/data-modeling/dimensions#granularities
[wiki-iso-8601]: https://en.wikipedia.org/wiki/ISO_8601
-[ref-join-hints]: /docs/data-modeling/concepts/working-with-joins#join-hints
\ No newline at end of file
+[ref-join-hints]: /docs/data-modeling/joins#join-hints
\ No newline at end of file
diff --git a/docs-mintlify/reference/core-data-apis/sql-api/joins.mdx b/docs-mintlify/reference/core-data-apis/sql-api/joins.mdx
index 3fa946a648cc5..0b25778f14b3a 100644
--- a/docs-mintlify/reference/core-data-apis/sql-api/joins.mdx
+++ b/docs-mintlify/reference/core-data-apis/sql-api/joins.mdx
@@ -208,6 +208,6 @@ Please note that, even if `product_description` is in the inner selection, it is
evaluated in the final query as it isn't used in any way.
-[ref-views]: /docs/data-modeling/concepts#views
-[ref-join-paths]: /docs/data-modeling/concepts/working-with-joins#join-paths
-[ref-join-hints]: /docs/data-modeling/concepts/working-with-joins#join-hints
\ No newline at end of file
+[ref-views]: /docs/data-modeling/views
+[ref-join-paths]: /docs/data-modeling/joins#join-paths
+[ref-join-hints]: /docs/data-modeling/joins#join-hints
\ No newline at end of file
diff --git a/docs-mintlify/reference/core-data-apis/sql-api/query-format.mdx b/docs-mintlify/reference/core-data-apis/sql-api/query-format.mdx
index 4ffb6d7cc23e6..6dc2a5ab976c2 100644
--- a/docs-mintlify/reference/core-data-apis/sql-api/query-format.mdx
+++ b/docs-mintlify/reference/core-data-apis/sql-api/query-format.mdx
@@ -256,7 +256,7 @@ cubes:
- name: completed_percentage
type: number
- sql: "(100.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
+ sql: "(1.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
format: percent
```
diff --git a/docs-mintlify/reference/data-modeling/cube.mdx b/docs-mintlify/reference/data-modeling/cube.mdx
index af1c2a3f7a370..3f0ffa1c0031c 100644
--- a/docs-mintlify/reference/data-modeling/cube.mdx
+++ b/docs-mintlify/reference/data-modeling/cube.mdx
@@ -670,9 +670,9 @@ The `access_policy` parameter is used to configure [access policies][ref-ref-dap
[ref-ref-pre-aggs]: /reference/data-modeling/pre-aggregations
[ref-ref-dap]: /reference/data-modeling/data-access-policies
[ref-syntax-cube-sql]: /docs/data-modeling/syntax#cubesql-function
-[ref-extension]: /docs/data-modeling/concepts/code-reusability-extending-cubes
+[ref-extension]: /docs/data-modeling/extending-cubes
[ref-calendar-cubes]: /docs/data-modeling/concepts/calendar-cubes
[ref-calendar-cubes-time-shifts]: /docs/data-modeling/concepts/calendar-cubes#time-shifts
[ref-calendar-cubes-granularities]: /docs/data-modeling/concepts/calendar-cubes#granularities
-[ref-time-dimensions]: /docs/data-modeling/concepts#time-dimensions
-[ref-time-shift]: /docs/data-modeling/concepts/multi-stage-calculations#time-shift
\ No newline at end of file
+[ref-time-dimensions]: /docs/data-modeling/dimensions#time-dimensions
+[ref-time-shift]: /docs/data-modeling/measures#time-shift
\ No newline at end of file
diff --git a/docs-mintlify/reference/data-modeling/dimensions.mdx b/docs-mintlify/reference/data-modeling/dimensions.mdx
index a9fa7e5437538..5055845827ec3 100644
--- a/docs-mintlify/reference/data-modeling/dimensions.mdx
+++ b/docs-mintlify/reference/data-modeling/dimensions.mdx
@@ -1007,6 +1007,7 @@ cube(`orders`, {
+{/*
#### Calendar cubes
When the `granularities` parameter is used in time dimensions within [calendar
@@ -1091,6 +1092,7 @@ cube(`fiscal_calendar`, {
```
+*/}
### `time_shift`
@@ -1198,7 +1200,7 @@ cube(`fiscal_calendar`, {
[ref-ai-context]: /docs/data-modeling/ai-context
[ref-ref-cubes]: /reference/data-modeling/cube
[ref-schema-ref-joins]: /reference/data-modeling/joins
-[ref-subquery]: /docs/data-modeling/concepts/calculated-members#subquery-dimensions
+[ref-subquery]: /docs/data-modeling/dimensions#subquery-dimensions
[self-subquery]: #sub-query
[ref-naming]: /docs/data-modeling/syntax#naming
[ref-playground]: /docs/workspace/playground
@@ -1209,7 +1211,7 @@ cube(`fiscal_calendar`, {
[ref-ref-hierarchies]: /reference/data-modeling/hierarchies
[ref-data-sources]: /admin/connect-to-data/data-sources
[ref-calendar-cubes]: /docs/data-modeling/concepts/calendar-cubes
-[ref-time-shift]: /docs/data-modeling/concepts/multi-stage-calculations#time-shift
+[ref-time-shift]: /docs/data-modeling/measures#time-shift
[ref-cube-calendar]: /reference/data-modeling/cube#calendar
[ref-measure-time-shift]: /reference/data-modeling/measures#time_shift
[ref-data-masking]: /docs/data-modeling/access-control/data-access-policies#data-masking
diff --git a/docs-mintlify/reference/data-modeling/joins.mdx b/docs-mintlify/reference/data-modeling/joins.mdx
index 0931b6bd053ba..c2fba4bff3832 100644
--- a/docs-mintlify/reference/data-modeling/joins.mdx
+++ b/docs-mintlify/reference/data-modeling/joins.mdx
@@ -663,7 +663,7 @@ Please use views to address join predictability and stability.
[ref-ref-cubes]: /reference/data-modeling/cube
[ref-restapi-query-filter-op-set]: /reference/rest-api/query-format#set
-[ref-schema-fundamentals-join-dir]: /docs/data-modeling/concepts/working-with-joins#direction-of-joins
+[ref-schema-fundamentals-join-dir]: /docs/data-modeling/joins#direction-of-joins
[ref-schema-cube-sql]: /reference/data-modeling/cube#sql
[ref-schema-data-blenging]: /docs/data-modeling/concepts/data-blending#data-blending
[ref-naming]: /docs/data-modeling/syntax#naming
diff --git a/docs-mintlify/reference/data-modeling/measures.mdx b/docs-mintlify/reference/data-modeling/measures.mdx
index 5fb809ad35563..8c78673af880b 100644
--- a/docs-mintlify/reference/data-modeling/measures.mdx
+++ b/docs-mintlify/reference/data-modeling/measures.mdx
@@ -1429,15 +1429,15 @@ cube(`orders`, {
[ref-naming]: /docs/data-modeling/syntax#naming
[ref-playground]: /docs/workspace/playground
[ref-apis]: /reference
-[ref-rolling-window]: /docs/data-modeling/concepts/multi-stage-calculations#rolling-window
+[ref-rolling-window]: /docs/data-modeling/measures#rolling-windows
[link-tesseract]: https://cube.dev/blog/introducing-next-generation-data-modeling-engine
-[ref-multi-stage]: /docs/data-modeling/concepts/multi-stage-calculations
-[ref-time-shift]: /docs/data-modeling/concepts/multi-stage-calculations#time-shift
-[ref-nested-aggregate]: /docs/data-modeling/concepts/multi-stage-calculations#nested-aggregate
+[ref-multi-stage]: /docs/data-modeling/measures#multi-stage-measures
+[ref-time-shift]: /docs/data-modeling/measures#time-shift
+[ref-nested-aggregate]: /docs/data-modeling/measures#nested-aggregates
[ref-calendar-cubes]: /docs/data-modeling/concepts/calendar-cubes
[ref-switch-dimensions]: /reference/data-modeling/dimensions#type
[ref-data-masking]: /docs/data-modeling/access-control/data-access-policies#data-masking
[link-d3-format]: https://d3js.org/d3-format
[link-iso-4217]: https://en.wikipedia.org/wiki/ISO_4217
-[ref-calculated-measures]: /docs/data-modeling/concepts/calculated-members#calculated-measures
+[ref-calculated-measures]: /docs/data-modeling/measures#calculated-measures
[ref-schema-ref-preaggs-rollup]: /reference/data-modeling/pre-aggregations#rollup
\ No newline at end of file
diff --git a/docs-mintlify/reference/data-modeling/view.mdx b/docs-mintlify/reference/data-modeling/view.mdx
index fe8efb651c984..bc163c6b94f58 100644
--- a/docs-mintlify/reference/data-modeling/view.mdx
+++ b/docs-mintlify/reference/data-modeling/view.mdx
@@ -660,7 +660,7 @@ The `access_policy` parameter is used to configure [access policies][ref-ref-dap
[ref-apis-support]: /reference#data-modeling
[ref-playground]: /docs/workspace/playground#viewing-the-data-model
[ref-viz-tools]: /admin/connect-to-data/visualization-tools
-[ref-extension]: /docs/data-modeling/concepts/code-reusability-extending-cubes
+[ref-extension]: /docs/data-modeling/extending-cubes
[ref-dim-name]: /reference/data-modeling/dimensions#name
[ref-dim-title]: /reference/data-modeling/dimensions#title
[ref-dim-description]: /reference/data-modeling/dimensions#description
diff --git a/docs/content/product/apis-integrations/core-data-apis/sql-api/query-format.mdx b/docs/content/product/apis-integrations/core-data-apis/sql-api/query-format.mdx
index e0549e94196b3..bb77c7cfbf373 100644
--- a/docs/content/product/apis-integrations/core-data-apis/sql-api/query-format.mdx
+++ b/docs/content/product/apis-integrations/core-data-apis/sql-api/query-format.mdx
@@ -256,7 +256,7 @@ cubes:
- name: completed_percentage
type: number
- sql: "(100.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
+ sql: "(1.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
format: percent
```
diff --git a/docs/content/product/data-modeling/concepts/calculated-members.mdx b/docs/content/product/data-modeling/concepts/calculated-members.mdx
index 9c4c71eb729fd..071557ef3ec79 100644
--- a/docs/content/product/data-modeling/concepts/calculated-members.mdx
+++ b/docs/content/product/data-modeling/concepts/calculated-members.mdx
@@ -158,7 +158,7 @@ cube(`users`, {
},
purchases_to_users_ratio: {
- sql: `100.0 * ${orders.purchases} / ${CUBE.count}`,
+ sql: `1.0 * ${orders.purchases} / ${CUBE.count}`,
type: `number`,
format: `percent`
}
diff --git a/docs/content/product/data-modeling/overview.mdx b/docs/content/product/data-modeling/overview.mdx
index bf9ac86d5e32a..d8a091e313cb0 100644
--- a/docs/content/product/data-modeling/overview.mdx
+++ b/docs/content/product/data-modeling/overview.mdx
@@ -283,7 +283,7 @@ measure via an API, the following SQL will be generated:
```sql
SELECT
- 100.0 * COUNT(
+ 1.0 * COUNT(
CASE WHEN (users.paying = 'true') THEN users.id END
) / COUNT(users.id) AS paying_percentage
FROM users
diff --git a/docs/content/product/data-modeling/recipes/cohort-retention.mdx b/docs/content/product/data-modeling/recipes/cohort-retention.mdx
index d298ba8ad9fe6..01f4b9279b770 100644
--- a/docs/content/product/data-modeling/recipes/cohort-retention.mdx
+++ b/docs/content/product/data-modeling/recipes/cohort-retention.mdx
@@ -139,7 +139,7 @@ cubes:
- users.email
- name: percentage_of_active
- sql: "100.0 * {total_active_count} / NULLIF({total_count}, 0)"
+ sql: "1.0 * {total_active_count} / NULLIF({total_count}, 0)"
type: number
format: percent
drill_members:
@@ -168,7 +168,7 @@ cube(`monthly_retention`, {
},
percentage_of_active: {
- sql: `100.0 * ${total_active_count} / NULLIF(${total_count}, 0)`,
+ sql: `1.0 * ${total_active_count} / NULLIF(${total_count}, 0)`,
type: `number`,
format: `percent`,
drill_members: [
diff --git a/docs/content/product/data-modeling/recipes/event-analytics.mdx b/docs/content/product/data-modeling/recipes/event-analytics.mdx
index e047accf8136d..9f2f5cf8745aa 100644
--- a/docs/content/product/data-modeling/recipes/event-analytics.mdx
+++ b/docs/content/product/data-modeling/recipes/event-analytics.mdx
@@ -742,7 +742,7 @@ cube("sessions", {
},
bounce_rate: {
- sql: `100.00 * ${bounced_count} / NULLIF(${count}, 0)`,
+ sql: `1.0 * ${bounced_count} / NULLIF(${count}, 0)`,
type: `number`,
format: `percent`
}
@@ -770,7 +770,7 @@ cubes:
- - sql: "{is_bounced} = 'True'
- name: bounce_rate
- sql: "100.00 * {bounced_count} / NULLIF({count}, 0)"
+ sql: "1.0 * {bounced_count} / NULLIF({count}, 0)"
type: number
format: percent
```
@@ -843,7 +843,7 @@ cube("sessions", {
repeat_percent: {
description: `Percent of Repeat Sessions`,
- sql: `100.00 * ${repeat_count} / NULLIF(${count}, 0)`,
+ sql: `1.0 * ${repeat_count} / NULLIF(${count}, 0)`,
type: `number`,
format: `percent`
}
@@ -872,7 +872,7 @@ cubes:
- name: repeat_percent
description: Percent of Repeat Sessions
- sql: "100.00 * {repeat_count} / NULLIF({count}, 0)"
+ sql: "1.0 * {repeat_count} / NULLIF({count}, 0)"
type: number
format: percent
diff --git a/docs/content/product/data-modeling/recipes/using-dynamic-measures.mdx b/docs/content/product/data-modeling/recipes/using-dynamic-measures.mdx
index a4e4c307857dd..5e3237d20d016 100644
--- a/docs/content/product/data-modeling/recipes/using-dynamic-measures.mdx
+++ b/docs/content/product/data-modeling/recipes/using-dynamic-measures.mdx
@@ -38,7 +38,7 @@ const createPercentageMeasure = (status) => ({
sql: (CUBE) =>
`ROUND(${CUBE[`total_${status}_orders`]}::NUMERIC / ${
CUBE.total_orders
- }::NUMERIC * 100.0, 2)`
+ }::NUMERIC, 2)`
}
})
diff --git a/docs/content/product/getting-started/cloud/create-data-model.mdx b/docs/content/product/getting-started/cloud/create-data-model.mdx
index c591c8b988826..79793dd372823 100644
--- a/docs/content/product/getting-started/cloud/create-data-model.mdx
+++ b/docs/content/product/getting-started/cloud/create-data-model.mdx
@@ -107,7 +107,7 @@ within the `measures` block.
```yaml
- name: completed_percentage
type: number
- sql: "(100.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
+ sql: "(1.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
format: percent
```
@@ -154,7 +154,7 @@ cubes:
- name: completed_percentage
type: number
- sql: "(100.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
+ sql: "(1.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
format: percent
```
diff --git a/examples/recipes/active-users/schema/ActiveUsers.js b/examples/recipes/active-users/schema/ActiveUsers.js
index 2e87fc5d4a6e6..b455206fb0c1d 100644
--- a/examples/recipes/active-users/schema/ActiveUsers.js
+++ b/examples/recipes/active-users/schema/ActiveUsers.js
@@ -31,7 +31,7 @@ cube(`ActiveUsers`, {
wauToMau: {
title: `WAU to MAU`,
- sql: `100.000 * ${weeklyActiveUsers} / NULLIF(${monthlyActiveUsers}, 0)`,
+ sql: `1.0 * ${weeklyActiveUsers} / NULLIF(${monthlyActiveUsers}, 0)`,
type: `number`,
format: `percent`,
},
diff --git a/examples/recipes/referencing-dynamic-measures/schema/Orders.js b/examples/recipes/referencing-dynamic-measures/schema/Orders.js
index 56363fe9208e8..dc960ca1b39f2 100644
--- a/examples/recipes/referencing-dynamic-measures/schema/Orders.js
+++ b/examples/recipes/referencing-dynamic-measures/schema/Orders.js
@@ -22,7 +22,7 @@ const createPercentageMeasure = (status) => ({
format: `percent`,
title: `Percentage of ${status} orders`,
sql: (CUBE) =>
- `ROUND(${CUBE[`Total_${status}_orders`]}::numeric / ${CUBE.totalOrders}::numeric * 100.0, 2)`,
+ `ROUND(${CUBE[`Total_${status}_orders`]}::numeric / ${CUBE.totalOrders}::numeric, 2)`,
},
});
diff --git a/packages/cubejs-schema-compiler/src/extensions/Funnels.ts b/packages/cubejs-schema-compiler/src/extensions/Funnels.ts
index d5a8d5bce714b..b24861ef9d12e 100644
--- a/packages/cubejs-schema-compiler/src/extensions/Funnels.ts
+++ b/packages/cubejs-schema-compiler/src/extensions/Funnels.ts
@@ -45,7 +45,7 @@ ${eventJoin.join('\nLEFT JOIN\n')}
shown: false
},
conversionsPercent: {
- sql: (conversions, firstStepConversions) => `CASE WHEN ${firstStepConversions} > 0 THEN 100.0 * ${conversions} / ${firstStepConversions} ELSE NULL END`,
+ sql: (conversions, firstStepConversions) => `CASE WHEN ${firstStepConversions} > 0 THEN 1.0 * ${conversions} / ${firstStepConversions} ELSE NULL END`,
type: 'number',
format: 'percent'
}
diff --git a/packages/cubejs-schema-compiler/test/unit/fixtures/calendar_orders.yml b/packages/cubejs-schema-compiler/test/unit/fixtures/calendar_orders.yml
index c0ffd1e03c45f..6710462892c44 100644
--- a/packages/cubejs-schema-compiler/test/unit/fixtures/calendar_orders.yml
+++ b/packages/cubejs-schema-compiler/test/unit/fixtures/calendar_orders.yml
@@ -59,7 +59,7 @@ cubes:
- sql: "{CUBE}.status = 'completed'"
- name: completed_percentage
- sql: "({completed_count} / NULLIF({count}, 0)) * 100.0"
+ sql: "1.0 * {completed_count} / NULLIF({count}, 0)"
type: number
format: percent
-
-
-
-[ref-schema-ref-view]: /reference/data-modeling/view
-[ref-schema-ref-joins-relationship]: /reference/data-modeling/joins#relationship
-[ref-visual-model]: /docs/data-modeling/visual-modeler
-[ref-cube]: /reference/data-modeling/cube
-[ref-cube-public]: /reference/data-modeling/cube#public
-[ref-rest-meta]: /reference/rest-api/reference#base_pathv1meta
-[ref-preaggs]: /docs/data-modeling/concepts#pre-aggregations
-[ref-primary-key]: /reference/data-modeling/dimensions#primary_key
-[ref-data-model]: /docs/data-modeling/concepts
-[ref-queries]: /reference/queries
-[ref-references]: /docs/data-modeling/syntax#cubecolumn-cubemember
-[ref-calculated-members]: /docs/data-modeling/concepts/calculated-members
-[ref-views]: /docs/data-modeling/concepts#views
-[ref-view-join-path]: /reference/data-modeling/view#join_path
-[ref-preaggs]: /docs/data-modeling/concepts#pre-aggregations
-[ref-rest-api]: /reference/rest-api
-[ref-sql-api]: /reference/sql-api
-[ref-sql-api-joins]: /reference/sql-api/joins
-[ref-rest-api-join-hints]: /reference/rest-api/query-format#query-properties
\ No newline at end of file
diff --git a/docs-mintlify/docs/data-modeling/cubes.mdx b/docs-mintlify/docs/data-modeling/cubes.mdx
new file mode 100644
index 0000000000000..45bc867e87835
--- /dev/null
+++ b/docs-mintlify/docs/data-modeling/cubes.mdx
@@ -0,0 +1,395 @@
+---
+title: Cubes
+description: Cubes represent the tables in your database. Each cube maps to a table or query in your data source and contains measures, dimensions, joins, and pre-aggregations.
+---
+
+Cubes represent the tables in your database. Each cube maps to a single
+table in your [data source][ref-data-sources] and contains the business
+logic — [measures][ref-measures], [dimensions][ref-dimensions],
+[joins][ref-joins], and [pre-aggregations][ref-pre-aggs] — that defines
+how that data can be queried.
+
+
+
+See the [cube reference][ref-cube-reference] for the full list of
+parameters and configuration options.
+
+
+
+## Defining a cube
+
+A cube points to a table in your data source using `sql_table`:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`
+})
+```
+
+
+
+You can also use the `sql` property for more complex queries:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql: |
+ SELECT *
+ FROM orders, line_items
+ WHERE orders.id = line_items.order_id
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql: `
+ SELECT *
+ FROM orders, line_items
+ WHERE orders.id = line_items.order_id
+ `
+})
+```
+
+
+
+
+
+If you're using dbt, see [this recipe][ref-cube-with-dbt] to streamline
+defining cubes on top of dbt models.
+
+
+
+## Cube members
+
+Each cube contains definitions for its members: dimensions, measures,
+and segments.
+
+### Dimensions
+
+[Dimensions][ref-dimensions] represent the properties of a single data
+point — the attributes you group by and filter on, such as `status`,
+`city`, or `created_at`:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: status
+ sql: status
+ type: string
+
+ - name: created_at
+ sql: created_at
+ type: time
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`,
+
+ dimensions: {
+ id: {
+ sql: `id`,
+ type: `number`,
+ primary_key: true
+ },
+
+ status: {
+ sql: `status`,
+ type: `string`
+ },
+
+ created_at: {
+ sql: `created_at`,
+ type: `time`
+ }
+ }
+})
+```
+
+
+
+Time dimensions enable grouping by granularity (year, quarter, month,
+week, day, hour, minute, second) and are essential for
+[partitioned pre-aggregations][ref-partition-preaggs].
+
+### Measures
+
+[Measures][ref-measures] represent aggregated values over a set of data
+points — counts, sums, averages, and custom calculations:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ # ...
+
+ measures:
+ - name: count
+ type: count
+
+ - name: total_amount
+ sql: amount
+ type: sum
+
+ - name: average_amount
+ sql: amount
+ type: avg
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ // ...
+
+ measures: {
+ count: {
+ type: `count`
+ },
+
+ total_amount: {
+ sql: `amount`,
+ type: `sum`
+ },
+
+ average_amount: {
+ sql: `amount`,
+ type: `avg`
+ }
+ }
+})
+```
+
+
+
+Measures can reference other measures to create
+[calculated measures][ref-calculated-measures], and you can apply
+[filters][ref-measure-filters] to create filtered aggregations like
+"count of completed orders."
+
+### Segments
+
+[Segments][ref-segments] are predefined filters on a cube. They allow
+you to define commonly used filter logic once and reuse it across
+queries:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ # ...
+
+ segments:
+ - name: completed
+ sql: "{CUBE}.status = 'completed'"
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ // ...
+
+ segments: {
+ completed: {
+ sql: `${CUBE}.status = 'completed'`
+ }
+ }
+})
+```
+
+
+
+## Joins
+
+[Joins][ref-joins] define relationships between cubes, forming the data
+graph that Cube uses to generate multi-table SQL queries:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+
+ joins:
+ - name: users
+ relationship: many_to_one
+ sql: "{CUBE}.user_id = {users.id}"
+
+ - name: line_items
+ relationship: one_to_many
+ sql: "{CUBE}.id = {line_items.order_id}"
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`,
+
+ joins: {
+ users: {
+ relationship: `many_to_one`,
+ sql: `${CUBE}.user_id = ${users.id}`
+ },
+
+ line_items: {
+ relationship: `one_to_many`,
+ sql: `${CUBE}.id = ${line_items.order_id}`
+ }
+ }
+})
+```
+
+
+
+Cube supports `one_to_one`, `many_to_one`, and `one_to_many` relationship
+types. See [working with joins][ref-working-with-joins] for advanced
+patterns like cross-database joins and join direction control.
+
+## Pre-aggregations
+
+[Pre-aggregations][ref-pre-aggs] are materialized summaries of cube data
+that dramatically speed up query execution. Cube automatically matches
+incoming queries to the best available pre-aggregation:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ # ...
+
+ pre_aggregations:
+ - name: main
+ measures:
+ - count
+ - total_amount
+ dimensions:
+ - status
+ time_dimension: created_at
+ granularity: day
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ // ...
+
+ pre_aggregations: {
+ main: {
+ measures: [count, total_amount],
+ dimensions: [status],
+ time_dimension: created_at,
+ granularity: `day`
+ }
+ }
+})
+```
+
+
+
+Pre-aggregations support [partitioning][ref-partition-preaggs] by time
+and [incremental refreshes][ref-incremental-preaggs] to keep materialized
+data up-to-date efficiently.
+
+## Designing effective cubes
+
+### One cube per entity
+
+Map each cube to a single business entity — `orders`, `users`,
+`products`, `line_items`. Use [joins](#joins) to connect them rather than
+creating wide cubes with data from multiple tables.
+
+### Keep naming consistent
+
+Use clear, consistent naming for members. Dimensions should describe
+attributes (`status`, `city`, `created_at`), and measures should describe
+aggregations (`count`, `total_revenue`, `average_order_value`). Add
+[`description`][ref-cube-description] and [`title`][ref-cube-title] for
+user-friendly display.
+
+### Control visibility
+
+Use [`public`][ref-cube-public] to hide cubes that should not be
+directly queried by end-users. In most data models, cubes are internal
+building blocks and [views][ref-views] are the public interface:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: base_orders
+ public: false
+ sql_table: orders
+
+ # ...
+```
+
+```javascript title="JavaScript"
+cube(`base_orders`, {
+ public: false,
+ sql_table: `orders`,
+
+ // ...
+})
+```
+
+
+
+### Scale with extension and polymorphism
+
+When cubes share common members, use [`extends`][ref-extending-cubes] to
+avoid duplication. For data models with many similar entities,
+[polymorphic cubes][ref-polymorphic-cubes] let you define a base cube
+and specialize it per entity.
+
+## Next steps
+
+- See the [cube reference][ref-cube-reference] for the full list of
+ parameters
+- Learn about [views][ref-views] to expose cubes to end-users
+- Explore [calculated measures][ref-calculated-measures] for derived metrics
+- Use the [Semantic Model IDE][ref-ide] to develop cubes interactively
+
+[wiki-view-sql]: https://en.wikipedia.org/wiki/View_(SQL)
+[ref-data-sources]: /admin/connect-to-data
+[ref-cube-reference]: /reference/data-modeling/cube
+[ref-cube-description]: /reference/data-modeling/cube#description
+[ref-cube-title]: /reference/data-modeling/cube#title
+[ref-cube-public]: /reference/data-modeling/cube#public
+[ref-measures]: /reference/data-modeling/measures
+[ref-dimensions]: /reference/data-modeling/dimensions
+[ref-segments]: /reference/data-modeling/segments
+[ref-joins]: /reference/data-modeling/joins
+[ref-pre-aggs]: /reference/data-modeling/pre-aggregations
+[ref-views]: /docs/data-modeling/views
+[ref-extending-cubes]: /docs/data-modeling/extending-cubes
+[ref-polymorphic-cubes]: /recipes/data-modeling/polymorphic-cubes
+[ref-dynamic-models]: /docs/data-modeling/dynamic
+[ref-calculated-measures]: /docs/data-modeling/measures#calculated-measures
+[ref-measure-filters]: /reference/data-modeling/measures#filters
+[ref-working-with-joins]: /docs/data-modeling/joins
+[ref-partition-preaggs]: /docs/pre-aggregations/matching-pre-aggregations#partitioning
+[ref-incremental-preaggs]: /reference/data-modeling/pre-aggregations#incremental
+[ref-cube-with-dbt]: /reference/data-modeling/cube-dbt
+[ref-explore]: /analytics/explore
+[ref-workbooks]: /analytics/workbooks
+[ref-rest-api]: /reference/core-data-apis/rest-api
+[ref-sql-api]: /reference/core-data-apis/sql-api
+[ref-ide]: /docs/data-modeling/data-model-ide
diff --git a/docs-mintlify/docs/data-modeling/dimensions.mdx b/docs-mintlify/docs/data-modeling/dimensions.mdx
new file mode 100644
index 0000000000000..08e3d1ec1f613
--- /dev/null
+++ b/docs-mintlify/docs/data-modeling/dimensions.mdx
@@ -0,0 +1,432 @@
+---
+title: Dimensions
+description: Dimensions are attributes that describe individual rows of data — the fields you group by and filter on, such as status, city, or created_at.
+---
+
+Dimensions represent attributes of individual rows in your data. They are
+the fields you group by and filter on — things like `status`, `city`,
+`product_name`, or `created_at`. Each dimension maps to a column or SQL
+expression in your data source.
+
+
+
+See the [dimensions reference][ref-dimensions-ref] for the full list of
+parameters and configuration options.
+
+
+
+## Defining dimensions
+
+A dimension specifies the SQL expression and its type:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: status
+ sql: status
+ type: string
+
+ - name: created_at
+ sql: created_at
+ type: time
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`,
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true },
+ status: { sql: `status`, type: `string` },
+ created_at: { sql: `created_at`, type: `time` }
+ }
+})
+```
+
+
+
+### Dimension types
+
+| Data type in SQL | Dimension type in Cube |
+| --- | --- |
+| `timestamp`, `date`, `time` | [`time`][ref-type] |
+| `text`, `varchar` | [`string`][ref-type] |
+| `integer`, `bigint`, `decimal` | [`number`][ref-type] |
+| `boolean` | [`boolean`][ref-type] |
+
+### Primary keys
+
+Every cube that participates in [joins][ref-joins] should define a
+[`primary_key`][ref-primary-key] dimension. Cube uses primary keys to avoid
+fanouts — when rows get duplicated during joins and aggregates are
+over-counted. Composite primary keys can be created by concatenating columns:
+
+```yaml
+dimensions:
+ - name: composite_key
+ sql: "CONCAT({CUBE}.order_id, '-', {CUBE}.product_id)"
+ type: string
+ primary_key: true
+```
+
+## Time dimensions
+
+Time dimensions are dimensions of the [`time` type][ref-type]. They enable
+grouping by time granularity (year, quarter, month, week, day, hour, minute,
+second) and are essential for time-series analysis.
+
+```yaml
+dimensions:
+ - name: created_at
+ sql: created_at
+ type: time
+```
+
+When queried, you can group by any built-in granularity without defining
+additional dimensions.
+
+### Custom granularities
+
+You can define [custom granularities][ref-granularities] for time dimensions
+when the built-in ones don't fit — for example, weeks starting on Sunday
+or fiscal years:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ # ...
+
+ dimensions:
+ - name: created_at
+ sql: created_at
+ type: time
+ granularities:
+ - name: sunday_week
+ interval: 1 week
+ offset: -1 day
+
+ - name: fiscal_year
+ interval: 1 year
+ offset: 1 month
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ // ...
+
+ dimensions: {
+ created_at: {
+ sql: `created_at`,
+ type: `time`,
+ granularities: {
+ sunday_week: { interval: `1 week`, offset: `-1 day` },
+ fiscal_year: { interval: `1 year`, offset: `1 month` }
+ }
+ }
+ }
+})
+```
+
+
+
+Time dimensions are essential for performance features like
+[partitioned pre-aggregations][ref-partition-preaggs] and
+[incremental refreshes][ref-incremental-preaggs].
+
+
+
+See the following recipes:
+- For a [custom granularity][ref-custom-granularity-recipe] example.
+- For a [custom calendar][ref-custom-calendar-recipe] example.
+
+
+
+## Proxy dimensions
+
+Proxy dimensions reference dimensions from the same cube or other cubes,
+providing a way to reuse existing definitions and reduce code duplication.
+
+### Within the same cube
+
+Reference existing dimensions to build derived ones without duplicating SQL:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: users
+ sql_table: users
+
+ dimensions:
+ - name: initials
+ sql: "SUBSTR(first_name, 1, 1)"
+ type: string
+
+ - name: last_name
+ sql: "UPPER(last_name)"
+ type: string
+
+ - name: full_name
+ sql: "{initials} || '. ' || {last_name}"
+ type: string
+```
+
+```javascript title="JavaScript"
+cube(`users`, {
+ sql_table: `users`,
+
+ dimensions: {
+ initials: { sql: `SUBSTR(first_name, 1, 1)`, type: `string` },
+ last_name: { sql: `UPPER(last_name)`, type: `string` },
+ full_name: { sql: `${initials} || '. ' || ${last_name}`, type: `string` }
+ }
+})
+```
+
+
+
+### From other cubes
+
+If cubes are [joined][ref-joins], you can bring a dimension from one cube
+into another. Cube generates the necessary joins automatically:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+
+ joins:
+ - name: users
+ sql: "{CUBE}.user_id = {users.id}"
+ relationship: many_to_one
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: user_name
+ sql: "{users.name}"
+ type: string
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`,
+
+ joins: {
+ users: {
+ sql: `${CUBE}.user_id = ${users.id}`,
+ relationship: `many_to_one`
+ }
+ },
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true },
+ user_name: { sql: `${users.name}`, type: `string` }
+ }
+})
+```
+
+
+
+### Time dimension granularity references
+
+When referencing a time dimension, you can specify a granularity to create
+a proxy dimension at that specific granularity — including
+[custom granularities](#custom-granularities):
+
+```yaml
+dimensions:
+ - name: created_at
+ sql: created_at
+ type: time
+ granularities:
+ - name: sunday_week
+ interval: 1 week
+ offset: -1 day
+
+ - name: created_at_year
+ sql: "{created_at.year}"
+ type: time
+
+ - name: created_at_sunday_week
+ sql: "{created_at.sunday_week}"
+ type: time
+```
+
+## Subquery dimensions
+
+Subquery dimensions reference [measures][ref-measures-page] from other cubes,
+effectively turning an aggregate into a per-row value. This enables nested
+aggregations — for example, calculating the average of per-customer order counts.
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+
+ joins:
+ - name: users
+ sql: "{users}.id = {CUBE}.user_id"
+ relationship: many_to_one
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ measures:
+ - name: count
+ type: count
+
+ - name: users
+ sql_table: users
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: name
+ sql: name
+ type: string
+
+ - name: order_count
+ sql: "{orders.count}"
+ type: number
+ sub_query: true
+
+ measures:
+ - name: avg_order_count
+ sql: "{order_count}"
+ type: avg
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`,
+
+ joins: {
+ users: {
+ sql: `${users}.id = ${CUBE}.user_id`,
+ relationship: `many_to_one`
+ }
+ },
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true }
+ },
+
+ measures: {
+ count: { type: `count` }
+ }
+})
+
+cube(`users`, {
+ sql_table: `users`,
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true },
+ name: { sql: `name`, type: `string` },
+
+ order_count: {
+ sql: `${orders.count}`,
+ type: `number`,
+ sub_query: true
+ }
+ },
+
+ measures: {
+ avg_order_count: {
+ sql: `${order_count}`,
+ type: `avg`
+ }
+ }
+})
+```
+
+
+
+The `order_count` subquery dimension computes the order count per user.
+The `avg_order_count` measure then averages those per-user values. Cube
+implements this as a correlated subquery via joins for optimal performance.
+
+
+
+See the following recipes:
+- How to calculate [nested aggregates][ref-nested-aggregates-recipe].
+- How to calculate [filtered aggregates][ref-filtered-aggregates-recipe].
+
+
+
+## Hierarchies
+
+Dimensions can be organized into [hierarchies][ref-hierarchies] to define
+drill-down paths (e.g., Country → State → City):
+
+```yaml
+cubes:
+ - name: users
+ # ...
+
+ dimensions:
+ - name: country
+ sql: country
+ type: string
+
+ - name: state
+ sql: state
+ type: string
+
+ - name: city
+ sql: city
+ type: string
+
+ hierarchies:
+ - name: location
+ levels:
+ - country
+ - state
+ - city
+```
+
+## Next steps
+
+- See the [dimensions reference][ref-dimensions-ref] for all parameters
+- Learn about [measures][ref-measures-page] for aggregated calculations
+- Explore [custom granularities][ref-granularities] for fiscal calendars
+ and non-standard time periods
+
+[ref-dimensions-ref]: /reference/data-modeling/dimensions
+[ref-measures-page]: /docs/data-modeling/measures
+[ref-joins]: /docs/data-modeling/joins
+[ref-type]: /reference/data-modeling/dimensions#type
+[ref-primary-key]: /reference/data-modeling/dimensions#primary_key
+[ref-granularities]: /reference/data-modeling/dimensions#granularities
+[ref-hierarchies]: /reference/data-modeling/hierarchies
+[ref-partition-preaggs]: /docs/pre-aggregations/matching-pre-aggregations#partitioning
+[ref-incremental-preaggs]: /reference/data-modeling/pre-aggregations#incremental
+[ref-custom-granularity-recipe]: /recipes/data-modeling/custom-granularity
+[ref-custom-calendar-recipe]: /recipes/data-modeling/custom-calendar
+[ref-nested-aggregates-recipe]: /recipes/data-modeling/nested-aggregates
+[ref-filtered-aggregates-recipe]: /recipes/data-modeling/filtered-aggregates
diff --git a/docs-mintlify/docs/data-modeling/concepts/code-reusability-extending-cubes.mdx b/docs-mintlify/docs/data-modeling/extending-cubes.mdx
similarity index 96%
rename from docs-mintlify/docs/data-modeling/concepts/code-reusability-extending-cubes.mdx
rename to docs-mintlify/docs/data-modeling/extending-cubes.mdx
index c3ac681f09ea2..fe1cdd83e1f86 100644
--- a/docs-mintlify/docs/data-modeling/concepts/code-reusability-extending-cubes.mdx
+++ b/docs-mintlify/docs/data-modeling/extending-cubes.mdx
@@ -1,6 +1,6 @@
---
-title: Extension
-description: Uses extends on cubes and views to inherit and merge members from a parent so shared measures, dimensions, and joins stay defined once.
+title: Extending cubes
+description: Use extends on cubes to inherit and merge members from a parent so shared measures, dimensions, and joins stay defined once.
---
The `extends` parameter, supported for [cubes][ref-cube-extends] and
diff --git a/docs-mintlify/docs/data-modeling/joins.mdx b/docs-mintlify/docs/data-modeling/joins.mdx
new file mode 100644
index 0000000000000..d26b06c3d881a
--- /dev/null
+++ b/docs-mintlify/docs/data-modeling/joins.mdx
@@ -0,0 +1,542 @@
+---
+title: Joins
+description: Joins define relationships between cubes, allowing Cube to automatically generate multi-table SQL queries when views combine data from multiple cubes.
+---
+
+Joins define how cubes connect to each other. When a [view][ref-views]
+includes members from multiple cubes, Cube uses these relationships to
+automatically generate SQL `JOIN` clauses — so end-users can explore data
+across tables without writing SQL.
+
+
+
+See the [joins reference][ref-schema-ref-joins-relationship] for the full
+list of parameters and configuration options.
+
+
+
+## Relationship types
+
+Cube supports three relationship types: `one_to_one`, `one_to_many`, and
+`many_to_one`. The relationship type determines which table becomes the left
+side of the `LEFT JOIN` in the generated SQL.
+
+Consider two cubes, `orders` and `customers`. An order belongs to one
+customer, but a customer can have many orders:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+
+ joins:
+ - name: customers
+ relationship: many_to_one
+ sql: "{CUBE}.customer_id = {customers.id}"
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: status
+ sql: status
+ type: string
+
+ measures:
+ - name: count
+ type: count
+
+ - name: customers
+ sql_table: customers
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: company
+ sql: company
+ type: string
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`,
+
+ joins: {
+ customers: {
+ relationship: `many_to_one`,
+ sql: `${CUBE}.customer_id = ${customers.id}`
+ }
+ },
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true },
+ status: { sql: `status`, type: `string` }
+ },
+
+ measures: {
+ count: { type: `count` }
+ }
+})
+
+cube(`customers`, {
+ sql_table: `customers`,
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true },
+ company: { sql: `company`, type: `string` }
+ }
+})
+```
+
+
+
+The `many_to_one` join on `orders` means: many orders belong to one customer.
+When a view includes members from both cubes, Cube generates SQL with `orders`
+on the left and `customers` on the right:
+
+```sql
+SELECT
+ "orders".status,
+ "customers".company,
+ COUNT("orders".id)
+FROM orders AS "orders"
+LEFT JOIN customers AS "customers"
+ ON "orders".customer_id = "customers".id
+GROUP BY 1, 2
+```
+
+Because `orders` is on the left side of the `LEFT JOIN`, all orders are
+preserved — including guest checkouts with no matching customer.
+
+
+
+As a rule of thumb, define joins on the **fact table** (e.g., `orders`)
+pointing toward the **dimension table** (e.g., `customers`) using
+`many_to_one`. This ensures the fact table is always the base of the query,
+preserving all its rows.
+
+
+
+### Many-to-many relationships
+
+A many-to-many relationship requires an associative (junction) table. For
+example, `posts` and `topics` are connected through a `post_topics` table:
+
+
+
+
+
+Model this with an associative cube, chaining the joins so they flow in one
+direction (`posts → post_topics → topics`):
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: posts
+ sql_table: posts
+
+ joins:
+ - name: post_topics
+ relationship: one_to_many
+ sql: "{CUBE}.id = {post_topics.post_id}"
+
+ - name: post_topics
+ sql_table: post_topics
+
+ joins:
+ - name: topics
+ relationship: many_to_one
+ sql: "{CUBE}.topic_id = {topics.id}"
+
+ dimensions:
+ - name: id
+ sql: "CONCAT({CUBE}.post_id, {CUBE}.topic_id)"
+ type: string
+ primary_key: true
+
+ - name: topics
+ sql_table: topics
+
+ dimensions:
+ - name: id
+ sql: id
+ type: string
+ primary_key: true
+
+ - name: name
+ sql: name
+ type: string
+```
+
+```javascript title="JavaScript"
+cube(`posts`, {
+ sql_table: `posts`,
+
+ joins: {
+ post_topics: {
+ relationship: `one_to_many`,
+ sql: `${CUBE}.id = ${post_topics.post_id}`
+ }
+ }
+})
+
+cube(`post_topics`, {
+ sql_table: `post_topics`,
+
+ joins: {
+ topics: {
+ relationship: `many_to_one`,
+ sql: `${CUBE}.topic_id = ${topics.id}`
+ }
+ },
+
+ dimensions: {
+ id: {
+ sql: `CONCAT(${CUBE}.post_id, ${CUBE}.topic_id)`,
+ type: `string`,
+ primary_key: true
+ }
+ }
+})
+
+cube(`topics`, {
+ sql_table: `topics`,
+
+ dimensions: {
+ id: { sql: `id`, type: `string`, primary_key: true },
+ name: { sql: `name`, type: `string` }
+ }
+})
+```
+
+
+
+A view can then expose this through the `join_path`:
+
+```yaml
+views:
+ - name: posts_with_topics
+ cubes:
+ - join_path: posts
+ includes:
+ - title
+ - count
+
+ - join_path: posts.post_topics.topics
+ prefix: true
+ includes:
+ - name
+```
+
+## Direction of joins
+
+**All joins are directed.** They flow from the source cube (where the join
+is defined) to the target cube (the one referenced). Cube places the source
+cube on the left side of the `LEFT JOIN` and the target on the right.
+
+This matters because the left table preserves all its rows, while the right
+table contributes matching rows or `NULL`. The direction you choose affects
+which records appear in the result set.
+
+For example, if `orders` defines a `many_to_one` join to `customers`:
+- `orders` is the base → all orders are preserved, even guest checkouts
+- `customers` without orders won't appear
+
+If instead `customers` defined a `one_to_many` join to `orders`:
+- `customers` is the base → all customers are preserved, even those without orders
+- Guest checkout orders (with no matching customer) won't appear
+
+### Using views to control direction
+
+Views let you control which join path is followed via the
+[`join_path`][ref-view-join-path] parameter. This is the recommended way to
+handle cases where you need different join directions for different use cases:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+
+ joins:
+ - name: customers
+ sql: "{CUBE}.customer_id = {customers.id}"
+ relationship: many_to_one
+
+ measures:
+ - name: count
+ type: count
+
+ - name: total_revenue
+ sql: revenue
+ type: sum
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: customers
+ sql_table: customers
+
+ joins:
+ - name: orders
+ sql: "{CUBE}.id = {orders.customer_id}"
+ relationship: one_to_many
+
+ measures:
+ - name: count
+ type: count
+
+ dimensions:
+ - name: id
+ sql: id
+ type: number
+ primary_key: true
+
+ - name: name
+ sql: name
+ type: string
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`,
+
+ joins: {
+ customers: {
+ sql: `${CUBE}.customer_id = ${customers.id}`,
+ relationship: `many_to_one`
+ }
+ },
+
+ measures: {
+ count: { type: `count` },
+ total_revenue: { sql: `revenue`, type: `sum` }
+ },
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true }
+ }
+})
+
+cube(`customers`, {
+ sql_table: `customers`,
+
+ joins: {
+ orders: {
+ sql: `${CUBE}.id = ${orders.customer_id}`,
+ relationship: `one_to_many`
+ }
+ },
+
+ measures: {
+ count: { type: `count` }
+ },
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true },
+ name: { sql: `name`, type: `string` }
+ }
+})
+```
+
+
+
+Now you can create two views for two different analytical needs:
+
+
+
+```yaml title="YAML"
+views:
+ - name: revenue_per_customer
+ description: All orders with customer details. Includes guest checkouts.
+ cubes:
+ - join_path: orders
+ includes:
+ - count
+ - total_revenue
+
+ - join_path: orders.customers
+ includes:
+ - name
+
+ - name: customer_activity
+ description: All customers with their order activity. Includes customers without orders.
+ cubes:
+ - join_path: customers
+ includes:
+ - name
+ - count
+
+ - join_path: customers.orders
+ prefix: true
+ includes:
+ - count
+ - total_revenue
+```
+
+```javascript title="JavaScript"
+view(`revenue_per_customer`, {
+ description: `All orders with customer details. Includes guest checkouts.`,
+ cubes: [
+ {
+ join_path: orders,
+ includes: [`count`, `total_revenue`]
+ },
+ {
+ join_path: orders.customers,
+ includes: [`name`]
+ }
+ ]
+})
+
+view(`customer_activity`, {
+ description: `All customers with their order activity. Includes customers without orders.`,
+ cubes: [
+ {
+ join_path: customers,
+ includes: [`name`, `count`]
+ },
+ {
+ join_path: customers.orders,
+ prefix: true,
+ includes: [`count`, `total_revenue`]
+ }
+ ]
+})
+```
+
+
+
+The `revenue_per_customer` view follows the `orders → customers` path, so all
+orders are preserved. The `customer_activity` view follows
+`customers → orders`, so all customers are preserved.
+
+## Diamond subgraphs
+
+A _diamond subgraph_ occurs when there's more than one join path between two
+cubes — for example, `users.schools.countries` and
+`users.employers.countries`. This can lead to ambiguous query generation.
+
+Views resolve this ambiguity by specifying the exact `join_path` for each
+included cube. For example, if cube `a` joins to both `b` and `c`, and both
+`b` and `c` join to `d`, a view can specify which path to follow:
+
+```yaml
+views:
+ - name: a_with_d_via_b
+ cubes:
+ - join_path: a
+ includes: "*"
+
+ - join_path: a.b.d
+ prefix: true
+ includes:
+ - value
+
+ - name: a_with_d_via_c
+ cubes:
+ - join_path: a
+ includes: "*"
+
+ - join_path: a.c.d
+ prefix: true
+ includes:
+ - value
+```
+
+Each view follows a specific, unambiguous path through the data graph.
+
+## Join paths in calculated members
+
+When referencing a member of another cube in a [calculated member][ref-calculated-members],
+you can use a join path to specify the exact route. This uses dot-separated
+cube names:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ # ...
+
+ dimensions:
+ - name: customer_country
+ sql: "{customers.country}"
+ type: string
+
+ - name: shipping_country
+ sql: "{shipping_addresses.country}"
+ type: string
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ // ...
+
+ dimensions: {
+ customer_country: {
+ sql: `${customers.country}`,
+ type: `string`
+ },
+
+ shipping_country: {
+ sql: `${shipping_addresses.country}`,
+ type: `string`
+ }
+ }
+})
+```
+
+
+
+## Troubleshooting
+
+### `Can't find join path`
+
+The error `Can't find join path to join 'cube_a', 'cube_b'` means the cubes
+included in a view or query can't be connected through the defined joins.
+
+Check that:
+- Joins are defined with the correct [direction](#direction-of-joins)
+- There is a continuous path from the source cube to the target cube
+- You're using the [`join_path`][ref-view-join-path] parameter in views to
+ specify the exact path
+
+### `Primary key is required when join is defined`
+
+Cube uses primary keys to avoid fanouts — when rows get duplicated during
+joins and aggregates are over-counted. Define a [primary key][ref-primary-key]
+dimension in every cube that participates in joins.
+
+If your data doesn't have a natural primary key, create a composite one:
+
+```yaml
+cubes:
+ - name: events
+ # ...
+
+ dimensions:
+ - name: composite_key
+ sql: CONCAT(column_a, '-', column_b, '-', column_c)
+ type: string
+ primary_key: true
+```
+
+[ref-schema-ref-joins-relationship]: /reference/data-modeling/joins
+[ref-views]: /docs/data-modeling/views
+[ref-view-join-path]: /reference/data-modeling/view#join_path
+[ref-calculated-members]: /docs/data-modeling/measures#calculated-measures
+[ref-primary-key]: /reference/data-modeling/dimensions#primary_key
+[ref-visual-model]: /docs/data-modeling/visual-modeler
diff --git a/docs-mintlify/docs/data-modeling/measures.mdx b/docs-mintlify/docs/data-modeling/measures.mdx
new file mode 100644
index 0000000000000..0a443613af3bb
--- /dev/null
+++ b/docs-mintlify/docs/data-modeling/measures.mdx
@@ -0,0 +1,434 @@
+---
+title: Measures
+description: Measures compute aggregated values across rows — counts, sums, averages, and more complex calculations like rolling windows, time shifts, and rankings.
+---
+
+While [dimensions][ref-dimensions-page] describe attributes of individual rows,
+measures compute values across rows — sums, counts, averages, and other
+aggregations. Measures can aggregate columns directly (like `sum of revenue`)
+or reference other measures to create compound metrics (like `revenue / count`).
+
+
+
+See the [measures reference][ref-measures-ref] for the full list of parameters
+and configuration options.
+
+
+
+## Defining measures
+
+A measure specifies the SQL expression to aggregate and the aggregation type:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ sql_table: orders
+
+ measures:
+ - name: count
+ type: count
+
+ - name: total_amount
+ sql: amount
+ type: sum
+
+ - name: average_amount
+ sql: amount
+ type: avg
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ sql_table: `orders`,
+
+ measures: {
+ count: { type: `count` },
+ total_amount: { sql: `amount`, type: `sum` },
+ average_amount: { sql: `amount`, type: `avg` }
+ }
+})
+```
+
+
+
+## Filtered measures
+
+You can apply [filters][ref-filters] to a measure to create conditional
+aggregations. Only rows matching the filter are included:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ # ...
+
+ measures:
+ - name: count
+ type: count
+
+ - name: completed_count
+ type: count
+ filters:
+ - sql: "{CUBE}.status = 'completed'"
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ // ...
+
+ measures: {
+ count: { type: `count` },
+
+ completed_count: {
+ type: `count`,
+ filters: [{ sql: `${CUBE}.status = 'completed'` }]
+ }
+ }
+})
+```
+
+
+
+When `completed_count` is queried, Cube generates SQL with a `CASE` expression:
+
+```sql
+SELECT
+ COUNT(CASE WHEN (orders.status = 'completed') THEN 1 END) AS completed_count
+FROM orders
+```
+
+## Calculated measures
+
+Calculated measures perform calculations on other measures using SQL functions
+and operators. They provide a way to decompose complex metrics (e.g., ratios
+or percents) into formulas involving simpler measures.
+
+### Referencing measures in the same cube
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: orders
+ # ...
+
+ measures:
+ - name: count
+ type: count
+
+ - name: completed_count
+ type: count
+ filters:
+ - sql: "{CUBE}.status = 'completed'"
+
+ - name: completed_ratio
+ sql: "1.0 * {completed_count} / NULLIF({count}, 0)"
+ type: number
+```
+
+```javascript title="JavaScript"
+cube(`orders`, {
+ // ...
+
+ measures: {
+ count: { type: `count` },
+
+ completed_count: {
+ type: `count`,
+ filters: [{ sql: `${CUBE}.status = 'completed'` }]
+ },
+
+ completed_ratio: {
+ sql: `1.0 * ${completed_count} / NULLIF(${count}, 0)`,
+ type: `number`
+ }
+ }
+})
+```
+
+
+
+### Referencing measures from other cubes
+
+If cubes are [joined][ref-joins], you can reference measures across cubes.
+Cube generates the necessary joins automatically:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: users
+ # ...
+
+ joins:
+ - name: orders
+ sql: "{CUBE}.id = {orders}.user_id"
+ relationship: one_to_many
+
+ measures:
+ - name: count
+ type: count
+
+ - name: purchases_to_users_ratio
+ sql: "1.0 * {orders.purchases} / NULLIF({CUBE.count}, 0)"
+ type: number
+```
+
+```javascript title="JavaScript"
+cube(`users`, {
+ // ...
+
+ joins: {
+ orders: {
+ sql: `${CUBE}.id = ${orders}.user_id`,
+ relationship: `one_to_many`
+ }
+ },
+
+ measures: {
+ count: { type: `count` },
+
+ purchases_to_users_ratio: {
+ sql: `1.0 * ${orders.purchases} / NULLIF(${CUBE.count}, 0)`,
+ type: `number`
+ }
+ }
+})
+```
+
+
+
+## Multi-stage measures
+
+Multi-stage measures are calculated in two or more stages, enabling
+calculations on already-aggregated data. Each stage results in one or more
+CTEs in the generated SQL query.
+
+
+
+Multi-stage measures are powered by Tesseract, the [next-generation data
+modeling engine][link-tesseract]. Tesseract is currently in preview. Use the
+[`CUBEJS_TESSERACT_SQL_PLANNER`][ref-tesseract-env] environment variable to
+enable it.
+
+
+
+### Rolling windows
+
+Rolling window measures calculate metrics over a moving window of time, such
+as cumulative counts or moving averages. Use the
+[`rolling_window`][ref-rolling-window] parameter:
+
+```yaml
+measures:
+ - name: cumulative_count
+ type: count
+ rolling_window:
+ trailing: unbounded
+
+ - name: trailing_month_count
+ sql: id
+ type: count
+ rolling_window:
+ trailing: 1 month
+```
+
+### Period-to-date
+
+Period-to-date measures analyze data from the start of a period to the current
+date — year-to-date (YTD), quarter-to-date (QTD), or month-to-date (MTD):
+
+```yaml
+measures:
+ - name: revenue_ytd
+ sql: revenue
+ type: sum
+ rolling_window:
+ type: to_date
+ granularity: year
+
+ - name: revenue_qtd
+ sql: revenue
+ type: sum
+ rolling_window:
+ type: to_date
+ granularity: quarter
+```
+
+### Time shift
+
+Time-shift measures calculate the value of another measure at a different
+point in time, typically for period-over-period comparisons like
+year-over-year growth. Use the [`time_shift`][ref-time-shift] parameter:
+
+```yaml
+measures:
+ - name: revenue
+ sql: revenue
+ type: sum
+
+ - name: revenue_prior_year
+ multi_stage: true
+ sql: "{revenue}"
+ type: number
+ time_shift:
+ - interval: 1 year
+ type: prior
+```
+
+You can combine time shift with period-to-date for comparisons like
+"this year's YTD vs. last year's YTD":
+
+```yaml
+measures:
+ - name: revenue_ytd
+ sql: revenue
+ type: sum
+ rolling_window:
+ type: to_date
+ granularity: year
+
+ - name: revenue_prior_year_ytd
+ multi_stage: true
+ sql: "{revenue_ytd}"
+ type: number
+ time_shift:
+ - time_dimension: time
+ interval: 1 year
+ type: prior
+```
+
+Time-shift measures can also be used with [calendar cubes][ref-calendar-cubes]
+to customize how time-shifting works, e.g., to shift by retail calendar
+periods.
+
+### Percent of total (fixed dimension)
+
+Use the [`group_by`][ref-group-by] parameter to fix the inner aggregation to
+specific dimensions, enabling percent-of-total calculations:
+
+```yaml
+measures:
+ - name: revenue
+ sql: revenue
+ type: sum
+
+ - name: country_revenue
+ multi_stage: true
+ sql: "{revenue}"
+ type: sum
+ group_by:
+ - country
+
+ - name: country_revenue_percentage
+ multi_stage: true
+ sql: "{revenue} / NULLIF({country_revenue}, 0)"
+ type: number
+```
+
+### Nested aggregates
+
+Use the [`add_group_by`][ref-add-group-by] parameter to compute an aggregate
+of an aggregate, e.g., the average of per-customer averages:
+
+```yaml
+measures:
+ - name: avg_order_value
+ sql: amount
+ type: avg
+
+ - name: avg_customer_order_value
+ multi_stage: true
+ sql: "{avg_order_value}"
+ type: avg
+ add_group_by:
+ - customer_id
+```
+
+### Ranking
+
+Use the [`reduce_by`][ref-reduce-by] parameter to rank items within groups:
+
+```yaml
+measures:
+ - name: revenue
+ sql: revenue
+ type: sum
+
+ - name: product_rank
+ multi_stage: true
+ order_by:
+ - sql: "{revenue}"
+ dir: asc
+ reduce_by:
+ - product
+ type: rank
+```
+
+### Conditional measures
+
+Conditional measures depend on the value of a dimension, using the
+[`case`][ref-case] parameter with [`switch` dimensions][ref-switch-dim]:
+
+```yaml
+measures:
+ - name: amount_in_currency
+ multi_stage: true
+ case:
+ switch: "{CUBE.currency}"
+ when:
+ - value: EUR
+ sql: "{CUBE.amount_eur}"
+ - value: GBP
+ sql: "{CUBE.amount_gbp}"
+ else:
+ sql: "{CUBE.amount_usd}"
+ type: number
+```
+
+## Formatting
+
+Use the [`format`][ref-format] parameter to control how measures are displayed:
+
+```yaml
+measures:
+ - name: total_revenue
+ sql: revenue
+ type: sum
+ format: currency
+
+ - name: conversion_rate
+ sql: "1.0 * {completed_count} / NULLIF({count}, 0)"
+ type: number
+ format: percent
+```
+
+## Next steps
+
+- See the [measures reference][ref-measures-ref] for all parameters
+- Learn about [dimensions][ref-dimensions-page] for grouping and filtering
+- Explore [pre-aggregations][ref-pre-aggs] to accelerate measure queries
+- See the [period-over-period recipe][ref-pop-recipe] for advanced time
+ comparisons
+
+[ref-measures-ref]: /reference/data-modeling/measures
+[ref-dimensions-page]: /docs/data-modeling/dimensions
+[ref-joins]: /docs/data-modeling/joins
+[ref-pre-aggs]: /reference/data-modeling/pre-aggregations
+[ref-type]: /reference/data-modeling/measures#type
+[ref-filters]: /reference/data-modeling/measures#filters
+[ref-format]: /reference/data-modeling/measures#format
+[ref-rolling-window]: /reference/data-modeling/measures#rolling_window
+[ref-time-shift]: /reference/data-modeling/measures#time_shift
+[ref-group-by]: /reference/data-modeling/measures#group_by
+[ref-reduce-by]: /reference/data-modeling/measures#reduce_by
+[ref-add-group-by]: /reference/data-modeling/measures#add_group_by
+[ref-case]: /reference/data-modeling/measures#case
+[ref-switch-dim]: /reference/data-modeling/dimensions#type
+[ref-tesseract-env]: /reference/configuration/environment-variables#cubejs_tesseract_sql_planner
+[ref-calendar-cubes]: /docs/data-modeling/concepts/calendar-cubes
+[ref-pop-recipe]: /recipes/data-modeling/period-over-period
+[link-tesseract]: https://cube.dev/blog/introducing-next-generation-data-modeling-engine
diff --git a/docs-mintlify/docs/data-modeling/multi-fact-views.mdx b/docs-mintlify/docs/data-modeling/multi-fact-views.mdx
new file mode 100644
index 0000000000000..bd9634615ab87
--- /dev/null
+++ b/docs-mintlify/docs/data-modeling/multi-fact-views.mdx
@@ -0,0 +1,421 @@
+---
+title: Multi-fact views
+description: Analyze data across multiple fact tables that share common dimensions like time or customers, without row multiplication or manual workarounds.
+---
+
+In many data models, you have multiple fact tables that share common
+dimensions but have no direct relationship to each other. For example,
+an e-commerce company tracks both orders and returns:
+
+- **`orders`** — one row per order, with `customer_id` and `created_at`
+- **`returns`** — one row per return, with `customer_id` and `created_at`
+- **`customers`** — one row per customer
+- **`dates`** — a date spine
+
+Both `orders` and `returns` join to `customers` and `dates`, but they don't
+join to each other:
+
+```
+ customers
+ / \
+ orders returns
+ \ /
+ dates
+```
+
+You need a report showing `orders_count`, `total_revenue`, `returns_count`,
+and `total_refunds` grouped by customer and month. But joining `orders` and
+`returns` directly would produce a cross product — every order matched with
+every return for that customer and date — inflating all counts and sums.
+
+## How multi-fact views solve this
+
+In a regular [view][ref-views], there is a single **root cube** — the first
+cube listed in the view's `cubes` array. All joins flow from this root, and
+Cube uses it as the base table in the generated SQL.
+
+Multi-fact views work differently. When a view includes measures from
+**multiple fact tables**, Cube selects the root dynamically at query time
+based on which measures are requested. Each fact table gets its own
+aggregating subquery, and the results are joined on the shared dimensions.
+No fanout, no manual workarounds.
+
+
+
+Multi-fact views are powered by Tesseract, the [next-generation data modeling
+engine][link-tesseract]. Tesseract is currently in preview. Use the
+[`CUBEJS_TESSERACT_SQL_PLANNER`][ref-tesseract-env] environment variable to
+enable it.
+
+
+
+## How to model it
+
+### 1. Define the cubes
+
+Each fact table becomes a cube with explicit joins to the shared dimension
+tables:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: customers
+ sql_table: customers
+
+ dimensions:
+ - name: id
+ type: number
+ sql: id
+ primary_key: true
+ - name: name
+ type: string
+ sql: name
+ - name: city
+ type: string
+ sql: city
+
+ - name: dates
+ sql_table: dates
+
+ dimensions:
+ - name: date
+ type: time
+ sql: date
+ primary_key: true
+
+ - name: orders
+ sql_table: orders
+
+ joins:
+ - name: customers
+ relationship: many_to_one
+ sql: "{orders}.customer_id = {customers.id}"
+ - name: dates
+ relationship: many_to_one
+ sql: "DATE_TRUNC('day', {orders}.created_at) = {dates.date}"
+
+ dimensions:
+ - name: id
+ type: number
+ sql: id
+ primary_key: true
+ - name: status
+ type: string
+ sql: status
+
+ measures:
+ - name: count
+ type: count
+ - name: total_amount
+ type: sum
+ sql: amount
+
+ - name: returns
+ sql_table: returns
+
+ joins:
+ - name: customers
+ relationship: many_to_one
+ sql: "{returns}.customer_id = {customers.id}"
+ - name: dates
+ relationship: many_to_one
+ sql: "DATE_TRUNC('day', {returns}.created_at) = {dates.date}"
+
+ dimensions:
+ - name: id
+ type: number
+ sql: id
+ primary_key: true
+
+ measures:
+ - name: count
+ type: count
+ - name: total_refund
+ type: sum
+ sql: refund_amount
+```
+
+```javascript title="JavaScript"
+cube(`customers`, {
+ sql_table: `customers`,
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true },
+ name: { sql: `name`, type: `string` },
+ city: { sql: `city`, type: `string` }
+ }
+})
+
+cube(`dates`, {
+ sql_table: `dates`,
+
+ dimensions: {
+ date: { sql: `date`, type: `time`, primary_key: true }
+ }
+})
+
+cube(`orders`, {
+ sql_table: `orders`,
+
+ joins: {
+ customers: {
+ relationship: `many_to_one`,
+ sql: `${orders}.customer_id = ${customers.id}`
+ },
+ dates: {
+ relationship: `many_to_one`,
+ sql: `DATE_TRUNC('day', ${orders}.created_at) = ${dates.date}`
+ }
+ },
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true },
+ status: { sql: `status`, type: `string` }
+ },
+
+ measures: {
+ count: { type: `count` },
+ total_amount: { sql: `amount`, type: `sum` }
+ }
+})
+
+cube(`returns`, {
+ sql_table: `returns`,
+
+ joins: {
+ customers: {
+ relationship: `many_to_one`,
+ sql: `${returns}.customer_id = ${customers.id}`
+ },
+ dates: {
+ relationship: `many_to_one`,
+ sql: `DATE_TRUNC('day', ${returns}.created_at) = ${dates.date}`
+ }
+ },
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true }
+ },
+
+ measures: {
+ count: { type: `count` },
+ total_refund: { sql: `refund_amount`, type: `sum` }
+ }
+})
+```
+
+
+
+The critical detail: both `orders` and `returns` declare direct joins to
+`customers` and `dates`. This tells Cube that these dimension tables are shared
+between the two facts.
+
+### 2. Create a view
+
+The view brings both fact tables and the shared dimension tables together.
+Dimension tables are included at root-level join paths (not nested under a
+specific fact), which makes their dimensions common to both facts. Use
+`prefix` to disambiguate identically named members across fact cubes:
+
+
+
+```yaml title="YAML"
+views:
+ - name: customer_overview
+ cubes:
+ - join_path: orders
+ prefix: true
+ includes:
+ - count
+ - total_amount
+ - join_path: returns
+ prefix: true
+ includes:
+ - count
+ - total_refund
+ - join_path: customers
+ includes:
+ - name
+ - city
+ - join_path: dates
+ includes:
+ - date
+```
+
+```javascript title="JavaScript"
+view(`customer_overview`, {
+ cubes: [
+ {
+ join_path: orders,
+ prefix: true,
+ includes: [`count`, `total_amount`]
+ },
+ {
+ join_path: returns,
+ prefix: true,
+ includes: [`count`, `total_refund`]
+ },
+ {
+ join_path: customers,
+ includes: [`name`, `city`]
+ },
+ {
+ join_path: dates,
+ includes: [`date`]
+ }
+ ]
+})
+```
+
+
+
+When you query `orders_count`, `orders_total_amount`, `returns_count`, and
+`returns_total_refund` grouped by `name`, `city`, and `date`, Cube detects
+the two separate fact roots and automatically executes a multi-fact query.
+
+## What Cube does under the hood
+
+Cube executes the query in three stages:
+
+### 1. Separate aggregating subqueries
+
+Each fact table gets its own independent subquery that joins only the tables
+it needs, applies relevant filters, and aggregates by the common dimensions:
+
+- **Subquery 1** (orders): joins `orders` → `customers` and `orders` → `dates`,
+ computes `COUNT(*)` and `SUM(amount)`, grouped by `name`, `city`, `date`
+- **Subquery 2** (returns): joins `returns` → `customers` and `returns` → `dates`,
+ computes `COUNT(*)` and `SUM(refund_amount)`, grouped by `name`, `city`, `date`
+
+### 2. Join on common dimensions
+
+The subquery results are joined with `FULL JOIN` on all common dimension
+columns (`name`, `city`, `date`). This preserves rows that exist in only one
+fact table — a customer who placed orders but never returned anything still
+appears in the results.
+
+### 3. Final result
+
+The combined result shows measures from each fact table side by side:
+
+| name | city | date | orders_count | orders_total_amount | returns_count | returns_total_refund |
+| --- | --- | --- | --- | --- | --- | --- |
+| Alice | New York | 2025-01-15 | 2 | 200.00 | 0 | NULL |
+| Alice | New York | 2025-02-10 | 2 | 225.00 | 1 | 100.00 |
+| Bob | Seattle | 2025-01-20 | 3 | 550.00 | 2 | 130.00 |
+| Charlie | New York | 2025-02-05 | 0 | NULL | 2 | 100.00 |
+| Diana | Boston | 2025-03-01 | 1 | 400.00 | 0 | NULL |
+
+Charlie has no orders and Diana has no returns — both are still included
+with `NULL` values for the missing fact table.
+
+## Common patterns
+
+### Time as the shared dimension
+
+The most common multi-fact pattern uses time as the shared dimension.
+For example, you might have `page_views`, `signups`, and `purchases` that all
+have timestamps but no direct relationship. By joining each to a shared
+`dates` cube, you can analyze conversion funnels — page views vs. signups
+vs. purchases by day — without any row multiplication.
+
+### More than two fact tables
+
+Multi-fact queries are not limited to two fact tables. If a view includes
+three or more facts, each gets its own aggregating subquery, and all results
+are joined on the common dimensions.
+
+### Facts that don't share all dimensions
+
+Every root fact table must be joinable to the **same set of common dimension
+tables**. If a fact table doesn't naturally have a foreign key for one of the
+common dimensions, you can create a synthetic join:
+
+
+
+```yaml title="YAML"
+cubes:
+ - name: refunds
+ sql: >
+ SELECT *, NULL AS customer_id FROM refunds
+ joins:
+ - name: customers
+ relationship: many_to_one
+ sql: "{refunds}.customer_id = {customers.id}"
+ - name: dates
+ relationship: many_to_one
+ sql: "DATE_TRUNC('day', {refunds}.created_at) = {dates.date}"
+
+ dimensions:
+ - name: id
+ type: number
+ sql: id
+ primary_key: true
+
+ measures:
+ - name: count
+ type: count
+ - name: total_amount
+ type: sum
+ sql: amount
+```
+
+```javascript title="JavaScript"
+cube(`refunds`, {
+ sql: `SELECT *, NULL AS customer_id FROM refunds`,
+
+ joins: {
+ customers: {
+ relationship: `many_to_one`,
+ sql: `${refunds}.customer_id = ${customers.id}`
+ },
+ dates: {
+ relationship: `many_to_one`,
+ sql: `DATE_TRUNC('day', ${refunds}.created_at) = ${dates.date}`
+ }
+ },
+
+ dimensions: {
+ id: { sql: `id`, type: `number`, primary_key: true }
+ },
+
+ measures: {
+ count: { type: `count` },
+ total_amount: { sql: `amount`, type: `sum` }
+ }
+})
+```
+
+
+
+The `NULL AS customer_id` makes the join syntactically valid. Refund rows
+won't match a specific customer, but the subquery can still participate in
+the multi-fact join on the full set of common dimensions.
+
+## Filters and segments
+
+**Common dimension filters** (like `city = 'New York'` or `date > '2025-01-01'`)
+are applied to every subquery, ensuring consistent filtering across all facts.
+
+**Fact-specific filters** (like `orders.status = 'completed'`) are applied only
+to that fact's subquery. Other fact subqueries remain unaffected.
+
+**Measure filters** (like `orders_count > 1`) are applied as `HAVING`
+conditions after the subqueries are joined.
+
+[Segments][ref-segments] that belong to a specific fact table are applied only
+to that fact's subquery.
+
+## Join path requirements
+
+- Each fact cube must declare **direct joins** to all shared dimension tables
+- Dimension tables should be included in the view at **root-level join paths**,
+ not nested under a specific fact (e.g., `customers`, not `orders.customers`)
+- Use `prefix` on fact cubes to disambiguate identically named members
+
+[ref-views]: /docs/data-modeling/views
+[ref-view-ref]: /reference/data-modeling/view
+[ref-segments]: /reference/data-modeling/segments
+[ref-tesseract-env]: /reference/configuration/environment-variables#cubejs_tesseract_sql_planner
+[link-tesseract]: https://cube.dev/blog/introducing-tesseract
diff --git a/docs-mintlify/docs/data-modeling/overview.mdx b/docs-mintlify/docs/data-modeling/overview.mdx
index 80da010e3109a..3fad11bf20061 100644
--- a/docs-mintlify/docs/data-modeling/overview.mdx
+++ b/docs-mintlify/docs/data-modeling/overview.mdx
@@ -3,23 +3,10 @@ title: Getting started
description: Build a reusable semantic layer that provides the shared context for AI agents, BI dashboards, and embedded analytics — turning warehouse tables into governed metrics and dimensions.
---
-The data model is used to transform raw data into meaningful business
-definitions and pre-aggregate data for optimal results. The data model is
-exposed through a [rich set of APIs][ref-apis] that allows end-users to
-run a wide variety of analytical queries without modifying the data model
-itself.
-
-
-
-You can explore a carefully crafted sample data model if you create a [demo
-deployment][ref-demo-deployment] in Cube Cloud.
-
-
-
Let’s use a users table with the following columns as an example:
| id | paying | city | company_name |
@@ -42,8 +29,8 @@ allows building well-organized and reusable SQL.
## 1. Creating a Cube
-In Cube, [cubes][ref-schema-cube] are used to organize entities and connections
-between entities. Usually one cube is created for each table in the database,
+In Cube, [cubes][ref-schema-cube] are used to organize tables and connections
+between tables. Usually one cube is created for each table in the database,
such as `users`, `orders`, `products`, etc. In the `sql_table` parameter of the
cube we define a base table for this cube. In our case, the base table is simply
our `users` table.
@@ -290,7 +277,7 @@ measure via an API, the following SQL will be generated:
```sql
SELECT
- 100.0 * COUNT(
+ 1.0 * COUNT(
CASE WHEN (users.paying = 'true') THEN users.id END
) / COUNT(users.id) AS paying_percentage
FROM users
@@ -349,7 +336,7 @@ model.
[ref-backend-query-format]: /reference/rest-api/query-format
[ref-demo-deployment]: /docs/deployment/cloud/deployments#demo-deployments
[ref-apis]: /reference
-[ref-calculated-measures]: /docs/data-modeling/concepts/calculated-members#calculated-measures
+[ref-calculated-measures]: /docs/data-modeling/measures#calculated-measures
[ref-views]: /reference/data-modeling/view
[ref-explore]: /analytics/explore
[ref-workbooks]: /analytics/workbooks
\ No newline at end of file
diff --git a/docs-mintlify/docs/data-modeling/views.mdx b/docs-mintlify/docs/data-modeling/views.mdx
new file mode 100644
index 0000000000000..30dbc77f86aa6
--- /dev/null
+++ b/docs-mintlify/docs/data-modeling/views.mdx
@@ -0,0 +1,449 @@
+---
+title: Views
+description: Views are curated datasets that sit on top of cubes and create a user-friendly facade of your data model for downstream consumers, AI agents, and embedded analytics.
+---
+
+Views sit on top of the data graph of [cubes][ref-cubes] and create a facade
+of your whole data model with which data consumers can interact. They bring
+together relevant measures, dimensions, and join paths into a logical
+structure that matches how business users think about their data.
+
+
+
+
+
+
+
+See the [view reference][ref-view-reference] for the full list of
+parameters and configuration options.
+
+
+
+## Why views matter
+
+Views are the primary interface between your data model and your users.
+While cubes model the raw relationships and logic in your warehouse, views
+reshape that model into business-friendly datasets for easier exploration.
+
+
+
+ Views shield end-users from complex database schemas, table
+ relationships, and raw SQL. Business users can pick fields from
+ a curated dataset in [Explore][ref-explore] or
+ [Workbooks][ref-workbooks] without needing to understand the joins
+ or cube structure underneath.
+
+ For example, an analyst could pick `product`, `total_amount`, and
+ `users_city` from an `orders` view without thinking about the underlying
+ join path from `base_orders` through `line_items` to `products`.
+
+
+
+ [AI agents][ref-ai-context] query your data model through views.
+ By curating which members are included and providing descriptive
+ metadata via `description` and `meta.ai_context`, you control the
+ context AI uses to generate accurate queries. Well-designed views
+ with clear naming and descriptions lead to significantly better
+ AI results.
+
+
+
+ Views give you fine-grained control over what users can see.
+ Each view can be scoped with [access policies][ref-access-policies]
+ to enforce row-level and member-level security. You can also set
+ `public: false` to hide internal views or use
+ [COMPILE_CONTEXT][ref-compile-context] for dynamic visibility
+ based on the security context.
+
+
+
+ In complex data models, the same pair of cubes might be reachable
+ through multiple join paths. Views eliminate this ambiguity by
+ specifying the exact `join_path` for each included cube, ensuring
+ queries always follow the intended path.
+
+
+
+ Views are a natural fit for [embedded analytics][ref-embedding].
+ Different customer tiers can get access to different views,
+ allowing you to tailor the analytics experience to your
+ monetization strategy without duplicating cubes.
+
+
+
+## How views work
+
+Views do **not** define their own members. Instead, they reference cubes by
+specific join paths and selectively include measures, dimensions, and
+segments from those cubes.
+
+
+
+```yaml title="YAML"
+views:
+ - name: orders
+
+ cubes:
+ - join_path: base_orders
+ includes:
+ - status
+ - created_date
+ - total_amount
+ - count
+ - average_order_value
+
+ - join_path: base_orders.line_items.products
+ includes:
+ - name: name
+ alias: product
+
+ - join_path: base_orders.users
+ prefix: true
+ includes: "*"
+ excludes:
+ - company
+```
+
+```javascript title="JavaScript"
+view(`orders`, {
+ cubes: [
+ {
+ join_path: base_orders,
+ includes: [
+ `status`,
+ `created_date`,
+ `total_amount`,
+ `count`,
+ `average_order_value`
+ ]
+ },
+ {
+ join_path: base_orders.line_items.products,
+ includes: [
+ {
+ name: `name`,
+ alias: `product`
+ }
+ ]
+ },
+ {
+ join_path: base_orders.users,
+ prefix: true,
+ includes: `*`,
+ excludes: [`company`]
+ }
+ ]
+})
+```
+
+
+
+In this example, the `orders` view pulls in members from three cubes
+along their join paths. End-users see a flat list of fields — `status`,
+`created_date`, `product`, `users_city`, etc. — without being exposed to
+the underlying cube structure.
+
+## Designing effective views
+
+### Build for your audience
+
+Design views around how your business users think about data, not around
+how your database is structured. Group related fields into views that align
+with departments or use cases — for example, `sales_overview`,
+`customer_360`, or `product_analytics`.
+
+
+
+A single cube can be included in multiple views. For example, a `users`
+cube might appear in both a `customer_360` view and a `sales_overview`
+view, with different fields exposed in each.
+
+
+
+### Favor focused views
+
+Smaller, focused views are easier to navigate and lead to better AI
+results. Rather than one massive view with hundreds of fields, create
+several purpose-built views:
+
+- Views are easier for business users to understand when they're
+ scoped to a specific domain
+- AI agents perform better with focused context
+- Simpler views translate to simpler SQL queries with fewer joins
+
+### Curate with metadata
+
+Help your users understand what a view is for and how to use it:
+
+- Set a clear [`description`][ref-view-description] to explain the
+ view's purpose
+- Use [`title`][ref-view-title] for user-friendly display names
+- Add [`meta.ai_context`][ref-ai-context] to guide AI agents
+- Organize fields into [`folders`][ref-view-folders] for logical
+ grouping
+
+
+
+```yaml title="YAML"
+views:
+ - name: sales_overview
+ description: >
+ Revenue and order metrics for the sales team.
+ Includes order status, product details, and customer segments.
+ meta:
+ ai_context: >
+ Use this view for questions about sales performance,
+ revenue trends, and order analysis. The total_revenue
+ measure includes only completed orders.
+
+ cubes:
+ - join_path: orders
+ includes:
+ - status
+ - total_revenue
+ - count
+ - created_date
+
+ - join_path: orders.customers
+ prefix: true
+ includes:
+ - segment
+ - region
+
+ folders:
+ - name: Order Metrics
+ includes:
+ - total_revenue
+ - count
+ - status
+
+ - name: Customer Info
+ includes:
+ - customers_segment
+ - customers_region
+```
+
+```javascript title="JavaScript"
+view(`sales_overview`, {
+ description: `Revenue and order metrics for the sales team.
+ Includes order status, product details, and customer segments.`,
+ meta: {
+ ai_context: `Use this view for questions about sales performance,
+ revenue trends, and order analysis. The total_revenue
+ measure includes only completed orders.`
+ },
+
+ cubes: [
+ {
+ join_path: orders,
+ includes: [
+ `status`,
+ `total_revenue`,
+ `count`,
+ `created_date`
+ ]
+ },
+ {
+ join_path: orders.customers,
+ prefix: true,
+ includes: [
+ `segment`,
+ `region`
+ ]
+ }
+ ],
+
+ folders: [
+ {
+ name: `Order Metrics`,
+ includes: [
+ `total_revenue`,
+ `count`,
+ `status`
+ ]
+ },
+ {
+ name: `Customer Info`,
+ includes: [
+ `customers_segment`,
+ `customers_region`
+ ]
+ }
+ ]
+})
+```
+
+
+
+### Keep shared logic in cubes
+
+Views are a curation layer. All business logic — SQL definitions, measure
+calculations, join relationships — should live in cubes. Views should only
+control which members are exposed, how they're named, and how they're
+organized. This keeps your model [DRY][wiki-dry] and makes maintenance
+straightforward.
+
+### Control visibility
+
+Not every view should be publicly accessible. Use [`public`][ref-view-public]
+to hide views that are meant for internal use or are still in development:
+
+
+
+```yaml title="YAML"
+views:
+ - name: internal_diagnostics
+ public: false
+
+ cubes:
+ - join_path: system_metrics
+ includes: "*"
+```
+
+```javascript title="JavaScript"
+view(`internal_diagnostics`, {
+ public: false,
+
+ cubes: [
+ {
+ join_path: system_metrics,
+ includes: `*`
+ }
+ ]
+})
+```
+
+
+
+For dynamic visibility based on user roles, use `COMPILE_CONTEXT`:
+
+
+
+```yaml title="YAML"
+views:
+ - name: arr
+ description: Annual Recurring Revenue
+ public: COMPILE_CONTEXT.security_context.is_finance
+
+ cubes:
+ - join_path: revenue
+ includes:
+ - arr
+ - date
+```
+
+```javascript title="JavaScript"
+view(`arr`, {
+ description: `Annual Recurring Revenue`,
+ public: COMPILE_CONTEXT.security_context.is_finance,
+
+ cubes: [
+ {
+ join_path: revenue,
+ includes: [`arr`, `date`]
+ }
+ ]
+})
+```
+
+
+
+## Organizing members with folders
+
+When a view includes many fields, [folders][ref-view-folders] help organize
+them into logical groups. Cube supports both flat and nested folder
+structures:
+
+
+
+```yaml title="YAML"
+views:
+ - name: customers
+
+ cubes:
+ - join_path: users
+ includes: "*"
+
+ - join_path: users.orders
+ prefix: true
+ includes:
+ - status
+ - price
+ - count
+
+ folders:
+ - name: Personal Details
+ includes:
+ - name
+ - gender
+ - created_at
+
+ - name: Order Analytics
+ includes:
+ - orders_status
+ - orders_price
+ - orders_count
+```
+
+```javascript title="JavaScript"
+view(`customers`, {
+ cubes: [
+ {
+ join_path: `users`,
+ includes: `*`
+ },
+ {
+ join_path: `users.orders`,
+ prefix: true,
+ includes: [`status`, `price`, `count`]
+ }
+ ],
+
+ folders: [
+ {
+ name: `Personal Details`,
+ includes: [`name`, `gender`, `created_at`]
+ },
+ {
+ name: `Order Analytics`,
+ includes: [
+ `orders_status`,
+ `orders_price`,
+ `orders_count`
+ ]
+ }
+ ]
+})
+```
+
+
+
+Folders are displayed in supported [visualization tools][ref-viz-tools].
+Check [APIs & Integrations][ref-apis-support] for details on folder
+support. For tools that don't support nested folders, the structure is
+automatically flattened.
+
+## Next steps
+
+- See the [view reference][ref-view-reference] for the full list of
+ parameters
+- Learn about [access policies][ref-access-policies] to govern view access
+- Explore [AI context][ref-ai-context] to improve AI query accuracy
+- Use the [Semantic Model IDE][ref-ide] to develop views interactively
+
+[ref-cubes]: /docs/data-modeling/cubes
+[ref-view-reference]: /reference/data-modeling/view
+[ref-view-description]: /reference/data-modeling/view#description
+[ref-view-title]: /reference/data-modeling/view#title
+[ref-view-public]: /reference/data-modeling/view#public
+[ref-view-folders]: /reference/data-modeling/view#folders
+[ref-access-policies]: /reference/data-modeling/data-access-policies
+[ref-ai-context]: /docs/data-modeling/ai-context
+[ref-compile-context]: /docs/data-modeling/access-control/context
+[ref-explore]: /analytics/explore
+[ref-workbooks]: /analytics/workbooks
+[ref-embedding]: /docs/embedding
+[ref-ide]: /docs/data-modeling/data-model-ide
+[ref-viz-tools]: /admin/connect-to-data/visualization-tools
+[ref-apis-support]: /reference#data-modeling
+[wiki-dry]: https://en.wikipedia.org/wiki/Don%27t_repeat_yourself
diff --git a/docs-mintlify/docs/getting-started/cloud/create-data-model.mdx b/docs-mintlify/docs/getting-started/cloud/create-data-model.mdx
index 59739c097d5b4..1c125c2de57a2 100644
--- a/docs-mintlify/docs/getting-started/cloud/create-data-model.mdx
+++ b/docs-mintlify/docs/getting-started/cloud/create-data-model.mdx
@@ -109,7 +109,7 @@ within the `measures` block.
```yaml
- name: completed_percentage
type: number
- sql: "(100.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
+ sql: "(1.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
format: percent
```
@@ -156,7 +156,7 @@ cubes:
- name: completed_percentage
type: number
- sql: "(100.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
+ sql: "(1.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
format: percent
```
diff --git a/docs-mintlify/docs/integrations/google-sheets.mdx b/docs-mintlify/docs/integrations/google-sheets.mdx
index 9ca9b7c7e858c..c655c22f361ba 100644
--- a/docs-mintlify/docs/integrations/google-sheets.mdx
+++ b/docs-mintlify/docs/integrations/google-sheets.mdx
@@ -122,7 +122,7 @@ in Cube Cloud.
[link-google-sheets]: https://workspace.google.com/products/sheets/
[link-marketplace-listing]: https://workspace.google.com/u/0/marketplace/app/cube_cloud_for_sheets/641460343379
[ref-playground]: /docs/workspace/playground
-[ref-views]: /docs/data-modeling/concepts#views
+[ref-views]: /docs/data-modeling/views
[ref-pre-aggs]: /docs/pre-aggregations/using-pre-aggregations
[ref-sql-api-enabled]: /reference/sql-api#cube-cloud
[ref-saved-reports]: /docs/workspace/saved-reports
\ No newline at end of file
diff --git a/docs-mintlify/docs/integrations/microsoft-excel.mdx b/docs-mintlify/docs/integrations/microsoft-excel.mdx
index 74b606280b751..06d04bed1ec21 100644
--- a/docs-mintlify/docs/integrations/microsoft-excel.mdx
+++ b/docs-mintlify/docs/integrations/microsoft-excel.mdx
@@ -130,7 +130,7 @@ in Cube Cloud.
[ref-excel]: /admin/connect-to-data/visualization-tools/excel
[link-pivottable]: https://support.microsoft.com/en-us/office/create-a-pivottable-to-analyze-worksheet-data-a9a84538-bfe9-40a9-a8e9-f99134456576
[ref-playground]: /docs/workspace/playground
-[ref-views]: /docs/data-modeling/concepts#views
+[ref-views]: /docs/data-modeling/views
[ref-pre-aggs]: /docs/pre-aggregations/using-pre-aggregations
[ref-sql-api-enabled]: /reference/sql-api#cube-cloud
[link-excel-addins]: https://support.microsoft.com/en-us/office/add-or-remove-add-ins-in-excel-0af570c4-5cf3-4fa9-9b88-403625a0b460
diff --git a/docs-mintlify/docs/pre-aggregations/matching-pre-aggregations.mdx b/docs-mintlify/docs/pre-aggregations/matching-pre-aggregations.mdx
index 21aa72aed11d0..10f3f99c03259 100644
--- a/docs-mintlify/docs/pre-aggregations/matching-pre-aggregations.mdx
+++ b/docs-mintlify/docs/pre-aggregations/matching-pre-aggregations.mdx
@@ -131,8 +131,8 @@ configuration option.
[ref-rollup-only-mode]: /docs/pre-aggregations/using-pre-aggregations#rollup-only-mode
[ref-schema-joins-rel]: /reference/data-modeling/joins#relationship
[wiki-gcd]: https://en.wikipedia.org/wiki/Greatest_common_divisor
-[ref-measure-additivity]: /docs/data-modeling/concepts#measure-additivity
-[ref-leaf-measures]: /docs/data-modeling/concepts#leaf-measures
+[ref-measure-additivity]: /reference/data-modeling/measures#type
+[ref-leaf-measures]: /reference/data-modeling/measures#type
[ref-calculated-measures]: /docs/data-modeling/overview#4-using-calculated-measures
[ref-non-strict-date-range-match]: /reference/data-modeling/pre-aggregations#allow_non_strict_date_range_match
[ref-non-additive-recipe]: /recipes/pre-aggregations/non-additivity
@@ -140,4 +140,4 @@ configuration option.
[ref-ungrouped-queries]: /reference/queries#ungrouped-query
[ref-primary-key]: /reference/data-modeling/dimensions#primary_key
[ref-custom-granularity]: /reference/data-modeling/dimensions#granularities
-[ref-views]: /docs/data-modeling/concepts#views
\ No newline at end of file
+[ref-views]: /docs/data-modeling/views
\ No newline at end of file
diff --git a/docs-mintlify/recipes/data-modeling/cohort-retention.mdx b/docs-mintlify/recipes/data-modeling/cohort-retention.mdx
index 4a66106a37678..28cfd4fd63db0 100644
--- a/docs-mintlify/recipes/data-modeling/cohort-retention.mdx
+++ b/docs-mintlify/recipes/data-modeling/cohort-retention.mdx
@@ -139,7 +139,7 @@ cubes:
- users.email
- name: percentage_of_active
- sql: "100.0 * {total_active_count} / NULLIF({total_count}, 0)"
+ sql: "1.0 * {total_active_count} / NULLIF({total_count}, 0)"
type: number
format: percent
drill_members:
@@ -168,7 +168,7 @@ cube(`monthly_retention`, {
},
percentage_of_active: {
- sql: `100.0 * ${total_active_count} / NULLIF(${total_count}, 0)`,
+ sql: `1.0 * ${total_active_count} / NULLIF(${total_count}, 0)`,
type: `number`,
format: `percent`,
drill_members: [
diff --git a/docs-mintlify/recipes/data-modeling/custom-calendar.mdx b/docs-mintlify/recipes/data-modeling/custom-calendar.mdx
index 83feec451415b..a20e18698025c 100644
--- a/docs-mintlify/recipes/data-modeling/custom-calendar.mdx
+++ b/docs-mintlify/recipes/data-modeling/custom-calendar.mdx
@@ -222,5 +222,5 @@ Querying this data modal would yield the following result:
[link-454-official-calendar]: https://2fb5c46100c1b71985e2-011e70369171d43105aff38e48482379.ssl.cf1.rackcdn.com/4-5-4%20calendar/3-Year-Calendar-5-27.pdf
[ref-custom-granularities]: /reference/data-modeling/dimensions#granularities
[ref-custom-granularities-recipe]: /recipes/data-modeling/custom-granularity
-[ref-proxy-dimensions]: /docs/data-modeling/concepts/calculated-members#proxy-dimensions
+[ref-proxy-dimensions]: /docs/data-modeling/dimensions#proxy-dimensions
[ref-jinja-macro]: /docs/data-modeling/dynamic/jinja#macros
\ No newline at end of file
diff --git a/docs-mintlify/recipes/data-modeling/custom-granularity.mdx b/docs-mintlify/recipes/data-modeling/custom-granularity.mdx
index c9a74389e63df..dd633ee76754b 100644
--- a/docs-mintlify/recipes/data-modeling/custom-granularity.mdx
+++ b/docs-mintlify/recipes/data-modeling/custom-granularity.mdx
@@ -162,8 +162,8 @@ Querying this data modal would yield the following result:
[ref-custom-granularities]: /reference/data-modeling/dimensions#granularities
-[ref-default-granularities]: /docs/data-modeling/concepts#time-dimensions
+[ref-default-granularities]: /docs/data-modeling/dimensions#time-dimensions
[wiki-fiscal-year]: https://en.wikipedia.org/wiki/Fiscal_year
[ref-playground]: /docs/workspace/playground
[ref-sql-api]: /reference/sql-api
-[ref-proxy-granularity]: /docs/data-modeling/concepts/calculated-members#time-dimension-granularity
\ No newline at end of file
+[ref-proxy-granularity]: /docs/data-modeling/dimensions#time-dimension-granularity-references
\ No newline at end of file
diff --git a/docs-mintlify/recipes/data-modeling/event-analytics.mdx b/docs-mintlify/recipes/data-modeling/event-analytics.mdx
index 29a9e075b08dd..ba49b209a4311 100644
--- a/docs-mintlify/recipes/data-modeling/event-analytics.mdx
+++ b/docs-mintlify/recipes/data-modeling/event-analytics.mdx
@@ -410,7 +410,7 @@ cube("events", {
To determine the end of the session, we’re going to use a [subquery
-dimension](/docs/data-modeling/concepts/calculated-members#subquery-dimensions).
+dimension](/docs/data-modeling/dimensions#subquery-dimensions).
@@ -739,7 +739,7 @@ cubes:
- - sql: "{is_bounced} = 'True'
- name: bounce_rate
- sql: "100.00 * {bounced_count} / NULLIF({count}, 0)"
+ sql: "1.0 * {bounced_count} / NULLIF({count}, 0)"
type: number
format: percent
```
@@ -770,7 +770,7 @@ cube("sessions", {
},
bounce_rate: {
- sql: `100.00 * ${bounced_count} / NULLIF(${count}, 0)`,
+ sql: `1.0 * ${bounced_count} / NULLIF(${count}, 0)`,
type: `number`,
format: `percent`
}
@@ -846,7 +846,7 @@ cube("sessions", {
repeat_percent: {
description: `Percent of Repeat Sessions`,
- sql: `100.00 * ${repeat_count} / NULLIF(${count}, 0)`,
+ sql: `1.0 * ${repeat_count} / NULLIF(${count}, 0)`,
type: `number`,
format: `percent`
}
@@ -875,7 +875,7 @@ cubes:
- name: repeat_percent
description: Percent of Repeat Sessions
- sql: "100.00 * {repeat_count} / NULLIF({count}, 0)"
+ sql: "1.0 * {repeat_count} / NULLIF({count}, 0)"
type: number
format: percent
diff --git a/docs-mintlify/recipes/data-modeling/filtered-aggregates.mdx b/docs-mintlify/recipes/data-modeling/filtered-aggregates.mdx
index 03953aed8a348..6bb121ae07774 100644
--- a/docs-mintlify/recipes/data-modeling/filtered-aggregates.mdx
+++ b/docs-mintlify/recipes/data-modeling/filtered-aggregates.mdx
@@ -200,4 +200,4 @@ will show the ratio of the sales goal that has been achieved:
-[ref-subquery-dimension]: /docs/data-modeling/concepts/calculated-members#subquery-dimensions
\ No newline at end of file
+[ref-subquery-dimension]: /docs/data-modeling/dimensions#subquery-dimensions
\ No newline at end of file
diff --git a/docs-mintlify/recipes/data-modeling/nested-aggregates.mdx b/docs-mintlify/recipes/data-modeling/nested-aggregates.mdx
index 2d9c1253be9da..9176d64da4797 100644
--- a/docs-mintlify/recipes/data-modeling/nested-aggregates.mdx
+++ b/docs-mintlify/recipes/data-modeling/nested-aggregates.mdx
@@ -146,4 +146,4 @@ We can verify that it's correct by adding one more dimension to the query:
[ref-measures]: /reference/data-modeling/measures
[ref-cube]: /reference/data-modeling/cube
-[ref-subquery-dimension]: /docs/data-modeling/concepts/calculated-members#subquery-dimensions
\ No newline at end of file
+[ref-subquery-dimension]: /docs/data-modeling/dimensions#subquery-dimensions
\ No newline at end of file
diff --git a/docs-mintlify/recipes/data-modeling/period-over-period.mdx b/docs-mintlify/recipes/data-modeling/period-over-period.mdx
index 7e0178f5219bb..56d77893b80d5 100644
--- a/docs-mintlify/recipes/data-modeling/period-over-period.mdx
+++ b/docs-mintlify/recipes/data-modeling/period-over-period.mdx
@@ -148,8 +148,8 @@ Here's the result:
-[ref-multi-stage]: /docs/data-modeling/concepts/multi-stage-calculations
+[ref-multi-stage]: /docs/data-modeling/measures#multi-stage-measures
[ref-calculated-measure]: /docs/data-modeling/overview#4-using-calculated-measures
[ref-time-dimension-granularity]: /reference/rest-api/query-format#time-dimensions-format
[link-tesseract]: https://cube.dev/blog/introducing-next-generation-data-modeling-engine
-[link-time-shift]: /docs/data-modeling/concepts/multi-stage-calculations#time-shift
\ No newline at end of file
+[link-time-shift]: /docs/data-modeling/measures#time-shift
\ No newline at end of file
diff --git a/docs-mintlify/docs/data-modeling/concepts/polymorphic-cubes.mdx b/docs-mintlify/recipes/data-modeling/polymorphic-cubes.mdx
similarity index 97%
rename from docs-mintlify/docs/data-modeling/concepts/polymorphic-cubes.mdx
rename to docs-mintlify/recipes/data-modeling/polymorphic-cubes.mdx
index 594212cb70bce..70c20a8af7e16 100644
--- a/docs-mintlify/docs/data-modeling/concepts/polymorphic-cubes.mdx
+++ b/docs-mintlify/recipes/data-modeling/polymorphic-cubes.mdx
@@ -166,5 +166,5 @@ cube(`lessons`, {
-[ref-schema-advanced-extend]: /docs/data-modeling/concepts/code-reusability-extending-cubes
+[ref-schema-advanced-extend]: /docs/data-modeling/extending-cubes
[ref-schema-ref-cubes-extends]: /reference/data-modeling/cube#extends
\ No newline at end of file
diff --git a/docs-mintlify/recipes/data-modeling/using-dynamic-measures.mdx b/docs-mintlify/recipes/data-modeling/using-dynamic-measures.mdx
index 75ed985dd8399..eb03f8404d149 100644
--- a/docs-mintlify/recipes/data-modeling/using-dynamic-measures.mdx
+++ b/docs-mintlify/recipes/data-modeling/using-dynamic-measures.mdx
@@ -41,7 +41,7 @@ const createPercentageMeasure = (status) => ({
sql: (CUBE) =>
`ROUND(${CUBE[`total_${status}_orders`]}::NUMERIC / ${
CUBE.total_orders
- }::NUMERIC * 100.0, 2)`
+ }::NUMERIC, 2)`
}
})
@@ -90,4 +90,4 @@ or run it with the `docker-compose up` command. You'll see the result, including
queried data, in the console.
-[ref-measures]: /docs/data-modeling/concepts#measures
\ No newline at end of file
+[ref-measures]: /docs/data-modeling/measures
\ No newline at end of file
diff --git a/docs-mintlify/recipes/data-modeling/xirr.mdx b/docs-mintlify/recipes/data-modeling/xirr.mdx
index 4528a7487e4be..40b25f9364cb8 100644
--- a/docs-mintlify/recipes/data-modeling/xirr.mdx
+++ b/docs-mintlify/recipes/data-modeling/xirr.mdx
@@ -199,4 +199,4 @@ All queries above would yield the same result:
[ref-query-wpp]: /reference/queries#query-with-post-processing
[ref-query-regular]: /reference/queries#regular-query
[link-tesseract]: https://cube.dev/blog/introducing-next-generation-data-modeling-engine
-[ref-multi-stage-calculations]: /docs/data-modeling/concepts/multi-stage-calculations
\ No newline at end of file
+[ref-multi-stage-calculations]: /docs/data-modeling/measures#multi-stage-measures
\ No newline at end of file
diff --git a/docs-mintlify/recipes/pre-aggregations/non-additivity.mdx b/docs-mintlify/recipes/pre-aggregations/non-additivity.mdx
index 2e475b603f557..a0fcf1920b14e 100644
--- a/docs-mintlify/recipes/pre-aggregations/non-additivity.mdx
+++ b/docs-mintlify/recipes/pre-aggregations/non-additivity.mdx
@@ -248,4 +248,4 @@ queried data, in the console.
[ref-percentile-recipe]: /recipes/data-modeling/percentiles
-[ref-calculated-measures]: /docs/data-modeling/concepts/calculated-members#calculated-measures
\ No newline at end of file
+[ref-calculated-measures]: /docs/data-modeling/measures#calculated-measures
\ No newline at end of file
diff --git a/docs-mintlify/reference/configuration/environment-variables.mdx b/docs-mintlify/reference/configuration/environment-variables.mdx
index 89224526bdb50..929a8a2cdb2ad 100644
--- a/docs-mintlify/reference/configuration/environment-variables.mdx
+++ b/docs-mintlify/reference/configuration/environment-variables.mdx
@@ -1898,7 +1898,7 @@ The port for a Cube deployment to listen to API connections on.
[mysql-server-tz-support]: https://dev.mysql.com/doc/refman/8.4/en/time-zone-support.html
[ref-schema-ref-preagg-allownonstrict]: /reference/data-modeling/pre-aggregations#allow_non_strict_date_range_match
[link-tesseract]: https://cube.dev/blog/introducing-next-generation-data-modeling-engine
-[ref-multi-stage-calculations]: /docs/data-modeling/concepts/multi-stage-calculations
+[ref-multi-stage-calculations]: /docs/data-modeling/measures#multi-stage-measures
[ref-folders]: /reference/data-modeling/view#folders
[ref-dataviz-tools]: /admin/connect-to-data/visualization-tools
[ref-context-to-app-id]: /reference/configuration/config#context_to_app_id
diff --git a/docs-mintlify/reference/core-data-apis/dax-api/index.mdx b/docs-mintlify/reference/core-data-apis/dax-api/index.mdx
index 24488b81ab11d..ea7f385ccb72c 100644
--- a/docs-mintlify/reference/core-data-apis/dax-api/index.mdx
+++ b/docs-mintlify/reference/core-data-apis/dax-api/index.mdx
@@ -78,8 +78,8 @@ The DAX API only exposes [views][ref-views], not cubes.
[link-dax]: https://learn.microsoft.com/en-us/dax/
[ref-sql-api]: /reference/sql-api
[ref-ref-dax-api]: /reference/dax-api/reference
-[ref-views]: /docs/data-modeling/concepts#views
-[ref-time-dimensions]: /docs/data-modeling/concepts#time-dimensions
+[ref-views]: /docs/data-modeling/views
+[ref-time-dimensions]: /docs/data-modeling/dimensions#time-dimensions
[ref-kerberos]: /docs/integrations/power-bi/kerberos
[ref-ntlm]: /docs/integrations/power-bi/ntlm
[ref-power-bi]: /admin/connect-to-data/visualization-tools/powerbi
\ No newline at end of file
diff --git a/docs-mintlify/reference/core-data-apis/mdx-api.mdx b/docs-mintlify/reference/core-data-apis/mdx-api.mdx
index 1920c2dcf04e1..644aae2934ede 100644
--- a/docs-mintlify/reference/core-data-apis/mdx-api.mdx
+++ b/docs-mintlify/reference/core-data-apis/mdx-api.mdx
@@ -226,7 +226,7 @@ Authentication and authorization work the same as for the [SQL API](/reference/s
[ref-cube-cloud-for-excel]: /docs/integrations/microsoft-excel
[ref-hierarchies]: /reference/data-modeling/hierarchies
[ref-folders]: /reference/data-modeling/view#folders
-[ref-views]: /docs/data-modeling/concepts#views
+[ref-views]: /docs/data-modeling/views
[ref-deployment]: /docs/deployment/cloud/deployments
[ref-pre-aggregations]: /docs/pre-aggregations/using-pre-aggregations
[ref-rollup-only-mode]: /docs/pre-aggregations/using-pre-aggregations#rollup-only-mode
diff --git a/docs-mintlify/reference/core-data-apis/rest-api/query-format.mdx b/docs-mintlify/reference/core-data-apis/rest-api/query-format.mdx
index 9d8e7520e66b8..652b51811b6a1 100644
--- a/docs-mintlify/reference/core-data-apis/rest-api/query-format.mdx
+++ b/docs-mintlify/reference/core-data-apis/rest-api/query-format.mdx
@@ -687,7 +687,7 @@ refer to its documentation for more examples.
[ref-total-query]: /reference/queries#total-query
[ref-ungrouped-query]: /reference/queries#ungrouped-query
[ref-default-order]: /reference/queries#order
-[ref-default-granularities]: /docs/data-modeling/concepts#time-dimensions
+[ref-default-granularities]: /docs/data-modeling/dimensions#time-dimensions
[ref-custom-granularities]: /reference/data-modeling/dimensions#granularities
[wiki-iso-8601]: https://en.wikipedia.org/wiki/ISO_8601
-[ref-join-hints]: /docs/data-modeling/concepts/working-with-joins#join-hints
\ No newline at end of file
+[ref-join-hints]: /docs/data-modeling/joins#join-hints
\ No newline at end of file
diff --git a/docs-mintlify/reference/core-data-apis/sql-api/joins.mdx b/docs-mintlify/reference/core-data-apis/sql-api/joins.mdx
index 3fa946a648cc5..0b25778f14b3a 100644
--- a/docs-mintlify/reference/core-data-apis/sql-api/joins.mdx
+++ b/docs-mintlify/reference/core-data-apis/sql-api/joins.mdx
@@ -208,6 +208,6 @@ Please note that, even if `product_description` is in the inner selection, it is
evaluated in the final query as it isn't used in any way.
-[ref-views]: /docs/data-modeling/concepts#views
-[ref-join-paths]: /docs/data-modeling/concepts/working-with-joins#join-paths
-[ref-join-hints]: /docs/data-modeling/concepts/working-with-joins#join-hints
\ No newline at end of file
+[ref-views]: /docs/data-modeling/views
+[ref-join-paths]: /docs/data-modeling/joins#join-paths
+[ref-join-hints]: /docs/data-modeling/joins#join-hints
\ No newline at end of file
diff --git a/docs-mintlify/reference/core-data-apis/sql-api/query-format.mdx b/docs-mintlify/reference/core-data-apis/sql-api/query-format.mdx
index 4ffb6d7cc23e6..6dc2a5ab976c2 100644
--- a/docs-mintlify/reference/core-data-apis/sql-api/query-format.mdx
+++ b/docs-mintlify/reference/core-data-apis/sql-api/query-format.mdx
@@ -256,7 +256,7 @@ cubes:
- name: completed_percentage
type: number
- sql: "(100.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
+ sql: "(1.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
format: percent
```
diff --git a/docs-mintlify/reference/data-modeling/cube.mdx b/docs-mintlify/reference/data-modeling/cube.mdx
index af1c2a3f7a370..3f0ffa1c0031c 100644
--- a/docs-mintlify/reference/data-modeling/cube.mdx
+++ b/docs-mintlify/reference/data-modeling/cube.mdx
@@ -670,9 +670,9 @@ The `access_policy` parameter is used to configure [access policies][ref-ref-dap
[ref-ref-pre-aggs]: /reference/data-modeling/pre-aggregations
[ref-ref-dap]: /reference/data-modeling/data-access-policies
[ref-syntax-cube-sql]: /docs/data-modeling/syntax#cubesql-function
-[ref-extension]: /docs/data-modeling/concepts/code-reusability-extending-cubes
+[ref-extension]: /docs/data-modeling/extending-cubes
[ref-calendar-cubes]: /docs/data-modeling/concepts/calendar-cubes
[ref-calendar-cubes-time-shifts]: /docs/data-modeling/concepts/calendar-cubes#time-shifts
[ref-calendar-cubes-granularities]: /docs/data-modeling/concepts/calendar-cubes#granularities
-[ref-time-dimensions]: /docs/data-modeling/concepts#time-dimensions
-[ref-time-shift]: /docs/data-modeling/concepts/multi-stage-calculations#time-shift
\ No newline at end of file
+[ref-time-dimensions]: /docs/data-modeling/dimensions#time-dimensions
+[ref-time-shift]: /docs/data-modeling/measures#time-shift
\ No newline at end of file
diff --git a/docs-mintlify/reference/data-modeling/dimensions.mdx b/docs-mintlify/reference/data-modeling/dimensions.mdx
index a9fa7e5437538..5055845827ec3 100644
--- a/docs-mintlify/reference/data-modeling/dimensions.mdx
+++ b/docs-mintlify/reference/data-modeling/dimensions.mdx
@@ -1007,6 +1007,7 @@ cube(`orders`, {
+{/*
#### Calendar cubes
When the `granularities` parameter is used in time dimensions within [calendar
@@ -1091,6 +1092,7 @@ cube(`fiscal_calendar`, {
```
+*/}
### `time_shift`
@@ -1198,7 +1200,7 @@ cube(`fiscal_calendar`, {
[ref-ai-context]: /docs/data-modeling/ai-context
[ref-ref-cubes]: /reference/data-modeling/cube
[ref-schema-ref-joins]: /reference/data-modeling/joins
-[ref-subquery]: /docs/data-modeling/concepts/calculated-members#subquery-dimensions
+[ref-subquery]: /docs/data-modeling/dimensions#subquery-dimensions
[self-subquery]: #sub-query
[ref-naming]: /docs/data-modeling/syntax#naming
[ref-playground]: /docs/workspace/playground
@@ -1209,7 +1211,7 @@ cube(`fiscal_calendar`, {
[ref-ref-hierarchies]: /reference/data-modeling/hierarchies
[ref-data-sources]: /admin/connect-to-data/data-sources
[ref-calendar-cubes]: /docs/data-modeling/concepts/calendar-cubes
-[ref-time-shift]: /docs/data-modeling/concepts/multi-stage-calculations#time-shift
+[ref-time-shift]: /docs/data-modeling/measures#time-shift
[ref-cube-calendar]: /reference/data-modeling/cube#calendar
[ref-measure-time-shift]: /reference/data-modeling/measures#time_shift
[ref-data-masking]: /docs/data-modeling/access-control/data-access-policies#data-masking
diff --git a/docs-mintlify/reference/data-modeling/joins.mdx b/docs-mintlify/reference/data-modeling/joins.mdx
index 0931b6bd053ba..c2fba4bff3832 100644
--- a/docs-mintlify/reference/data-modeling/joins.mdx
+++ b/docs-mintlify/reference/data-modeling/joins.mdx
@@ -663,7 +663,7 @@ Please use views to address join predictability and stability.
[ref-ref-cubes]: /reference/data-modeling/cube
[ref-restapi-query-filter-op-set]: /reference/rest-api/query-format#set
-[ref-schema-fundamentals-join-dir]: /docs/data-modeling/concepts/working-with-joins#direction-of-joins
+[ref-schema-fundamentals-join-dir]: /docs/data-modeling/joins#direction-of-joins
[ref-schema-cube-sql]: /reference/data-modeling/cube#sql
[ref-schema-data-blenging]: /docs/data-modeling/concepts/data-blending#data-blending
[ref-naming]: /docs/data-modeling/syntax#naming
diff --git a/docs-mintlify/reference/data-modeling/measures.mdx b/docs-mintlify/reference/data-modeling/measures.mdx
index 5fb809ad35563..8c78673af880b 100644
--- a/docs-mintlify/reference/data-modeling/measures.mdx
+++ b/docs-mintlify/reference/data-modeling/measures.mdx
@@ -1429,15 +1429,15 @@ cube(`orders`, {
[ref-naming]: /docs/data-modeling/syntax#naming
[ref-playground]: /docs/workspace/playground
[ref-apis]: /reference
-[ref-rolling-window]: /docs/data-modeling/concepts/multi-stage-calculations#rolling-window
+[ref-rolling-window]: /docs/data-modeling/measures#rolling-windows
[link-tesseract]: https://cube.dev/blog/introducing-next-generation-data-modeling-engine
-[ref-multi-stage]: /docs/data-modeling/concepts/multi-stage-calculations
-[ref-time-shift]: /docs/data-modeling/concepts/multi-stage-calculations#time-shift
-[ref-nested-aggregate]: /docs/data-modeling/concepts/multi-stage-calculations#nested-aggregate
+[ref-multi-stage]: /docs/data-modeling/measures#multi-stage-measures
+[ref-time-shift]: /docs/data-modeling/measures#time-shift
+[ref-nested-aggregate]: /docs/data-modeling/measures#nested-aggregates
[ref-calendar-cubes]: /docs/data-modeling/concepts/calendar-cubes
[ref-switch-dimensions]: /reference/data-modeling/dimensions#type
[ref-data-masking]: /docs/data-modeling/access-control/data-access-policies#data-masking
[link-d3-format]: https://d3js.org/d3-format
[link-iso-4217]: https://en.wikipedia.org/wiki/ISO_4217
-[ref-calculated-measures]: /docs/data-modeling/concepts/calculated-members#calculated-measures
+[ref-calculated-measures]: /docs/data-modeling/measures#calculated-measures
[ref-schema-ref-preaggs-rollup]: /reference/data-modeling/pre-aggregations#rollup
\ No newline at end of file
diff --git a/docs-mintlify/reference/data-modeling/view.mdx b/docs-mintlify/reference/data-modeling/view.mdx
index fe8efb651c984..bc163c6b94f58 100644
--- a/docs-mintlify/reference/data-modeling/view.mdx
+++ b/docs-mintlify/reference/data-modeling/view.mdx
@@ -660,7 +660,7 @@ The `access_policy` parameter is used to configure [access policies][ref-ref-dap
[ref-apis-support]: /reference#data-modeling
[ref-playground]: /docs/workspace/playground#viewing-the-data-model
[ref-viz-tools]: /admin/connect-to-data/visualization-tools
-[ref-extension]: /docs/data-modeling/concepts/code-reusability-extending-cubes
+[ref-extension]: /docs/data-modeling/extending-cubes
[ref-dim-name]: /reference/data-modeling/dimensions#name
[ref-dim-title]: /reference/data-modeling/dimensions#title
[ref-dim-description]: /reference/data-modeling/dimensions#description
diff --git a/docs/content/product/apis-integrations/core-data-apis/sql-api/query-format.mdx b/docs/content/product/apis-integrations/core-data-apis/sql-api/query-format.mdx
index e0549e94196b3..bb77c7cfbf373 100644
--- a/docs/content/product/apis-integrations/core-data-apis/sql-api/query-format.mdx
+++ b/docs/content/product/apis-integrations/core-data-apis/sql-api/query-format.mdx
@@ -256,7 +256,7 @@ cubes:
- name: completed_percentage
type: number
- sql: "(100.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
+ sql: "(1.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
format: percent
```
diff --git a/docs/content/product/data-modeling/concepts/calculated-members.mdx b/docs/content/product/data-modeling/concepts/calculated-members.mdx
index 9c4c71eb729fd..071557ef3ec79 100644
--- a/docs/content/product/data-modeling/concepts/calculated-members.mdx
+++ b/docs/content/product/data-modeling/concepts/calculated-members.mdx
@@ -158,7 +158,7 @@ cube(`users`, {
},
purchases_to_users_ratio: {
- sql: `100.0 * ${orders.purchases} / ${CUBE.count}`,
+ sql: `1.0 * ${orders.purchases} / ${CUBE.count}`,
type: `number`,
format: `percent`
}
diff --git a/docs/content/product/data-modeling/overview.mdx b/docs/content/product/data-modeling/overview.mdx
index bf9ac86d5e32a..d8a091e313cb0 100644
--- a/docs/content/product/data-modeling/overview.mdx
+++ b/docs/content/product/data-modeling/overview.mdx
@@ -283,7 +283,7 @@ measure via an API, the following SQL will be generated:
```sql
SELECT
- 100.0 * COUNT(
+ 1.0 * COUNT(
CASE WHEN (users.paying = 'true') THEN users.id END
) / COUNT(users.id) AS paying_percentage
FROM users
diff --git a/docs/content/product/data-modeling/recipes/cohort-retention.mdx b/docs/content/product/data-modeling/recipes/cohort-retention.mdx
index d298ba8ad9fe6..01f4b9279b770 100644
--- a/docs/content/product/data-modeling/recipes/cohort-retention.mdx
+++ b/docs/content/product/data-modeling/recipes/cohort-retention.mdx
@@ -139,7 +139,7 @@ cubes:
- users.email
- name: percentage_of_active
- sql: "100.0 * {total_active_count} / NULLIF({total_count}, 0)"
+ sql: "1.0 * {total_active_count} / NULLIF({total_count}, 0)"
type: number
format: percent
drill_members:
@@ -168,7 +168,7 @@ cube(`monthly_retention`, {
},
percentage_of_active: {
- sql: `100.0 * ${total_active_count} / NULLIF(${total_count}, 0)`,
+ sql: `1.0 * ${total_active_count} / NULLIF(${total_count}, 0)`,
type: `number`,
format: `percent`,
drill_members: [
diff --git a/docs/content/product/data-modeling/recipes/event-analytics.mdx b/docs/content/product/data-modeling/recipes/event-analytics.mdx
index e047accf8136d..9f2f5cf8745aa 100644
--- a/docs/content/product/data-modeling/recipes/event-analytics.mdx
+++ b/docs/content/product/data-modeling/recipes/event-analytics.mdx
@@ -742,7 +742,7 @@ cube("sessions", {
},
bounce_rate: {
- sql: `100.00 * ${bounced_count} / NULLIF(${count}, 0)`,
+ sql: `1.0 * ${bounced_count} / NULLIF(${count}, 0)`,
type: `number`,
format: `percent`
}
@@ -770,7 +770,7 @@ cubes:
- - sql: "{is_bounced} = 'True'
- name: bounce_rate
- sql: "100.00 * {bounced_count} / NULLIF({count}, 0)"
+ sql: "1.0 * {bounced_count} / NULLIF({count}, 0)"
type: number
format: percent
```
@@ -843,7 +843,7 @@ cube("sessions", {
repeat_percent: {
description: `Percent of Repeat Sessions`,
- sql: `100.00 * ${repeat_count} / NULLIF(${count}, 0)`,
+ sql: `1.0 * ${repeat_count} / NULLIF(${count}, 0)`,
type: `number`,
format: `percent`
}
@@ -872,7 +872,7 @@ cubes:
- name: repeat_percent
description: Percent of Repeat Sessions
- sql: "100.00 * {repeat_count} / NULLIF({count}, 0)"
+ sql: "1.0 * {repeat_count} / NULLIF({count}, 0)"
type: number
format: percent
diff --git a/docs/content/product/data-modeling/recipes/using-dynamic-measures.mdx b/docs/content/product/data-modeling/recipes/using-dynamic-measures.mdx
index a4e4c307857dd..5e3237d20d016 100644
--- a/docs/content/product/data-modeling/recipes/using-dynamic-measures.mdx
+++ b/docs/content/product/data-modeling/recipes/using-dynamic-measures.mdx
@@ -38,7 +38,7 @@ const createPercentageMeasure = (status) => ({
sql: (CUBE) =>
`ROUND(${CUBE[`total_${status}_orders`]}::NUMERIC / ${
CUBE.total_orders
- }::NUMERIC * 100.0, 2)`
+ }::NUMERIC, 2)`
}
})
diff --git a/docs/content/product/getting-started/cloud/create-data-model.mdx b/docs/content/product/getting-started/cloud/create-data-model.mdx
index c591c8b988826..79793dd372823 100644
--- a/docs/content/product/getting-started/cloud/create-data-model.mdx
+++ b/docs/content/product/getting-started/cloud/create-data-model.mdx
@@ -107,7 +107,7 @@ within the `measures` block.
```yaml
- name: completed_percentage
type: number
- sql: "(100.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
+ sql: "(1.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
format: percent
```
@@ -154,7 +154,7 @@ cubes:
- name: completed_percentage
type: number
- sql: "(100.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
+ sql: "(1.0 * {CUBE.completed_count} / NULLIF({CUBE.count}, 0))"
format: percent
```
diff --git a/examples/recipes/active-users/schema/ActiveUsers.js b/examples/recipes/active-users/schema/ActiveUsers.js
index 2e87fc5d4a6e6..b455206fb0c1d 100644
--- a/examples/recipes/active-users/schema/ActiveUsers.js
+++ b/examples/recipes/active-users/schema/ActiveUsers.js
@@ -31,7 +31,7 @@ cube(`ActiveUsers`, {
wauToMau: {
title: `WAU to MAU`,
- sql: `100.000 * ${weeklyActiveUsers} / NULLIF(${monthlyActiveUsers}, 0)`,
+ sql: `1.0 * ${weeklyActiveUsers} / NULLIF(${monthlyActiveUsers}, 0)`,
type: `number`,
format: `percent`,
},
diff --git a/examples/recipes/referencing-dynamic-measures/schema/Orders.js b/examples/recipes/referencing-dynamic-measures/schema/Orders.js
index 56363fe9208e8..dc960ca1b39f2 100644
--- a/examples/recipes/referencing-dynamic-measures/schema/Orders.js
+++ b/examples/recipes/referencing-dynamic-measures/schema/Orders.js
@@ -22,7 +22,7 @@ const createPercentageMeasure = (status) => ({
format: `percent`,
title: `Percentage of ${status} orders`,
sql: (CUBE) =>
- `ROUND(${CUBE[`Total_${status}_orders`]}::numeric / ${CUBE.totalOrders}::numeric * 100.0, 2)`,
+ `ROUND(${CUBE[`Total_${status}_orders`]}::numeric / ${CUBE.totalOrders}::numeric, 2)`,
},
});
diff --git a/packages/cubejs-schema-compiler/src/extensions/Funnels.ts b/packages/cubejs-schema-compiler/src/extensions/Funnels.ts
index d5a8d5bce714b..b24861ef9d12e 100644
--- a/packages/cubejs-schema-compiler/src/extensions/Funnels.ts
+++ b/packages/cubejs-schema-compiler/src/extensions/Funnels.ts
@@ -45,7 +45,7 @@ ${eventJoin.join('\nLEFT JOIN\n')}
shown: false
},
conversionsPercent: {
- sql: (conversions, firstStepConversions) => `CASE WHEN ${firstStepConversions} > 0 THEN 100.0 * ${conversions} / ${firstStepConversions} ELSE NULL END`,
+ sql: (conversions, firstStepConversions) => `CASE WHEN ${firstStepConversions} > 0 THEN 1.0 * ${conversions} / ${firstStepConversions} ELSE NULL END`,
type: 'number',
format: 'percent'
}
diff --git a/packages/cubejs-schema-compiler/test/unit/fixtures/calendar_orders.yml b/packages/cubejs-schema-compiler/test/unit/fixtures/calendar_orders.yml
index c0ffd1e03c45f..6710462892c44 100644
--- a/packages/cubejs-schema-compiler/test/unit/fixtures/calendar_orders.yml
+++ b/packages/cubejs-schema-compiler/test/unit/fixtures/calendar_orders.yml
@@ -59,7 +59,7 @@ cubes:
- sql: "{CUBE}.status = 'completed'"
- name: completed_percentage
- sql: "({completed_count} / NULLIF({count}, 0)) * 100.0"
+ sql: "1.0 * {completed_count} / NULLIF({count}, 0)"
type: number
format: percent